Data-projects-with-R-and-GitHub
Ziyi’s Project Description: Surprisal-Based Comparison of Human and LLM Language Generation
1. Background
Recent research in psycholinguistics suggests that language comprehension is strongly influenced by prediction. When reading or listening to a sentence, humans continuously generate expectations about upcoming words.
A key concept used to model this process is surprisal. Surprisal measures how unexpected a word is given its context. It is defined as:
| Surprisal = -log(P(word | context)) |
Higher probability → lower surprisal
Lower probability → higher surprisal
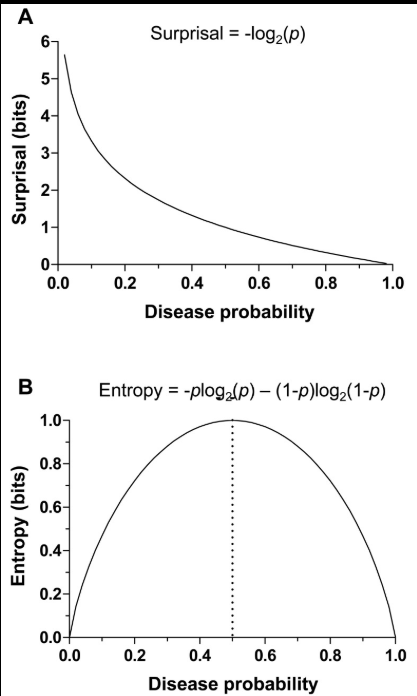
This means that words that are highly predictable have low surprisal, while unexpected words have high surprisal.
The surprisal theory of sentence processing was formalized by Levy (2008), who proposed that the difficulty of processing a word in a sentence is proportional to its surprisal value. Later work by Smith & Levy (2013) further demonstrated that reading time increases linearly with surprisal.
In recent years, Large Language Models (LLMs) such as GPT models have become powerful tools for generating language. However, it is still an open research question whether the statistical properties of language generated by LLMs resemble those of human language production.
This project explores this question by comparing surprisal values of human-generated and LLM-generated sentence continuations under controlled contexts.
2. Research Question
The main research question of this project is:
Do human speakers and Large Language Models generate language with similar surprisal patterns under the same contextual conditions?
More specifically, the project investigates:
- whether different generators (human vs LLMs) produce different surprisal values
- how surprisal values change across different contextual conditions
- whether LLM-generated continuations resemble human language in terms of predictability
3. Dataset (by folder)
3.1 LLMs Processed Data
This folder contains sentences generated by two LLM generators under different path conditions.
3.2 Processed final data (main focus)
The dataset used in this project was collected in the course “Verarbeitung kreativer Sprache mit ChatGPT” in the previous semester.
The data contains sentence continuations generated by:
- GPT-3.5-turbo-16k (under 3 different generate conditions)
- GPT-5.2-chat-latest (under 3 different generate conditions)
- 4 Human participants
Example structure of the dataset:
| item | context | condition | generator | surprisal |
|---|---|---|---|---|
| 1 | high | RA | GPT-3.5 | 6.32 |
| 2 | high | EW | human | 5.12 |
| 3 | medium | OH | GPT-5.2 | 7.41 |
The dataset is structured at the token level, meaning that each row corresponds to a single token within a sentence rather than a full item.
Each item (i.e., sentence continuation) consists of multiple tokens, and surprisal values are computed per token.
The dataset includes the following variables: (you can find the final dataset in ZiyiWang/data/Processed_final_data) - item: sentence ID - token: token index within the sentence - surprisal: surprisal value per token - generator: model or human source - context: contextual constraint (high vs. medium) - condition: particle condition (EW, RA, none)
In this project, context and condition are treated as independent variables:
- context refers to the predictability of the preceding context (high vs. medium)
- condition refers to the presence or absence of specific particles (EW, RA, none), they signal different types of information in a sentence.
Together, they form a 2 × 3 experimental design.
3.3 original pure data
Here is an initial data table containing the initial conditions, contextual settings and the opening sentence.
3.4 surprisal calculation
This folder contains the surprisal values for the tokens in each sentence of the continuations generated by each generator using llm_generate.py.
4. Data Processing Plan
Before the analysis, the dataset will be cleaned and standardized.
The main preprocessing steps include:
1. Handling missing data
It is evident that the human participants were only tasked with formulating responses to the 34 items. Consequently, in order to facilitate a more robust comparison between human performance and that of LLMs, it is recommended that the values for items 13 and 28 be removed from the analysis. Which not a problem for the analyse between LLMs generators.
2. Aggregating surprisal values
-
For each generator (human or LLM), the mean surprisal value per subject and condition will be calculated.This method is the most straightforward.
-
Weakness: if compare the average surprise, it will make the local surprise information less obvious.
-
This step ensures that the analysis is based on comparable aggregated statistics.
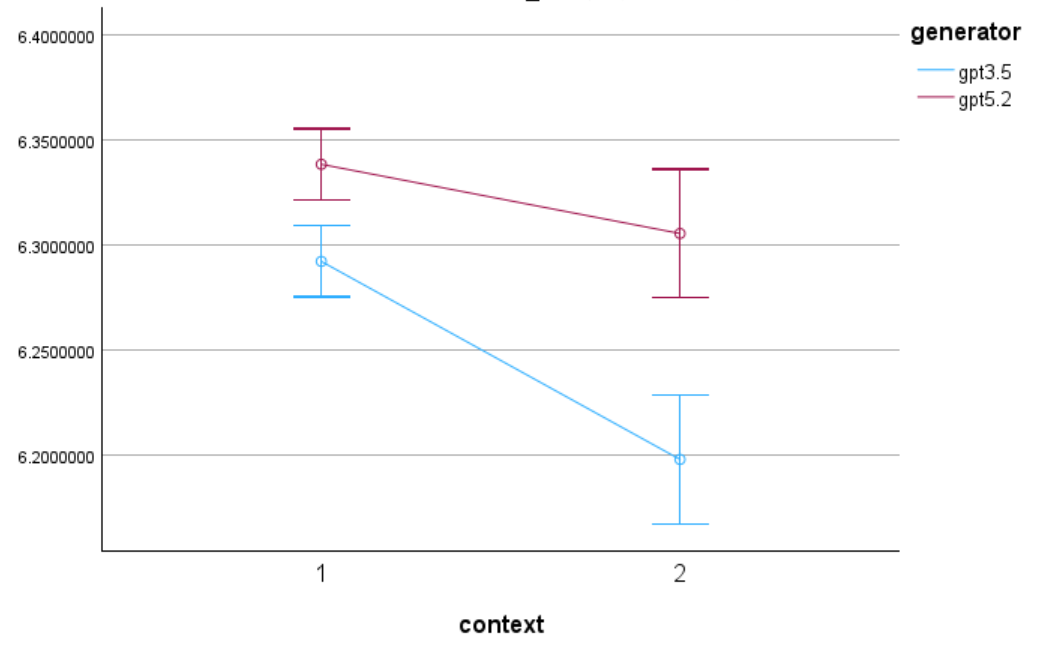
5. Visualization Plan
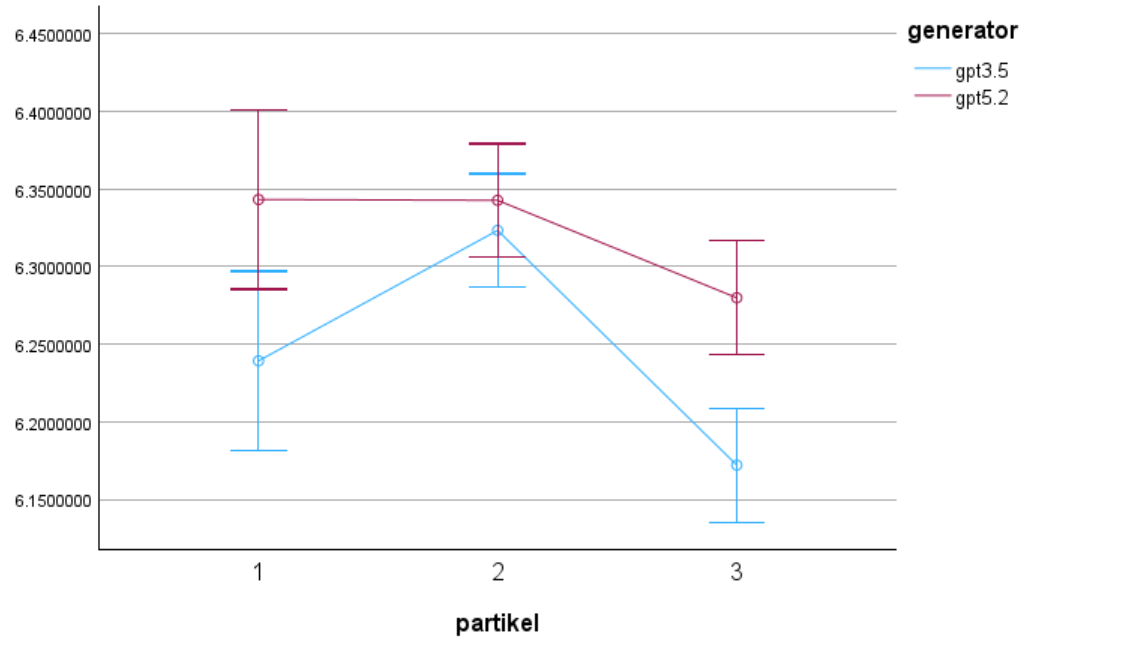
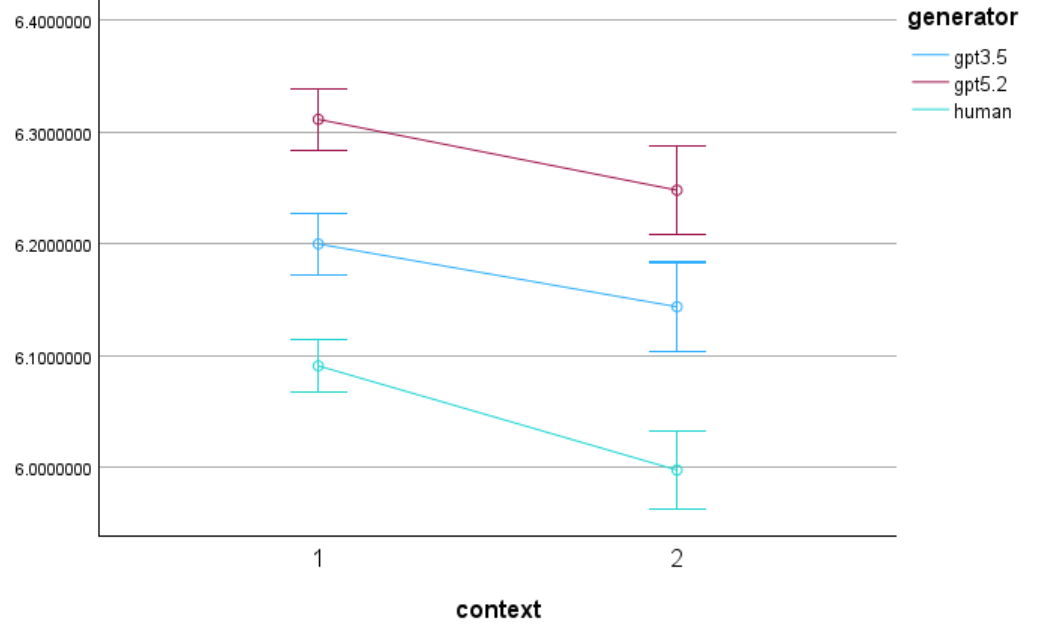
To compare surprisal patterns across generators, the results will be visualized using line plots.
The visualization will show:
x-axis: context condition
y-axis: mean surprisal value
lines: different generators (human vs LLMs)
This plot will allow us to observe whether human-generated language and LLM-generated language show similar or different surprisal patterns across contexts.
6. Expected Contribution
-
Please compare under which context the difference in surprisal values between different generators is greatest, and under which context it is smallest.
-
Under which conditions is the difference in surprisal values between different LLMs-generators greatest?
References
Levy, R. (2008). Expectation-based syntactic comprehension. Cognition, 106(3), 1126–1177.
Smith, N. J., & Levy, R. (2013). The effect of word predictability on reading time is logarithmic. Cognition, 128(3), 302–319.
Lu, Jeuring, Gatt (2025). Evaluating LLM-Generated Versus Human-Authored Responses in Role-Play Dialogues.