Digitale Daten
Zuletzt aktualisiert am 2025-08-21 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie wird … gespeichert?
- Was gibt es für Probleme?
- Worauf muss man achten?
Ziele
- Verständnis wie verschiedene Informationstypen digital repräsentiert sind
- Wissen um die Grenzen und Schwierigkeiten von Informationsspeicherung
- Lösungsstrategien für häufige Daten(import)probleme
Grundlegende Formen von Information sind Texte, Zahlen, Zeiten, Farben (für Bild und Video) und Audio. Wenn wir an diese denken, haben wir meistens eine Vorstellung von einem physischen Medium wie einem Blatt Papier etc., auf dem diese gespeichert sind. Eine solche Form der Informationsspeicherung wird als analoge Speicherung bezeichnet.
In Computern wird Information in Form von digitalen Daten gespeichert. Digital bedeuted, vereinfacht gesagt, dass die Information in Form von Zahlen gespeichert wird, die wiederum in Form von elektrischen Signalen (z.B. “Strom an oder aus”) repräsentiert werden. Letzteres ist die Grundlage für die Funktionsweise von Computern.
Das bedeutet, dass alle Informationen, die wir in Computern speichern, in Form von Zahlen repräsentiert werden muss. Eine weitere wichtige Eigenschaft von digitalen Daten ist, dass sie in diskreten Einheiten gespeichert werden, also i.d.R. in Form von ganzen Zahlen.
Im Folgenden werden wir uns mit den verschiedenen Arten von Information und deren digitaler Repräsentation beschäftigen.
Text
Text ist die einfachste Form von digitalen Daten. Text wird in Computern in Form von Zeichenketten gespeichert, das heißt einer Abfolge von Zeichen. Jedes Zeichen wird dabei durch eine Zahl repräsentiert, wobei die Zuordnung von Zeichen zu Zahlen durch eine Zeichenkodierung festgelegt wird. Letztere ist eine Tabelle, die jedem Zeichen eine Zahl zuordnet.
Die bekannteste und eine der ersten ist die ASCII-Kodierung (American Standard Code for Information Interchange), welche 128 Zeichen umfasst und im Folgenden dargestellt ist.

Wenn wir die Tabelle betrachten, fällt uns auf, dass nicht nur Buchstaben oder Ziffern, sondern auch Sonderzeichen und Steuerzeichen (z.B. Zeilenumbruch) enthalten sind. Zudem fehlen Umlaute und Sonderzeichen, die in anderen Sprachen verwendet werden.
Daher wurden im Laufe der Zeit weitere Zeichenkodierungen entwickelt, die mehr Zeichen umfassen. Hier ein paar Beispiele:
- latin1 (ISO-8859-1): 256 Zeichen, enthält Umlaute und Sonderzeichen für westeuropäische Sprachen
- latin2 (ISO-8859-2): 256 Zeichen, enthält Umlaute und Sonderzeichen für osteuropäische Sprachen
- GB2312: 6.763 Zeichen, enthält chinesische Schriftzeichen
- UTF-8: 1.112.064 Zeichen, enthält fast alle Schriftzeichen der Welt
Hierbei ist zu beachten, dass die erweiterten Zeichenkodierungen rückwärtskompatibel sind, d.h. die Zahlen-Buchstaben-Kodierungen der ersten 128 Zahlen entsprechen i.d.R. der “alten” ASCII-Kodierungen.
Aktuell ist UTF-8 die am weitesten verbreitete Zeichenkodierung, da sie fast alle Schriftzeichen der Welt umfasst und daher für die meisten Anwendungsfälle geeignet ist. Diese Kodierung wird auch von den meisten neueren Betriebssystemen und Anwendungen standardmäßig verwendet.
Kodierungsprobleme
Was kann passieren, wenn ein Text mit latin1-Kodierung abgespeichert wird (also in Zahlen umgewandelt wird) und anschliessend mit latin2-Kodierung gelesen wird (also die Zahlen wieder mit Buchstaben ersetzt werden)?
Es werden falsche Zeichen angezeigt, da die Zahlen-Buchstaben-Zuordnung nicht übereinstimmt.
Das Problem mit den verschiedenen Zeichencodierungen ist, dass beim Öffnen einer Datei mit einer anderen Codierung als der, in der sie gespeichert wurde, die Zeichen falsch dargestellt werden. Daher ist es wichtig, die Codierung einer Datei zu kennen, um sie korrekt lesen zu können. Ein deutliches Zeichen, dass die falsche Codierung verwendet wird, ist, wenn anstelle von Umlauten oder Sonderzeichen nur Fragezeichen oder andere Zeichen angezeigt werden, wie in folgendem Bild.
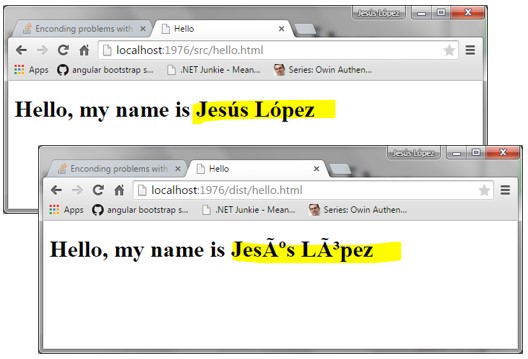
Dies tritt häufig auf, wenn man mit älteren Dateien arbeitet, was gerade im wissenschaftlichen Bereich in der Datennachnutzung von Daten immer wieder vorkommt.
Hinweis
In diesem Fall, muss man händisch die Codierung ändern, um den Text korrekt darzustellen. Hier bleibt häufig nichts weiter übrig, als die Codierung auszuprobieren, bis der Text korrekt dargestellt wird. Dabei ist es hilfreich, über den Ursprung der Datei Bescheid zu wissen.
Hier kommt wieder die Dokumentation von Daten ins Spiel!
Zeilenumbruch im Text
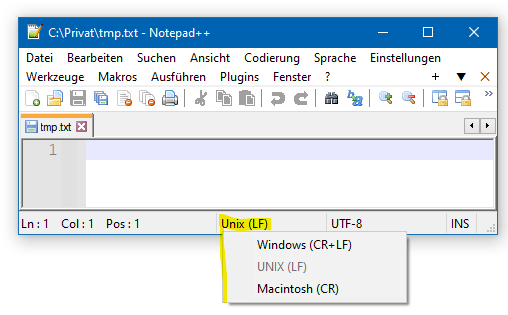
Ein weiteres Problem, das beim Lesen und Verarbeiten von Textdateien auftreten kann, ist der Zeilenumbruch, also das Zeichen, das angibt, dass eine neue Zeile beginnt. In aktuellen Betriebssystemen wird der Zeilenumbruch unterschiedlich abgespeichert:
-
Windows:
\r\n(zwei Zeichen: Carriage Return und Line Feed) -
Linux:
\n(ein Zeichen: Line Feed) -
MacOS:
\roder\n, je nach Alter des Betriebssystems (Carriage Return oder Line Feed)
Dies kann dazu führen, dass Textdateien auf einem Betriebssystem, auf dem sie nicht erstellt wurden, nicht korrekt dargestellt oder verarbeitet werden können.
Hinweis
Texteditoren wie Notepad++ oder Visual Studio Code können automatisch die Zeilenumbrüche in Textdateien erkennen und korrekt darstellen. Auch ist es dort möglich, die Zeilenumbrüche in einem Textdokument zu konvertieren, d.h. von einem Format in ein anderes zu ändern.
Zahlen
Bei der Darstellung von Zahlen werden zwei Formen unterschieden: Ganzzahlen und Fließkommazahlen.
Ganzzahlen
Ganzzahlen, also 1, 13, 42, oder 987654321, werden in Computern durch ihre Zerlegung in 2er-Potenzen gespeichert. Zum Beispiel zerlegt sich 13 in 8+4+1, also 2^3 + 2^2 + 2^0. Im Computer selbst, können nur binäre Zustände, wie Strom an oder aus etc., gespeichert werden. Daher wird kodiert, ob eine 2er-Potenz in der Zahl enthalten ist oder nicht. Hieraus ergibt sich eine Binärdarstellung der Zahl. Im Beispiel der 13 also 1101, wobei die 1en die enthaltenen 2er-Potenzen repräsentieren und die Zahl wird (wie bei Dezimalzahlen auch) von rechts nach links gelesen, wobei die rechte Stelle 2^0 repräsentiert. Somit entspricht die Binärdarstellung 1101 der Dezimalzahl 13, da 2^3 + 2^2 + 2^0 = 8 + 4 + 1 = 13. Dies erlaubt die Speicherung beliebiger Ganzzahlen, solange genügend 2er-Potenzen zur Verfügung stehen, welche durch die maximale Länge der Binärdarstellung begrenzt ist.
Text => Ganzzahl => Binär
Da jedem Buchstaben über die Zeichenkodierung eine Zahl zugewiesen wird, und Ganzzahlen in Binärzahlen umgewandelt werden können, kann auch ein Text in Binärzahlen umgewandelt und gespeichert werden.
Binärzahlen
Normalerweise werden Zahlen in Dezimaldarstellung verwendet, also mit den Ziffern 0-9. Zahlen werden von rechts nach links gelesen, wobei jede Stelle eine 10er-Potenz repräsentiert und die Ziffer der jeweiligen Stelle der Faktor der entsprechenden 10er-Potenz ist. Hier ein Beispiel zur Illustration:
312 = 300 + 10 + 2= 3*100 + 1*10 + 2*1 = 3*10^2 + 1*10^1 + 2*10^0 = 312Binärzahlen hingegen verwenden nur die Ziffern 0 und 1, folgen ansonsten aber den gleichen Regeln wie Dezimalzahlen. Sie werden also auch von recht nach links gelesen, wobei jede Stelle eine 2er-Potenz repräsentiert und die Ziffer der jeweiligen Stelle der Faktor der entsprechenden 2er-Potenz ist. Hier ein Beispiel zur Illustration:
1101 = 1*2^3 + 1*2^2 + 0*2^1 + 1*2^0 = 8 + 4 + 0 + 1 = 13Wie auch bei Dezimalzahlen werden führende 0en meistens weggelassen, da sie keinen Einfluss auf den Wert der Zahl haben. Zudem können auch Binärzahlen addiert, subtrahiert, multipliziert und dividiert werden.
Die Binärdarstellung von Zahlen ist in der Informatik von großer Bedeutung, da sie die Grundlage für die digitale Speicherung und Verarbeitung von Zahlen in Computern bildet.
Frage
Welche Dezimalzahl repräsentiert die Binärzahl 1010?
Die 2er-Potenzen sind
- 2^0 = 1
- 2^1 = 2
- 2^2 = 4
- 2^3 = 8
Die Binärzahl 1011 entspricht der Dezimalzahl 10, da
1*2^3 + 0*2^2 + 1*2^1 + 0*2^0 = 8 + 0 + 2 + 0 = 10.Bits und Bytes
Einzelne “01 Ziffern” einer Binärzahl werden bit genannt, was für “binary digit” steht.
Kolonnen von 8 Bits werden Byte genannt, was für “by eight” steht.
Ein Byte kann also 256 verschiedene Werte annehmen, da 2^8 = 256 verschiedene 01 Kombinationen mit 8 Stellen möglich sind.
Um Daten im Computer speichern, verwalten und abrufen zu können, ist es unumgänglich schon im Vorfeld zu wissen, wie viele Bits und Bytes für die jeweilige Information verwendt wurde. Andernfalls könnten zu wenige oder zuviele Bits gelesen werden, was zu einem falschen Ergebnis führen würde. Oder noch schlimmer: Datenoperationen überlappen, das heisst das Speichern einer Information überschreibt (ggf. auch nur teilweise) eine andere Information.
Um dies zu vermeiden und die Datenintegrität zu gewährleisten, wurden Standards festgelegt, welche die Anzahl der Bits und Bytes für verschiedene Datentypen festlegen. Hier ein paar Beispiele:
- int (Integer): 4 Bytes (32 Bit)
- long (Long Integer): 8 Bytes (64 Bit)
- char (Character): 1 Byte (8 Bit)
- float: 4 Bytes (32 Bit) - für Gleitkommazahlen
- double: 8 Bytes (64 Bit) - für Gleitkommazahlen
Um negative Zahlen darstellen zu können, wird in der Regel das erste Bit als Vorzeichenbit verwendet. Dieses schränkt die Anzahl der darstellbaren Zahlen ein, da nur noch 7 Bit (bzw. 1 Bit weniger) für die eigentliche Zahlenrepräsentation zur Verfügung stehen.
Überlaufproblem
Da die Anzahl der Bits, die zur Speicherung einer Zahl zur Verfügung stehen, begrenzt ist, kann es zu einem Überlauf kommen. Ein Überlauf tritt auf, wenn das Ergebnis einer Berechnung mehr Stellen benötigt als die maximale Anzahl an Bits, die zur Speicherung zur Verfügung stehen. Hierbei werden die führenden Stellen einfach abgeschnitten, was zu einem falschen Ergebnis führt.
Beispiel unter der Annahme von 3 Bit Zahlendarstellung:
7 + 3 = 111 + 011 = (1)010 (Dezimalzahl 10, aber 4 Bit nötig und nur 3 vorhanden > Überlauf)
= 010 (auf letzte 3 Bit reduzierte Speicherdarstellung)
= 2 (entsprechende Dezimalzahl, falsches Ergebnis)Diese Problem ist heutzutage jedoch durch die Verwendung von 32 oder 64 Bit Zahlen in modernen Computern nur noch selten relevant.
Fließ- oder Gleitkommazahlen
Kommazahlen wie 0,0012 können auf verschiedene Arten geschrieben werden, z.B.
- als Bruch 12/10000
- als Dezimalzahl 0,0012
- als wissenschaftliche Notation 1.2e-3 oder 1.2E-3
Die wissenschaftliche Notation kann auf zwei Arten interpretiert werden. Zum einen als mathematische Formel “1,2 * 10^-3 = 1,2 * 0,001 = 0,0012”. Alternativ kann auch herauslesen, dass das Komma in der Zahl 1.2 um 3 Stellen nach links verschoben werden muss, um die eigentliche Zahl 0,0012 zu erhalten.
Letztere Interpretation ist die, die in Computern verwendet und als Gleit- oder Fließkommazahl bezeichnet wird. Hierbei wird die Zahl in zwei Teile zerlegt: die Mantisse und den Exponenten. Die Mantisse enthält die eigentliche Zahl, also 1.5, 3.14159, oder 42.0, und der Exponent gibt (vereinfacht gesagt) an, um wie viele Stellen das Komma nach links oder rechts verschoben werden muss, um die eigentliche Zahl zu erhalten. Der Trick ist nun, dass sowohl Mantisse als auch Exponent als Ganzzahlen gespeichert werden können, für die wir schon eine Umrechnung in Binärzahlen kennen.
Dies funktioniert sehr gut für Zahlen, die sich als Potenzen von 10 darstellen lassen, wie 0,0012 = 1.2 * 10^-3. Für Zahlen, die sich nicht als Potenzen von 10 darstellen lassen, wie 1/3 = 0.3333333333333333…, kann es zu Rundungsfehlern kommen, da der Computer nur eine begrenzte Anzahl von Stellen für die Mantisse und den Exponenten speichern kann, da beide als Ganzzahl mit festen Bit-Anzahlen gespeichert werden. Dadurch ergeben sich Rundungsfehler, da nicht jede Zahl exakt als Gleitkommazahl darstellbar ist. Diese anfängs ggf. sehr kleinen Fehler können sich in nachfolgenden Rechenschritten stark bemerkbar machen, sodass man diese kennen sollte.
Für weitere Details empfehlen wir die Seite Gleitkommadarstellung / Gleitkommazahlen aus dem Elektronik Kompendium.
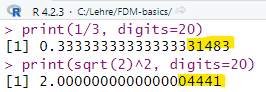
Rundungsfehler beim Rechnen mit Fließkommazahlen
Da der Computer nur eine begrenzte Anzahl von Stellen für die Mantisse und den Exponenten speichern kann, kann es zu Rundungsfehlern kommen, wenn mit Fließkommazahlen gerechnet wird. Hier ein Beispiel unter Verwendung der Programmiersprache R.
Frage
Überlegen sie, wo derartige Rundungsprobleme zu Problemen führen könnten, sodass in diesen Bereichen mit anderen Datentypen gearbeitet werden sollte.
Ein Beispiel für ein Problem, bei dem Rundungsfehler zu Problemen führen können, ist die Berechnung von Zinsen.
Auch z.B. zur Berechnung von Marsmissionen oder anderen wissenschaftlichen Berechnungen, bei denen sehr genaue Ergebnisse erforderlich sind, werden andere Datentypen bzw. mathematische Tricks verwendet.
Sprachabhängige Zahlendarstellung
Ein häufiges Problem bei der Verarbeitung von Zahlen ist die sprachabhängige Darstellung von Zahlen. In Deutschland (und vielen Ländern Westeuropas) wird die Zahl 1000 als 1.000,00 geschrieben, während in den USA die gleiche Zahl als 1,000.00 geschrieben wird.
Das heisst das verwendete Trennzeichen für die “Nachkommastellen” und die Tausenderstellen ist unterschiedlich bzw. umgekehrt.
Solange Zahlen direkt in Binärform gespeichert und eingelesen werden, ist dies kein Problem, da nur die Darstellung der Zahl, nicht aber die Zahl selbst, von der eingestellten Benutzersprache abhängt.
Sobald jedoch Zahlen in Textform eingelesen oder ausgegeben werden, kann es zu Problemen kommen, wenn die Zahlen in einem anderen Format gespeichert sind, als das, in dem sie eingelesen werden sollen.
Wenn sie z.B. eine Datei mit der amerikanischen Notation 1,000 mit einer “deutschen” Software einlesen, wird die Zahl als 1 gelesen, da die deutsche Software das Komma als Dezimaltrennzeichen interpretiert.
Hinweis
Wenn sie fremde textbasierte Daten einlesen, sollten sie diese immer auf das verwendete Zahlenformat überprüfen, um sicherzustellen, dass die Zahlen korrekt eingelesen werden.
Alle Textdatenimportfunktionen in Programmiersprachen (wie Python oder R) und Datenverarbeitungssystemen (wie MS Excel) bieten die Möglichkeit, das zu importierende Zahlenformat anzugeben, um solche Probleme zu vermeiden.
Aber sie selbst müssen daran denken!
Allgemeine Empfehlungen zur Rundung in wissenschaftlichen Arbeiten
Messgenauigkeit beachten
Runden sie nicht auf mehr Stellen, als die Messinstrumente oder Datenquellen hergeben.
Beispiel: Wenn ein Messgerät nur auf 0,1 genau ist, sollte man nicht auf 0,01 runden.-
Typische Rundungen nach Kontext
- Statistische Kennzahlen (Mittelwert, Standardabweichung): meist 2 Dezimalstellen
- Prozentwerte: oft 1 oder 2 Dezimalstellen
- Währungsangaben: 2 Dezimalstellen
- Physikalische Größen: abhängig von der Einheit und Genauigkeit, oft 2–3 Dezimalstellen
- Wissenschaftliche Notation: z. B. \(3.14 × 10^5\), oft 3 signifikante Stellen
-
Signifikante Stellen statt feste Dezimalstellen
In vielen naturwissenschaftlichen Bereichen wird nach signifikanten Stellen gerundet, nicht nach Dezimalstellen.
Beispiel:-
12345→ wenn 1 signifikante Stelle: \(1 × 10^4\) -
12345→ wenn 3 signifikante Stellen: \(1.23 × 10^4\) - Signifikanz ergibt sich hierbei aus
- der Messgenauigkeit der Datenquelle
- der Relevanz für die Analyse
- der Konvention im jeweiligen Fachgebiet
- der Vergleichbarkeit mit anderen Daten, z.B. bei Daten aus verschiedenen Quellen die gleiche Anzahl an signifikanten Stellen verwenden
-
Konsistenz ist wichtig
In Tabellen oder Diagrammen sollten alle Werte gleich gerundet sein, um die Lesbarkeit zu verbessern.
Zeit
Die Zeit wird in Computern als Anzahl von (Milli)Sekunden seit einem festgelegten Zeitpunkt gespeichert.
Dieser Zeitpunkt ist in der Regel der 1. Januar 1970 um 00:00:00 Uhr (UTC), auch als Unix-Zeit bekannt. Diese Darstellung hat den Vorteil, dass die Zeit als Ganzzahl gespeichert werden kann, was die Speicherung und Verarbeitung vereinfacht und Rundungsfehler vermeidet.
Jahr-2038-Problem
Ein Problem bei der Speicherung von Zeit als Ganzzahl ist das Jahr-2038-Problem. Lesen sie diesen Wikipedia-Artikel und erklären sie, warum es auftritt und welche Auswirkungen es haben könnte.
Das Jahr-2038-Problem tritt auf, weil die Unix-Zeit als vorzeichenbehaftete 32-Bit-Ganzzahl gespeichert wird.
Das heisst nicht alle 32 Bit sind für die Zahl selbst reserviert, sondern das erste Bit gibt das Vorzeichen an. Da die Unix-Zeit den 1. Januar 1970 als Nullpunkt hat, wird die Zeit in Sekunden seit diesem Zeitpunkt gespeichert. Da eine 32-Bit-Ganzzahl nur 2^32 = 4.294.967.296 verschiedene Werte speichern kann, wird die Unix-Zeit am 19. Januar 2038 um 03:14:07 Uhr UTC den Wert 2.147.483.647 erreichen. Da die Unix-Zeit als vorzeichenbehaftete Ganzzahl gespeichert wird, wird der Wert am 19. Januar 2038 um 03:14:07 Uhr UTC auf -2.147.483.648 springen, was zu einem Überlauf führt. Dieser Überlauf führt dazu, dass die Zeit wieder bei -2.147.483.648 beginnt, was dem 13. Dezember 1901 um 20:45:52 Uhr UTC entspricht.
Farben
Farben werden in Computern z.B. als RGB-Werte gespeichert, also als Kombination von Rot-, Grün- und Blauanteilen des jeweiligen Lichtes. Jeder dieser Anteile wird als Zahl zwischen 0 und 255 gespeichert, wobei 0 für keinen und 255 für den maximalen Anteil des jeweiligen Farbtons steht. Das es sich um “Lichtfarben” handelt, wird somit die Farbe Weiß als (255, 255, 255) und die Farbe Schwarz als (0, 0, 0) gespeichert.
Da es sich um Ganzzahlen handelt, können diese auch in Binärform gespeichert werden, wobei die 8 Bit für jeden Farbton die Binärdarstellung der Zahl zwischen 0 und 255 darstellen. Aufgrund der diskreten Werte für die Farbanteile sind Farbverläufe nicht stufenlos sondern nur in diskreten Schritten möglich.
Neben RGB gibt es auch andere Farbmodelle, wie z.B. CMYK (Cyan, Magenta, Yellow, Key) für den Druck oder HSV (Hue, Saturation, Value) für die Farbdefinition. Auch hier werden die Farben als Zahlen gespeichert, wobei die Umrechnung zwischen den verschiedenen Farbmodellen durch mathematische Formeln erfolgt.
Farbkodierung liefert die Grundlage für Bild- und Videodaten, die selbst wieder in verschiedensten Formaten gespeichert werden können.
Frage
Wenn sie im Farbkasten Rot, Grün und Blau mischen, entsteht i.d.R. nicht weiß, sondern ein Braunton. Warum ist das so?
Die Farben im Farbkasten sind Pigmente, die das Licht absorbieren und nur bestimmte Farben reflektieren. Wenn sie Rot, Grün und Blau mischen, absorbieren sie fast alles Licht, sodass die Mischung dunkel erscheint.
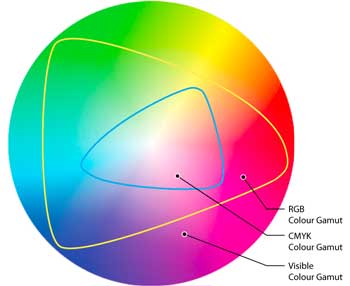
In folgendem Bild sehen sie, dass die unterschiedlichen Farbmodelle nur Teile des vom Menschen sichtbaren Farbraums abdecken.
Hinweis
Die Diskretisierung der Farbwerte kann zu Farbverlust führen, wenn die Farben in einem anderen Farbmodell gespeichert und wieder in RGB umgewandelt werden.
Daher sollte die Umwandlung zwischen den Farbmodellen nur dann erfolgen, wenn es unbedingt notwendig ist, am besten nach der Bildbearbeitung.
Für weiterführende Informationen rund um die Farbmodelle RGB und CMYK, ihrer Unterschiede und Umwandlung empfehlen wir folgende Seite.
Audio
Auch Audiodaten werden als Zahlen gespeichert, wobei die Amplitude des Schallsignals als Zahl gespeichert wird. Die Amplitude wird in der Regel als Zahl zwischen -1 und 1 gespeichert, wobei -1 für den minimalen und 1 für den maximalen Schalldruck steht. Da es sich um eine kontinuierliche Größe handelt, wird die Amplitude in der Regel als Gleitkommazahl gespeichert, um eine möglichst genaue Repräsentation des Schallsignals zu erhalten.
Zusammenfassung
- Jedwede Information wird i.d.R. durch Ganzzahlen repräsentiert
- Text via Zeichenencodingstabellen
- Gleitkommazahlen z.B. durch Mantisse und Exponent
- Zeit z.B. als Anzahl von Sekunden seit einem festgelegten Zeitpunkt
- Farben z.B. durch RGB-Werte
- Ganzzahlen können in Binärform gespeichert und verarbeitet werden
- dabei in 2er-Potenzen zerlegt
- Interpretation analog zu Dezimalzahlen (rechts nach links, …)
- Bit = eine “Ziffer” einer Binärzahl (0 oder 1)
- 8 Bit = 1 Byte
- Anzahl der Bits bestimmt die maximal darstellbare Zahl (Überlaufproblem)
- Probleme digitaler Informationsrepräsentation
- Überlaufproblem bei zu großen Zahlen
- Diskretisierung von kontinuierlichen Größen
- Rundungsfehler bei Gleitkommazahlen
- Verlust von Genauigkeit bei zu kleinen/großen Zahlen
- Kodierungsprobleme bei Textimport
- Sprachabhängige Darstellung von Zahlen
- Unterschiedliche Zeichenencodings
- Zeilenumbrüche in Textdateien abh. vom Betriebssystem
- Farbmodelle decken nicht den gesamten Farbraum ab
Einordnung im Datenlebenszyklus
Das Wissen um die digitale Repräsentation von Informationen ist immer dann zentral, wenn Daten importiert oder exportiert werden, um sicherzustellen, dass die Daten korrekt übertragen und gespeichert werden.
- Planung: Festlegung von Datenformaten und -strukturen
- Erhebung: Korrekte Interpretation von Daten
- Archivierung: Export von Daten in geeigneten Formaten
- Nachnutzung: korrekter Datenimport und -export
Quelle - Wikimedia Commons - 07.08.2024↩︎
Quelle - aufkleberdrucker24.de - 12.09.2024↩︎
{kind=link}