Alles auf einen Blick
Content from Datenstrukturen
Zuletzt aktualisiert am 2026-07-03 | Diese Seite bearbeiten
Geschätzte Zeit: 20 Minuten
Übersicht
Fragen
- Welche Datenarten gibt es?
- Wie organisiere ich tabellarische Daten?
- Was sind “tidy” Daten?
Ziele
- Standarddatentypen in Python
- DataFrames für tabellarische Daten
- Konzept der “tidy” Daten
Wir gehen in diesem Modul davon aus, dass Sie die Grundlagen der Python-Programmierung kennen, insbesondere
- die Verwendung von Variablen, Listen und Schleifen,
- die Verwendung von Funktionen und Methoden,
- die Verwendung von Paketen und Modulen,
- die Verwendung eingebauter Datenstrukturen wie
list,dictundset.
Wenn Sie sich nicht sicher sind, können Sie gerne eines der Python-Tutorials im Web durchgehen, z.B. das offizielle Python-Tutorial oder das Python-Tutorial von W3Schools.
In diesem Modul ist besonders die Verarbeitung tabellarischer
Datensätze relevant. Dafür sind die eingebauten Datenstrukturen von
Python nicht optimal geeignet. Daher verwenden wir das Paket pandas, das speziell für
die Verarbeitung von tabellarischen Daten entwickelt wurde. Für die
Aufgaben in diesem Modul ist es also nötig, zunächst dieses Paket zu
installieren (sofern auf Ihrem Gerät noch nicht geschehen) und dann im
Python-Skript einzubinden. Die Installation erfolgt in der Regel über
den Paketmanager pip in der Kommandozeile oder im Terminal
mit dem Befehl pip install pandas.
Die Einbindung in ein Python-Skript erfolgt dann üblicherweise mit dem Befehl:
Eine Tabelle in pandas wird über Dataframes (Datentyp
DataFrame) repräsentiert. Ein Dataframe ist eine
zweidimensionale Datenstruktur, die Daten in Zeilen und Spalten
organisiert. Jede Spalte eines Dataframe ist ein
Series-Objekt, das eine Liste von Werten enthält. Ein
Dataframe kann als eine Sammlung von Series-Objekten
betrachtet werden, die alle den gleichen Index haben. Mit Index ist die
nullbasierte Zeilennummer oder ein benutzerdefinierter Index gemeint,
der die Zeilen des Dataframe identifiziert.
In einem Dataframe entspricht jede Zeile einem Datensatz (oder einer
Beobachtung) und jede Spalte einer Variable (oder einem Merkmal) dieses
Datensatzes. Damit haben alle Daten in der gleichen Spalte den gleichen
Datentyp, z.B. Ganzzahl (int), Kommazahl
(float), Text/String (str), Datum
(date), usw.
Im Folgenden wird der Beispieldatensatz
storms als Dataframe ausgegeben (wie der Datensatz
importiert wird, wird später behandelt). Dieser Datensatz enthält
Messdaten zu tropischen Stürmen an unterschiedlichen Tagen. Hier ist ein
Ausschnitt des Dataframes:
name year month day hour lat long status \
0 Amy 1975 6 27 0 27.5 -79.0 tropical depression
1 Amy 1975 6 27 6 28.5 -79.0 tropical depression
2 Amy 1975 6 27 12 29.5 -79.0 tropical depression
3 Amy 1975 6 27 18 30.5 -79.0 tropical depression
4 Amy 1975 6 28 0 31.5 -78.8 tropical depression
... ... ... ... ... ... ... ... ...
19532 Nicole 2022 11 10 19 29.2 -83.0 tropical storm
19533 Nicole 2022 11 11 0 30.1 -84.0 tropical storm
19534 Nicole 2022 11 11 6 31.2 -84.6 tropical depression
19535 Nicole 2022 11 11 12 33.2 -84.6 tropical depression
19536 Nicole 2022 11 11 18 35.4 -83.8 other low
category wind pressure tropicalstorm_force_diameter \
0 NaN 25 1013 NaN
1 NaN 25 1013 NaN
2 NaN 25 1013 NaN
3 NaN 25 1013 NaN
4 NaN 25 1012 NaN
... ... ... ... ...
19532 NaN 40 989 300.0
19533 NaN 35 992 300.0
19534 NaN 30 996 0.0
19535 NaN 25 999 0.0
19536 NaN 25 1000 0.0
hurricane_force_diameter
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
19532 0.0
19533 0.0
19534 0.0
19535 0.0
19536 0.0
[19537 rows x 13 columns]Hinweis: bei der Ausgabe eines Dataframe mit der Funktion
print() werden standardmäßig jeweils die ersten und letzten
fünf Zeilen ausgegeben. Da dieser Datensatz 13 Spalten hat und daher
nicht alle Spalten in einer Reihe dargestellt werden können, wird die
Breite des Dataframe in drei Teile aufgeteilt und separat
dargestellt.
Dataframes können sowohl aus Dateien und dem Web importiert werden
(s. nächstes Kapitel) oder aber aus anderen Datenstrukturen erstellt
werden, z.B. aus Dictionarys (dict) und Listen
(list). Hier ist ein Beispiel, das einen Dataframe erzeugt
mittels eines Dictionarys, dessen Schlüssel den Spaltennamen des
Dataframes entsprechen, und dessen Werte jeweils Listen für die Inhalte
(Zeilen) der entsprechenden der Spalten enthalten:
PYTHON
marriages = pd.DataFrame({
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35],
"married": [True, False, True]
})
print(marriages)AUSGABE
name age married
0 Alice 25 True
1 Bob 30 False
2 Charlie 35 TrueZiel der Datenverarbeitung ist es, vorliegende Datensätze so zu transformieren, dass sie für die Analyse und Visualisierung geeignet sind und ein Format wie im obigen Beispiel vorweisen. Wenn das der Fall ist, sprich
- jede Zeile entspricht einem Datensatz und
- jede Spalte entspricht einer Variable,
wird der Datensatz als “tidy” bezeichnet. Im folgenden Bild ist das dies veranschaulicht:

Spaltenzugriff
Betrachten sie den Datensatz marriages von oben.
Wie können Sie nur die Spalte age aus dem Datensatz
extrahieren?
Es gibt dafür unterschiedliche Möglichkeiten, die im Folgenden aufgeführt sind:
PYTHON
# Extrahiert die Spalte als Liste von Werten (in Pandas der Datentyp Series)
marriages["age"]
# Alternative Schreibweise, die möglich ist, wenn der Spaltenname keine Leerzeichen oder Sonderzeichen enthält
marriages.age
# Pandas erlaubt Zugriff auch über .loc[]
marriages.loc[:, "age"]
# ... und indexbasiert über .iloc[] (hier: 1 steht für die zweite Spalte, da der Index 0-basiert ist)
marriages.iloc[:, 1]Hinweise:
- Der Zugriff über den Spaltennamen ist in der Regel die bevorzugte Methode, da sie am lesbarsten ist.
- Der Zugriff über den Index ist weniger lesbar und sollte nur verwendet werden, wenn der Spaltenname nicht bekannt ist oder nicht verwendet werden kann.
-
locundilocsind mächtige Methoden, die ganze Bereiche von Zeilen und Spalten auswählen können, wie z.B.marriages.loc[1:2, "age"]liefert Zeilen 1 bis 2 der Spalteage. Der Unterschied zwischenlocundilocist, dasslocdie Zeilen und Spalten über den Indexnamen adressiert, währendilocdies mit dem Indexwert macht.
Datentypen
Welche Datentypen haben die Spalten des Datensatzes?
-
name: Text (str) -
age: Ganzzahl (int); wenn man Kommazahlen angibt, wird der Datentypfloatsein (z.B.25.0) -
married: Wahrheitswert (bool) mitTruefür verheiratet undFalsefür nicht verheiratet
Aufbau
Wieviele Beobachtungen und Variablen hat der Datensatz?
- Beobachtungen: 4 = Anzahl der Zeilen bzw. Länge der Spalten
- Variablen: 3 = Anzahl der Spalten
- Spalten in einem
DataFramewerden auch Variablen (des Datensatzes) genannt.- Eine Spalte ist eine
Series, also eine Liste von Werten des gleichen Datentyps.
- Eine Spalte ist eine
- Zeilen in einem
DataFramewerden auch Beobachtungen (des Datensatzes) genannt. - Ein Datensatz ist “tidy”,
- wenn jede Zeile einem Datensatz und jede Spalte einer Variable entspricht.
- Vereinfacht: wenn man beim Visualisieren der Daten nur jeweils eine Zeile pro Datenpunkt benötigt und keine doppelt verwendet wird.
- Das pandas Cheatsheet kann helfen, die Funktionen und Methoden von Pandas zu verstehen und zu nutzen.
Content from Datenimport aus Dateien
Zuletzt aktualisiert am 2026-07-03 | Diese Seite bearbeiten
Geschätzte Zeit: 30 Minuten
Übersicht
Fragen
- Wie importiere ich Daten?
- Auf was muss ich achten?
Ziele
- Datenimport via
pandas - Kodierung von Zahlen und Texten
- Pfadangaben
Datenquellen einlesen
Mit pandas können Daten aus verschiedenen Quellen und von verschiedenen Orten eingelesen werden. Die gängigsten Quellen sind:
- Textdateien (z.B.
.csv,.tsv,.txt) - Excel-Dateien (z.B.
.xlsx,.xls) - Datenbanken (z.B. MySQL, PostgreSQL, SQLite)
Die gängigsten Orte sind:
- lokale Dateien
- URLs, also direkter Datenimport aus dem Internet oder lokalem Netzwerk
Bevor wir loslegen, müssen wir das pandas Paket importieren. Dies
wird in der Regel mit dem Befehl import pandas as pd
gemacht. Das as pd ist eine gängige Abkürzung, um das Paket
in der weiteren Verwendung kürzer zu schreiben:
Im Folgenden einige Beispiele zum Einlesen von Daten aus Dateien mit
pandas in Python. Im Fall von CSV- oder TSV-Dateien wird die Funktion
read_csv() verwendet, für Excel-Dateien
read_excel(). Die Funktionen haben viele optionale
Parameter, die in der Dokumentation
beschrieben sind.
Hier ein Beispiel, in dem eine CSV-Datei aus dem Internet geladen und der entsprechende von pandas erzeugte Dataframe ausgegeben wird:
PYTHON
# CSV-Datei mit allen Sturmdaten 1975-2022 aus dem Internet laden und in die Variable web_data speichern
web_data = pd.read_csv("https://raw.githubusercontent.com/tidyverse/dplyr/master/data-raw/storms.csv")
# Geben wir den Dataframe aus
print(web_data)Werden stattdessen Dateien vom lokalen Computer geladen, so müssen sich diese im Arbeitsverzeichnis befinden, wenn sie nur mit dem Dateinamen adressiert werden. Das Arbeitsverzeichnis ist jenes Verzeichnis, in dem das Python-Skript ausgeführt wird. Wenn die Dateien nicht im Arbeitsverzeichnis liegen, müssen sie über den relativen bzw. absoluten Dateipfad adressiert werden (siehe weiter unten).
Um den folgenden Beispielcodes mit lokalen Dateien auszuführen, müssen daher die Dateien storms-2019-2021.csv und storms-2019-2021.xlsx erst heruntergeladen und ins aktuelle Arbeitsverzeichnis kopiert werden.
Laden eines Tabellenblattes aus einer Excel-Datei:
PYTHON
# Lokale Excel-Datei laden mit expliziter Angabe des Tabellenblatts
excel_data = pd.read_excel("storms-2019-2021.xlsx", sheet_name="storms-2020")
print(excel_data)Hier der Code zum Laden einer CSV-Datei vom lokalen Computer, die
sich im aktuellen Arbeitsverzeichnis befindet. Hier werden einige der
optionalen Parameter der Funktion read_csv() verwendet. Der
Grund: die oben aus dem Internet geladene Datei verwendet gemäß
CSV-Standard das Komma als Spaltentrennzeichen, die lokale Datei
verwendet hierfür jedoch das Semikolon (Strichpunkt). Die Zahlen in der
lokalen CSV-Datei sind auch mit westeuropäischem Zahlenformat
(, als Dezimaltrennzeichen und . als
Tausendertrennzeichen) gespeichert. Daher müssen hier beim Laden die
Parameter sep, decimal und
thousands angepasst werden. Auch die Zeichenkodierung
(encoding) der Datei kann angegeben werden, vor allem wenn
sie nicht UTF-8 ist.
PYTHON
# Lokale CSV-Datei laden.
csv_data = pd.read_csv("storms-2019-2021.csv", sep=";", decimal=",", thousands=".", encoding="latin1")
print(csv_data)Die angegebene Zeichenkodierung beim Aufruf von
read_csv() muss der Zeichencodierung der Datei entsprechen
oder damit kompatibel sein, um sicherzustellen, dass beispielsweise
Umlaute und Sonderzeichen korrekt eingelesen werden (hier im Beispiel
wird latin1 verwendet, was für westeuropäische Länder wie
Deutschland oder Frankreich üblich ist bzw. war). Dies ist vor allem
beim Import von alten Daten wichtig zu beachten, die in einem
anderen Zeichensatz kodiert sein könnten. Heutzutage wird meist
UTF-8 verwendet, was ein internationaler Standard ist und
alle bekannten Zeichen korrekt darstellen kann. UTF-8 ist
auch die Standardenkodierung für die meisten Funktionen wie z.B.
read_csv(), wenn kein encoding beim Aufruf
mitgegeben wird.
Es gibt noch viele weitere nützliche optionale Parameter der
Funktionen read_csv(), die in der Dokumentation
dieser Funktion beschrieben sind, beispielweise um festzulegen, ab
welcher Zeile das Einlesen der CSV-Datei starten soll und wie viele
Zielen eingelesen werden sollen:
PYTHON
# Die ersten 10 Zeilen einer CSV-Datei einlesen
csv_data = pd.read_csv("irgendein.csv", nrows=10)
# Die CSV-Datei ab der 11. Zeile einlesen
csv_data = pd.read_csv("irgendein.csv", skiprows=10)
# Man kann auch angeben, in welcher Zeile (0-basiert) die Spaltenüberschriften stehen, das Einlesen beginnt dann ab da
csv_data = pd.read_csv("irgendein.csv", header=4)
# Diese Parameter kann man auch kombinierne, z.B. die ersten 10 Zeilen der überspringen und die nächsten 10 Zeilen einlesen
csv_data = pd.read_csv("irgendein.csv", skiprows=10, nrows=10)Das Speichern der Daten in einer Datei erfolgt analog, indem einfach
to_ anstelle von read_ verwendet wird, also
z.B. to_csv(). Bei to_csv() können analog die
Spaltentrennzeichen usw. angegeben werden. Da in einem Dataframe jede
Zeile einen Index hat, wird dieser standardmäßig auch in die Datei
geschrieben, was üblicherweise eine zusätzliche Spalte an erster Stelle
der CSV-Datei erzeugt, die einfach die Zeilen der Datei durchnummeriert
bei 0 beginnend. In der Regel möchten wir das nicht, so können wir den
Parameter index=False setzen, z.B. mit
csv_data.to_csv("output.csv", index=False).
Alle Funktionen für das Einlesen und Speichern von Daten mit dem
Paket pandas sind in der Pandas-Dokumentation
zu IO-Tools zusammengefasst.
Frage zu CSV Import
Was sind bei read_csv() die Standardwerte für
sep (Spaltentrennzeichen), decimal
(Dezimaltrennzeichen), thousands (Tausendertrennzeichen)
und encoding (Zeichenkodierung), wenn sie nicht explizit
beim Aufruf der Funktion angegeben werden?
Die Standardwerte sind: Komma für Spaltentrennzeichen, Punkt für Dezimaltrennzeichen, kein Tausendertrennzeichen, und UTF-8 für die Zeichenkodierung. Ein Parameter muss nur angegeben werden, wenn dessen Ausprägung in der CSV-Datei vom jeweiligen Standardwert abweicht.
Aufgabe: Datenimport
Führen sie die obigen Beispiele aus und passen sie sie an, um die
Dateien storms-2019-2021.csv und
storms-2019-2021.xlsx einzulesen. Hierzu müssen diese
Dateien ggf. zuvor heruntergeladen werden (oder sie verwenden direkt die
URL zu den online verfügbaren Dateien).
Wieviele Zeilen haben die jeweiligen Datensätze? Und wie erklärt sich der Unterschied?
Die Datensätze haben unterschiedliche Größen:
-
storms-2019-2021.csvhat 19 Zeilen, es umfasst die Jahre 2019-2021. -
storms-2019-2021.xlsxhat 10 Zeilen, es umfasst nur das Jahr 2020 da nur ein einzelnes Datenblatt importiert wurde.
Pfade und Arbeitsverzeichnis
Dateien können auch relativ zum Arbeitsverzeichnis geladen werden. Das Arbeitsverzeichnis ist der Ordner, in dem das aktuelle Python-Skript ausgeführt wird. Dies erlaubt das Laden von Dateien ohne Angabe des vollständigen Pfades, auch wenn sich die Dateien nicht im Arbeitsverzeichnis befinden. Der große Vorteil ist, dass der Code portabler wird, da er nicht mehr von absoluten Pfaden (also wo die Daten auf ihrem Computer genau liegen) abhängt.
Zum Beispiel, wenn sich die Datei storms.csv im
Unterordner data des Arbeitsverzeichnisses befindet, kann
sie mit read_csv("data/storms.csv") geladen werden.
Wenn nötig, können auch vollständige Pfade verwendet werden, um
Dateien von beliebigen Orten auf dem Computer zu laden. Das nennt man
dann einen absoluten Pfad. Ein Beispiel auf einem
Windows-System wäre
read_csv("C:/Users/Username/Documents/data.csv").
Wenn sie die letzte Pfadangabe mit der Standard-Windows-Schreibweise
vergleichen, werden sie feststellen, dass diese normalerweise mit
Backslashes \ arbeitet, also hier
"C:\Users\Username\Documents\data.csv". Das Problem ist,
dass der Backslash in Python als Escape-Zeichen verwendet wird, um
spezielle Zeichen (wie z.B. Zeilenumbruch oder Tabulator) zu kodieren.
Daher wird der Backslash in Pfadangaben in R oft verdoppelt, um dies zu
umgehen. Also würde der Pfad in R so aussehen:
"C:\\Users\\Username\\Documents\\data.csv". Alternativ
können sie auch in Windows (wie im obigen Beispiel) die
“Linux-Schreibweise” verwenden, die mit Schrägstrichen /
arbeitet, die in R ohne Probleme verwendet werden können.
Einfache Spaltenmanipulation
Nachdem man eine CSV-Datei in einen Dataframe eingelesen hat, kommt man zunächst oft in die Situation, dass einige Spalten umbenannt, gelöscht, oder anders angeordnet werden sollen für die weitere Verarbeitung. Hier sind einige Beispiele, wie dies in pandas gemacht werden kann:
Entfernen von Spalten: Es gibt mehrere
Möglichkeiten, eine Spalte aus einem Dataframe zu entfernen.
drop() entfernt eine oder mehrere Spalten. Möchte man
allerdings die entfernte Spalte weiterverwenden, so empfiehlt sich die
Verwendung der Funktion pop(). Diese entfernt die Spalte
und gibt sie zurück, so dass sie in einer neuen Variable gespeichert
werden kann. Hier Beispielcode für beide Methoden:
PYTHON
# Entfernen der Spalte "diameter" aus dem Dataframe "df" mit drop()
df.drop(columns=["diameter"], inplace=True)
# Entfernen der Spalten "status" und "wind" aus dem Dataframe "df" mit drop()
df.drop(columns=["status", "wind"], inplace=True)
# Entfernen der Spalte "diameter" aus dem Dataframe "df" mit pop()
diameter = df.pop("diameter") # diameter enthält jetzt die Werte der entfernten Spalte "diameter"Achtung: Der Parameter inplace=True bedeutet, dass die
Änderung direkt im Dataframe df gemacht wird. Wird dieser
Parameter nicht so angegeben (standardmäßig ist er False),
wird eine Kopie des Dataframes mit der gewünschten Änderung
zurückgegeben, während der Dataframe df unverändert bleibt.
Dies gilt für fast alle Dataframe-Manipulationen in pandas! Alternativ
zur Angabe dieses Parameters kann das Ergebnis des Aufrufs der Funktion
auch in df oder einer neuen Variable gespeichert werden,
z.B. df = df.drop(columns=["wind"])
Umbenennen von Spalten: Im folgenden Beispiel wird
im Dataframe df die Spalte wind in
windspeed und die Spalte
tropicalstorm_force_diameter in diameter
umbenannt.
PYTHON
df.rename(columns={
"wind": "windspeed",
"tropicalstorm_force_diameter": "diameter"
}, inplace=True)Veränderung der Spaltenreihenfolge: Im folgenden
Beispiel wird die Reihenfolge der Spalten im Dataframe df
geändert, indem die Spalte diameter an die dritte Stelle
(0-basierter Index ist also 2) verschoben wird. Dies wird erreicht,
indem die Spalte mit pop() zunächst entfernt und mit
insert() an der gewünschten Stelle wieder eingefügt wird.
Auch hier wird die Änderung direkt im Dataframe gemacht, da
inplace=True gesetzt ist. Beachten Sie, dass diese beiden
Funktionen den Dataframe df direkt verändern und keinen
neuen Dataframe zurückgeben. Falls Sie diesbezüglich im Unklaren sind
beim Aufruf einer Funktion, sehen Sie in der Dokumentation der
entsprechenden Funktion nach oder probieren Sie es einfach aus!
PYTHON
# Verschieben der Spalte "diameter" an die dritte Stelle (Spaltenindex 2)
df.insert(2, df.pop("diameter"))Einfügen neuer Spalten: Neue Spalten können einfach hinzugefügt werden, indem sie mit einem Wert oder einer Liste von Werten (üblicherweise auf Grundlage der Werte einer anderen Spalte) initialisiert werden:
PYTHON
# Neue Spalte "category" mit dem Wert "storm" für alle Zeilen hinzufügen
df["category"] = "storm"
# Neue Spalte "wind_kmh" mit den Werten der Spalte "wind" umgerechnet von Knoten in km/h hinzufügen
df["wind_kmh"] = df["wind"] * 1.852Weiterführende Manipulationsmöglichkeiten für Dataframes behandeln wir im folgenden Kapitel zur Datenverarbeitung.
- Dateinamen sind Textinformation und müssen in Anführungszeichen gesetzt werden.
- Pfade können absolut oder relativ zum Arbeitsverzeichnis angegeben werden. Letzteres ist portabler und empfohlen.
- Unter Microsoft Windows können Pfade in Pyhton auch mit
Schrägstrichen
/statt Backslashes\geschrieben werden. - Achten sie auf die Angabe der korrekten Kodierung von Textdateien, um Umlaute und Sonderzeichen korrekt einzulesen.
- Denken sie daran, dass deutsche CSV-Dateien oft Semikolon
(
;) als Spaltentrennzeichen und Komma,als Dezimaltrenner verwenden. Auch Excel verwendet für den CSV-Export das Semikolon als Spaltentrennzeichen. - Excel-Dateien können mehrere Blätter (sheets) enthalten, die einzeln importiert werden müssen.
- Zusammenfassung der Lese- und Schreiboperationen in der Pandas-Dokumentation zu IO-Tools.
Content from Datenverarbeitung
Zuletzt aktualisiert am 2026-07-03 | Diese Seite bearbeiten
Geschätzte Zeit: 40 Minuten
Übersicht
Fragen
- Wie wähle ich Zeilen und Werte aus einem Dataframe aus?
- Wie erstelle ich komplexe Datenverarbeitungsworkflows?
- Wie transformiere ich Tabellen?
- Wie bearbeite ich Text in Zellen?
Ziele
- Zugriff auf und Filtern von Zeilen
- Sortieren von Spalten und Entfernen von Duplikaten
- Gruppieren und Aggregieren von Daten
- Ändern der Tabellengestalt von schmal zu breit und umgekehert
- Verändern von Zellinhalten
Zeilen via Index auswählen
Auswahl konkreter Zeilen via Index geht mit der Funktion
.loc[] und der Übergabe eines einzelnen Zeilenindex, eines
Indexbereichs oder einer Liste von Zeilenindizes:
-
storms.loc[25]→ die Zeile mit Index 25, also die 26. Zeile, da 0-basierter Index -
storms.loc[[1, 3, 5]]→ die Zeilen mit Index 1, 3 und 5 -
storms.loc[10:20]→ die Zeilen mit Index 10 bis 19. Achtung: der Index links vom Doppelpunkt ist inklusive, rechts exklusive! -
storms.loc[100:]→ alle Zeilen ab Zeile mit Index 100 -
storms.loc[:25]→ die ersten 25 Zeilen, entsprichtstorms.head(25)undstorms.loc[0:25]
-
storms.head(10)→ die 10 ersten Zeilen -
storms.tail(10)→ die 10 letzten Zeilen -
storms[storms.pressure == storms.pressure.max()]= die Zeile(n) mit dem höchsten Wert in der Spaltepressure
Hier ist mehrmals der Begriff Index in Bezug auf die Zeilen eines Dataframe vorgekommen. In einem Dataframe ist jeder Eintrag (Zeile) mit einem Index versehen, der standardmäßig mit 0 beginnt und um 1 erhöht wird. Dieser Index ist eine eindeutige Nummer, die jede Zeile im Dataframe identifiziert. Wenn nun durch Filtern oder andere Operationen Zeilen entfernt werden, bleibt der Index erhalten und wird nicht neu sortiert. Das bedeutet, dass der Index nicht mehr mit der Zeilennummer übereinstimmen muss. Wenn Sie also eine bestimmte Zeile auswählen möchten, sollten Sie den Index verwenden, nicht die Zeilennummer. Um das zu illustrieren:
PYTHON
persons = pd.DataFrame({
"name": ["John", "Paula", "Georgia", "Ringo"],
"age": [45, 17, 20, 24]
})
print(persons)AUSGABE
name age
0 John 45
1 Paula 17
2 Georgia 20
3 Ringo 24Wenn wir nun Filtern auf alle Personen, die älter als 22 sind, erhalten wir einen Dataframe mit zwei Zeilen, deren Index 0 und 3 ist:
AUSGABE
name age
0 John 45
3 Ringo 24Um also im Dataframe older auf die zweite Zeile (die
Person mit Namen Ringo) zuzugreifen, müssen wir - vielleicht etwas
unintuitiv - den Index 3 verwenden:
AUSGABE
name Ringo
age 24
Name: 3, dtype: objectUm über die Zeilennummer und nicht über ihren Index zuzugreifen,
können wir entweder den Index zurücksetzen mittels
reset_index() oder die Methode iloc[]
aufrufen. Beide liefern das gleiche Ergebnis:
Filtern von Zeilen
Das Filtern mit gegebenen Bedingungen (formulieren was man behalten will!) macht man in eckigen Klammern, sodass ein Dataframe zurückgegeben wird, der nur jene Zeilen enthält, die den Kriterien entsprechen. Der ursprüngliche Dataframe wird dabei nicht verändert:
-
storms[storms.year == 2020]→ alle Sturmdaten aus dem Jahr 2020 -
storms[(storms.year == 2020) & (storms.month == 6)]→ alle Sturmdaten aus dem Juni 2020. Bitte beachten Sie, dass logisch verknüpfte Bedingungen jeweils in Klammern stehen müssen und die einzelnen Bedingungen mit einfachem&(UND) oder|(ODER) verknüpft werden. -
storms[~pd.isna(storms.category)]→ alle Sturmdaten, bei denen die Kategorie bekannt ist, wobei~für Negation steht undisna()für is not available steht.
Daten sortieren
Die Sortierung eines Dataframe kann mit der Funktion
sort_values() erfolgen, die die Daten nach einer oder
mehreren Spalten sortiert. Die Sortierung erfolgt standardmäßig
aufsteigend, kann aber mit dem Argument ascending=False
umgekehrt werden:
-
storms.sort_values("year")→ Sturmdaten nach Jahr aufsteigend sortieren -
storms.sort_values("year", ascending=False)→ Sturmdaten nach Jahr absteigend sortieren -
storms.sort_values(["year", "month"], ascending=[True, False])→ Sturmdaten aufsteigend nach Jahr sortieren und innerhalb eines Jahres absteigend nach Monat
Duplikate entfernen
Duplikate, also Zeilen, in denen paarweise die Werte in allen Spalten
gleich sind, kann man mit der Funktion drop_duplicates()
entfernen:
-
storms.drop_duplicates()→ alle Zeilen mit identischen Werten in allen Spalten entfernen -
storms[["year", "month", "day"]].drop_duplicates()→ alle Zeilen mit gleichen Werten in den Spaltenyear,monthunddayentfernen (reduziert die Spalten auf die Ausgewählten) -
storms.drop_duplicates(["year", "month", "day"])→ alle Zeilen mit gleichen Werten in den Spaltenyear,monthunddayentfernen, aber alle Spalten behalten
Stürme vor 1980
Erstelle eine Tabelle, welche für jeden Sturm vor 1980 neben dessen Namen nur das Jahr und dessen Status beinhaltet und nach Jahr und Status sortiert ist.
Gehen Sie wie folgt vor:
- Reduzieren Sie auf jene Zeilen, in denen das Jahr kleiner als 1980 ist
- Reduzieren Sie auf die Spalten
name,yearundstatus - Durch die Spaltenreduktion sind Duplikate entstanden, entfernen Sie diese
- Sortieren Sie nach Jahr und Status
Eine Lösung mit Zwischenschritten, bei denen die Arbeitsschritte
einzeln ausgeführt und jeweils in der Tabelle ergebnis
gespeichert werden, könnte so aussehen:
PYTHON
# Filtern nach Stürmen vor 1980
ergebnis = storms[storms['year'] < 1980]
# Reduzieren auf die Spalten name, year und status
ergebnis = ergebnis[['name', 'year', 'status']]
# Entfernen von Duplikaten
ergebnis = ergebnis.drop_duplicates()
# Sortieren nach Jahr und Status
ergebnis = ergebnis.sort_values(by=['year', 'status'])Eine Lösung, die alle Arbeitsschritte in einer Zeile zusammenfasst, könnte so aussehen:
PYTHON
ergebnis = storms[storms['year'] < 1980][['name', 'year', 'status']].drop_duplicates().sort_values(by=['year', 'status'])Diese Lösung ist durch Verkettung der Funktionsaufrufe (das sog. method chaining) in einer Zeile kürzer und kompakter, kann aber auch schwerer zu lesen. Um das übersichtlicher zu gestalten, kann man die Arbeitsschritte auch in mehreren Zeilen miteinander verketten. In Python setzt man dazu entweder den mehrzeiligen Befehl in eine umgreifende Klammer wie hier:
PYTHON
(storms
[storms['year'] < 1980]
[['name', 'year', 'status']]
.drop_duplicates()
.sort_values(by=['year', 'status']))AUSGABE
name year status
30 Amy 1975 extratropical
49 Blanche 1975 extratropical
111 Doris 1975 extratropical
156 Eloise 1975 extratropical
222 Gladys 1975 extratropical
.. ... ... ...
716 David 1979 tropical storm
773 Frederic 1979 tropical storm
839 Elena 1979 tropical storm
857 Gloria 1979 tropical storm
899 Henri 1979 tropical storm
[129 rows x 3 columns]… oder aber terminiert jede Zeile - bis auf die letzte - mit einem Backslash:
PYTHON
storms \
[storms['year'] < 1980] \
[['name', 'year', 'status']] \
.drop_duplicates() \
.sort_values(by=['year', 'status'])AUSGABE
name year status
30 Amy 1975 extratropical
49 Blanche 1975 extratropical
111 Doris 1975 extratropical
156 Eloise 1975 extratropical
222 Gladys 1975 extratropical
.. ... ... ...
716 David 1979 tropical storm
773 Frederic 1979 tropical storm
839 Elena 1979 tropical storm
857 Gloria 1979 tropical storm
899 Henri 1979 tropical storm
[129 rows x 3 columns]Beim Verketten der Arbeitsschritte wird ein Funktionsergebnis jeweils mit der nächsten Funktion weiterverabeitet. Man spart dadurch Zwischenvariablen und die Kette erlaubt es, aufgrund der aneinandergereiten Funktionsnamen den Verarbeitungsworflow sozusagen zu “lesen”.
Daten gruppieren und aggregieren
Gruppierung von Daten, also “Zerlegung” des Datensatzes in Teiltabellen, für die anschliessende Arbeitsschritte (z.B. Durchschnittswert für jede Gruppe berechnen) unabängig voneinander durchgeführt werden. Wird üblicherweise verwendet, wenn die Aufgabe “pro …” oder “für jede …” lautet, z.B. Anzahl der Stürme pro Jahr oder durchschnittliche Windgeschwindigkeit je Sturmkategorie.
-
storms.groupby("year")→ Gruppierung der Sturmdaten nach Jahr (aber noch keine Aggregation!); das ist nur ein Zwischenschritt, der die unterschiedlichen Werte der Jahre ermittelt und für die folgenden Arbeitsschritte bereitstellt -
storms.groupby("year").agg({"wind": "max", "name": "count"})→ maximale (max) Windgeschwindigkeit und Anzahl (count) der Datensätze (Zeilen); auch Mittelwert (mean), Median (median), Summe (sum), Minimum (min), erste bzw. letze Zeile (first/last), und andere sind möglich -
storms[storms['wind'] == storms.groupby('year')['wind'].transform('max')]→ alle Sturmdaten, bei denen die maximale Windgeschwindigkeit des jeweiligen erreicht wurde (keine Zusammenfassung!).
Man kann auch nach mehreren Spalten gruppieren und dann für jede Gruppe aggregieren. Folgendes Beispiel erzeugt einen Dataframe mit durchschnittlicher Windgeschwindigkeit pro Sturmstatus und Jahr
AUSGABE
wind
status year
disturbance 1980 20.555556
2010 37.142857
2011 33.000000
2013 25.512821
2014 23.333333
... ...
tropical wave 2005 28.125000
2011 25.714286
2012 30.000000
2017 27.083333
2018 33.500000
[305 rows x 1 columns]Gruppiertes Filtern
Erstelle eine Tabelle, welche für jeden Sturmstatus das Jahr und den Namen des letzten Sturms auflistet.
AUSGABE
status year name
16953 tropical wave 2018 Kirk
19614 subtropical depression 2023 Don
20717 extratropical 2024 Patty
20724 subtropical storm 2024 Patty
20751 hurricane 2024 Rafael
20757 other low 2024 Rafael
20759 disturbance 2024 Sara
20775 tropical storm 2024 Sara
20777 tropical depression 2024 SaraHier gibt es viele Wege, das Ziel zu erreichen. Am einfachsten ist es in diesem Fall, wie folgt vorzugehen:
- Sortieren des Dataframe die Daten nach Jahr, Monat und Tag
- Dann entfernen der Duplikate von Status und jeweils behalten der Zeile je Status mit dem höchsten Datum
- Auswahl der Spalten für Status, Jahr und Name
Hier die Lösung nach dem Verfahren, das unter Hinweise oben angegeben wurde:
PYTHON
last_storm_of_year = storms \
# Sortierung nach Jahr, Monat, Tag aufsteigend
.sort_values(["year", "month", "day"]) \
# Duplikate von Status entfernen und jeweils die letzte Zeile (keep="last") behalten
.drop_duplicates("status", keep="last") \
# Auswahl der Spalten status, year und name
[["status", "year", "name"]]Alternativ kann man das auch mit Gruppieren und Aggregieren lösen.
Hierbei sollte zunächst sichergestellt werden, dass die Datumsangaben
aufsteigend sortiert werden, dann wird nach status
gruppiert und für jede Gruppe mittels die letzte Zeile
(year="last", also aufgrund der aufsteigenden Sortierung
die mit dem höchsten Datum) ausgewählt. Das reset_index()
am Schluss ist optional, um den Index zurückzusetzen, weil ansonsten
noch aus der Gruppierung stammende nicht-numerische Indexeinträge
entsprechend des status vorhanden sind.
PYTHON
last_storm_of_year = storms \
# Sortieren nach Datum aufsteigend
.sort_values(["year", "month", "day"]) \
# Gruppierung nach Status
.groupby("status") \
# Aggregation: Auswahl der Zeile mit dem höchsten Datum
.agg({"year": "last", "name": "last"}) \
# Optional: Index zurücksetzen
.reset_index()Haben Sie eine andere Lösung gefunden?
Tabellengestalt ändern
Die “tidy” Form ist eine spezielle Form von tabellarischen Daten, die für viele Datenverarbeitungsschritte geeignet ist. In der “tidy” Form sind die Daten so organisiert, dass jede Beobachtung (z.B. Messung) in einer Zeile notiert ist und jede Variable (also z.B. Beschreibungungen und Messwerte) eine Spalte definieren. Diese Art der Tabellenform wird auch “long table” oder “schmal” genannt, weil die Daten in einer langen, schmalen Tabelle organisiert sind. Dies ist beispielsweise der Fall bei den Sturmdaten, die wir bisher verwendet haben.
Allerdings werden Rohdaten häufig in einer “ungünstigen” Form vorliegen, die für die weitere Verarbeitung nicht optimal ist. Manuelle Datenerfassung erfolgt oft in grafischen Oberflächen wie MS Excel, worin die Daten i.d.R. in einer “breiten” oder “wide table” Form gespeichert, in der eine Variable (z.B. Messwert) in mehreren Spalten gespeichert ist. In der “breiten” Form sind die Daten so organisiert, dass Beobachtungen (und ihre Messwerte) in Spalten gruppiert sind, während die Variablen in den Zeilen stehen.
Man kann nun einen Dataframe von der “breiten” in die “schmale” Form
umwandeln mit der Funktion pivot(). Diese erwartet folgende
Parameter:
-
index: jene Spalte bzw. Spalten des Dataframe, die in der “breiten” Form als Index für die Zeilen dienen sollte; es muss sichergestellt sein, dass die Werte in dieser Spalte bzw. die Kombinationen der Werte der Spalte eindeutig sind -
columns: jene Spalte des Dataframe, die in der “breiten” Form für die weiteren Spalten dienen sollte -
values: jene Spalte des Dataframe, die in der “breiten” Form für die Werte in den Zellen dienen sollte
Ein Beispiel für die Umwandlung der Sturmdaten von der “breiten” in die “schmale” Form auf Grundlage des Dataframes, der das Ergebnis der letzten vorherigen Aufgabe war:
AUSGABE
status year name
0 tropical wave 2018 Kirk
1 subtropical depression 2023 Don
2 extratropical 2024 Patty
3 subtropical storm 2024 Patty
4 hurricane 2024 Rafael
5 other low 2024 Rafael
6 disturbance 2024 Sara
7 tropical storm 2024 Sara
8 tropical depression 2024 SaraWir wollen in der pivotierten Tabelle, dass die Zeilen wie gehabt den Sturmstatus entsprechen, die Spalten den Stürmen und die Werte in den Zellen den Jahren, in denen der Sturm der letzte mit diesem Status war. Das erreichen wir mit folgendem Code:
PYTHON
broad_table = last_storm_of_year \
.pivot(index="status", columns="name", values="year") \
.fillna("")
print(broad_table)AUSGABE
name Don Kirk Patty Rafael Sara
status
disturbance 2024.0
extratropical 2024.0
hurricane 2024.0
other low 2024.0
subtropical depression 2023.0
subtropical storm 2024.0
tropical depression 2024.0
tropical storm 2024.0
tropical wave 2018.0 Hinweis: fillna("") füllt leere Zellen mit einem leeren
String, um die Ausgabe übersichtlicher zu gestalten. Ansonsten würde da
NaN stehen, was für Not a Number steht.
Eine breite Tabelle in eine schmale tidy Tabelle verwandelt man mit
der Funktion .melt(). Ein Beispiel für die Rück-Umwandlung
der breiten Sturmdaten in schmale Form:
PYTHON
narrow_table = broad_table
# Zunächst Index zurücksetzen, um Status als Spalte zu haben
.reset_index() \
# Umwandlung in schmale Form mit Spalten status, name, year
.melt(id_vars="status", var_name="name", value_name="year") \
# Zeilen mit leeren Werten entfernen
.dropna()
print(narrow_table)AUSGABE
unexpected indent (<string>, line 3)Hinweis: .dropna() am Ende ist hilfreich, da sonst beim
Umwandeln die leeren Zellen der breiten Tabelle als NaN in
der schmalen Tabelle stehen würden. Probieren Sie es gerne ohne
.dropna() aus, um den Unterschied zu sehen.
Vor- und Nachteile
Während das wide table Format kompakter und damit ggf. besser zur Datenerfassung und -übersicht geeignet ist, ist das long table Format besser für die Datenanalyse und -visualisierung geeignet. In letzterem liegt Information redundant vor, da in jeder Zeile die komplette Information einer Beobachtung vorliegen muss.
Fehlende Daten füllen
Manchmal muss man mit Dataframes arbeiten, wo aufeinanderfolgende
Zellen einer Spalte fehlende Werte haben. Das kann z.B. passieren, wenn
bei der Datenerfassung nicht alle Werte erfasst wurden, oder - was öfter
der Fall sein wird - die leeren Zellen einfach bedeuten, dass sich der
Wert nicht geändert hat. Betrachten wir folgendes Beispiel des Dataframe
career, in dem akademische Abschlüsse und Arbeitstiteln von
Personen in einer Tabelle nach Jahrenzahlen, in denen sich etwas
geändert hat, gespeichert sind. Wir erinnern uns, dass NaN
inder Ausgabe für einen fehlenden Zellwert steht:
AUSGABE
degree title
year
2000 Bachelor Assistent
2001 NaN NaN
2002 NaN NaN
2003 Master NaN
2004 NaN Gruppenleiter
2005 NaN NaN
2006 Dr. NaN
2007 NaN NaN
2008 NaN KonzernchefHier können wir davon ausgehen, dass die Person auch in den Jahren
2001-2003 einen Bachelortitel hatte. Gleiches gilt für die Spalte
degree. Möchte man das explizit machen im Dataframe, so
hilft die Funktion ffill(), die man sowohl für den gesamten
Dataframe als auch für einzelne Spalten aufrufen kann. Ein Beispiel für
das Füllen der fehlenden Werte in allen Spalten des Dataframe:
AUSGABE
degree title
year
2000 Bachelor Assistent
2001 Bachelor Assistent
2002 Bachelor Assistent
2003 Master Assistent
2004 Master Gruppenleiter
2005 Master Gruppenleiter
2006 Dr. Gruppenleiter
2007 Dr. Gruppenleiter
2008 Dr. KonzernchefMöchte man das z.B. nur für die Spalte title, so kann
man schreiben:
career["title"] = career["title"].ffill().
Tabelleninhalte verändern
Um Datentypen oder Inhalte von Zellen zu verändern, gibt es verschiedene Funktionen, je nachdem welchen Datentyp die jeweilige Spalte des Dataframe hat.
Datentypen verändert man mit der Funktion astype(), die
den Datentyp einer Spalte ändert. Die Funktion erwartet als Argument den
neuen Datentyp, z.B. int, float,
str, bool, datetime,
category, etc. Ein Beispiel für die Umwandlung der
ganzzahligen Spalte year in eine Textspalte:
Um die Inhalte von Zellen zu verändern, gibt es unter je nach Datentyp verschiedene Funktionen. Am interessantesten dabei die Funktion für die Manupulation von Textspalten. Hier einige nützliche:
-
str.replace(): ersetzt einen Teil eines Strings durch einen anderen, beispielsweise würdedf["preis"].str.replace("€", "$")in der Spaltepreiseines Dataframes alle Euro-Zeichen durch Dollar-Zeichen ersetzen -
str.lower(),str.upper(): wandelt alle Buchstaben in Klein-/Grossbuchstaben um -
str.strip(): entfernt Leerzeichen am Anfang und Ende eines Strings -
str.extract(): extrahiert einen Teil eines Strings, der einem gegebenen regulären Ausdruck entspricht. Will man beispielsweise nur die letzten beiden Stellen der Jahreszahl in der Spalteyearextrahieren:storms["year"].str.extract("(\\d{2})$"). Der jeweils gefundene Wert innerhalb der Klammern wird dabei extrahiert, hier also die letzten beiden Ziffern ((\\d{2})) ganz am Ende ($) der Jahreszahl. -
str.split(): teilt einen String an einem bestimmten Trennzeichen auf. Hat man beispielsweise einen Dataframepersonsin dem in der Spaltenameder volle Name steht, und möchte diesen in eine neue Vor- und Nachnamenspalte auftrennen, kann man das mitpersons[["vorname", "nachname"]] = persons["name"].str.split(" ", expand=True)erreichen.
Reguläre Ausdrücke
Anstatt wie oben die letzten beiden Ziffern der Jahreszahl zu extrahieren, wollen wir das Jahrhundert extrahieren. Dazu benötigen wir einen regulären Ausdruck, der die ersten beiden Ziffern der Jahreszahl extrahiert. Wie sieht dieser Aufruf dann aus?
Der reguläre Ausdruck, der die ersten beiden Ziffern der Jahreszahl
extrahiert, sieht so aus:
storms["year"].str.extract("^(\\d{2})"). Der Unterschied
zum vorherigen regulären Ausdruck ist das ^, das den Anfang
des Strings markiert. Möchte man dann auch noch das extrahierte
Jahrhundert in eine Ganzzahl umwandeln, so kann man noch
.astype(int) anhängen.
- In pandas lassen sich sowohl ganze Zeilen, ganze Spalten, oder einzelne Zellbereich(e) bequem manipulieren
- Oft ist es nötig, die Tabellengestalt zu verändern, etwa von breit zu schmal oder umgekehrt, um Analysen und Transformationen einfacher durchführen zu können
- Versuchen sie die Datenverarbeitung in kleine, leicht verständliche Schritte zu unterteilen.
- Wenn man pandas verwendet, vermeidet man Schleifen und Schachtelungen. Solche Manipulationen macht man in pandas mit dafür geeigneten Funktionsaufrufen. Das meiste lässt sich mit Gruppieren, Aggregieren und Spaltenmanipulation erreichen.
- Das pandas Cheatsheet kann helfen, die Funktionen und Methoden von Pandas zu verstehen und zu nutzen.
Content from Visualisierung
Zuletzt aktualisiert am 2026-07-03 | Diese Seite bearbeiten
Geschätzte Zeit: 25 Minuten
Übersicht
Fragen
- Wie visualisiere ich Daten?
Ziele
- Datenvisualisierung mit Dataframes und
plotninein Python
Die Visualisierung von Daten ist ein wichtiger Bestandteil der
Datenanalyse, da sie es ermöglicht, Muster und Zusammenhänge in den
Daten zu erkennen und zu kommunizieren. In Python gibt es mehrere Pakete
für Datenvisualisierung. Ein beliebtes, das wir auch hier vorstellen
werden, ist plotnine, das auf ggplot2 und der Grammar of
Graphics basiert. Hierbei müssen die Daten in tabellarischer
Form vorliegen, d.h. jede Zeile entspricht einem Datensatz und jede
Spalte einer Variable (“tidy data”).
Die Visualisierung von Daten wird in verschiedene Schichten (z.B.
Punkte, Linien, Balken) und Eigenschaften (z.B. x-Achse, y-Achse, Farbe,
Form) unterteilt. Die Verküpfung von Tabellenspalten mit den Ebenen und
Eigenschaften (d.h. Welche Information wird wie fürs Plotting verwendet)
erfolgt über die Funktion aes(), was für aesthetic
mapping steht. Geometrische Schichten (z.B. Balken, Linien, Punkte)
werden mit geom_*() Funktionen hinzugefügt.
Im Folgenden wird ein umfangreiches Beispiel für die Visualisierung
von Daten mit plotnine gezeigt, bei dem die Anzahl der
Stürme pro Jahr visualisiert wird.
PYTHON
import pandas as pd
# Alle Funktionen des Pakets plotnine importieren:
from plotnine import *
# Sturmdaten aus dem Internet laden
storms = pd.read_csv("https://raw.githubusercontent.com/tidyverse/dplyr/master/data-raw/storms.csv")
# Zunächst einen Dataframe mit der Anzahl der Stürme pro Jahr erstellen
storms_per_year = (storms
# Duplikate entfernen um nur die Spalten "year" und "name" behalten
.drop_duplicates(["year", "name"])
# Gruppieren nach Jahr
.groupby("year")
# Anzahl der Stürme ermitteln
.agg({"name": "count"})
# Index zurücksetzen
.reset_index()
# Anzahl-Spalte umbenennen in "storm_count"
.rename(columns={"name": "storm_count"})
)
# Plot erstellen
plot = (ggplot(storms_per_year, mapping=aes(x="year", y="storm_count"))
# Diagrammtitel und Achsenbeschriftung
+ labs(title="Anzahl der Stürme pro Jahr", x="Jahr", y="Anzahl")
# grundlegende Diagrammformatierung
+ theme_minimal()
# Balkendiagramm mit Anzahl der Stürme pro Jahr
+ geom_bar(fill="skyblue", stat="identity")
# gepunktete horizontale Linie bei 20
+ geom_hline(yintercept=20, linetype="dotted", color="red")
# Highlighting der Jahre mit mehr als 20 Stürmen
+ geom_vline(
data=lambda x: x[x["storm_count"] > 20],
mapping=aes(xintercept="year"),
color="red" # Schriftfarbe rot
)
# Jahreszahlen der Jahre mit mehr als 20 Stürmen in schräger Textausrichtung
+ geom_text(
data=lambda x: x[x["storm_count"] > 20],
mapping=aes(label="year", x="year", y="storm_count"),
angle=70, # Schräge Textausrichtung
nudge_y=1, # Text leicht nach oben versetzen
nudge_x=-0.8, # Text leicht nach links versetzen
size=8, # Schriftgröße 8
color="red" # Schriftfarbe rot
)
)
# Plot anzeigen
plot.show()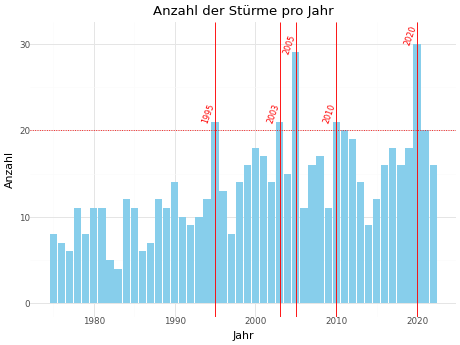
PYTHON
# optional: Diagramm als Bilddatei speichern
plot.save("storms_per_year.png", width=10, height=10, dpi=300)Als Nachschlagewerk für alle verfügbaren und im Beispiel verwendeten Funktionen empfiehlt sich die plotnine Dokumentation, in der die Funktionen gruppiert nach deren Zweck gelistet und detailliert beschrieben sind.
Einen empfehlenswerten Cheatsheet für plotnine gibt es leider nicht, aber es gibt ein Cheatsheet für ggplot2, das einen guten Überblick über die ggplot-Funktionen enthält. Das Cheatsheet enthält einige für die Programmiersprache R spezifische Zeilen, aber die meisten Funktionen sind auch in plotnine verfügbar mit gleicher oder ähnlicher Syntax in Python:

Bei der Anpassung von ggplot2 Beispielen an plotnine empfehlen sich die Heuristics for Translating Ggplot2 Code to Plotnine Code von Jeroen Janssens.
Sturmposition visualisieren
Zeichnen sie ein Punktdiagram, welches für folgenden Datensatz
- Längengrad (x-Achse) und Breitengrad (y-Achse) der Messung zeigt und die Punkte anhand des Sturmstatus einfärbt,
- die Achsen mit “Längengrad” und “Breitengrad” beschriftet, und
- den Diagrammtitel “Sturmposition” hat.
PYTHON
mesaurements = storms.drop_duplicates(["name", "year"], keep="last")
plot = (ggplot(mesaurements, mapping=aes(x="long", y="lat", color="status"))
+ geom_point()
+ labs(
title="Sturmposition",
x="Längengrad",
y="Breitengrad",
color="Status" # ansonsten wird status kleingeschrieben
)
)
plot.show()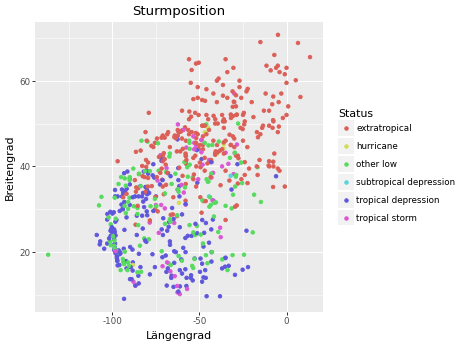
Alternativ zu + labs() können die se Informationen auch
separat mit den Funktionen geom_title(),
geom_xlab(), geom_ylab() und
geom_color() hinzugefügt werden. Sie können auch versuchen,
alle Sturmmessungen zu visualisieren, anstatt nur die letzten Messungen
pro Sturm zu verwenden, dann sind die Sturmpfade sichtbar.
-
plotninebenötigt einen pandas Dataframe als Eingabe, der “tidy” ist (d.h. eine Zeile pro Beobachtung und eine Spalte pro Variable). - Das
mappingArgument ermöglicht mittels deraes()Funktion die Verknüpfung von Variablen des Datensatzes (d.h. Spaltennamen) mit visuellen Eigenschaften (z.B. x-Achse, Farbe, Größe). -
geom_*Funktionen fügen dem Plot Schichten hinzu (z.B. Punkte, Linien, Balken). -
labs()ermöglicht die Anpassung von Diagrammtitel und Achsenbeschriftung. -
theme_*Funktionen ermöglichen die Anpassung genereller Diagrammformatierungen (z.B. Hintergrundfarben, Schriftarten). - Es gibt viele weitere Funktionen und Argumente, um die Darstellung
von Diagrammen zu verfeinern (z.B.
facet_wrap(),scale_*(),coord_*()). - Diagramme können mit
save()in beliebigem Dateiformat (PNG, PDF, SVG, ..) gespeichert werden. - Zusammenfassung im
ggplot2Cheat Sheet