Alles auf einen Blick
Content from Vorbesprechung
Zuletzt aktualisiert am 2026-05-12 | Diese Seite bearbeiten
Übersicht
Fragen
- Was ist Datenmanagement?
- Was ist digitale Selbstbestimmtheit?
- Warum ist eine selbst gehostete Datenmanagementlösung gut?
Ziele
- Thematische Einleitung
- Vorstellung der Ziele und Inhalte des Kurses
- Voraussetzungen, die Sie mitbringen sollten
- Informationen zum Ablauf des Kurses
Thematische Einleitung
Datenmanagement im wissenschaftlichen Kontext
Der Begriff des Forschungsdatenmanagements (FDM) umschreibt den Umgang mit Forschungsdaten (z.B. Messdaten, Bilder, Artikel, Interviewdaten u.v.m.) innerhalb von Forschungsprojekten. Dabei beginnt FDM bei der Planung von Projekten, legt Standards für das Erstellen, Analysieren und Publizieren fest und sorgt durch strukturierte Archivierung für eine nachhaltige Speicherung und die Möglichkeit der Nachnutzung der Forschungsdaten.
Mehr zum Thema FDM finden Sie z.B. hier, hier oder im Kurs FDM Basics
Um während der aktiven Forschungsarbeit seine Daten strukturiert und zugänglich speichern zu können und mit anderen Projektteilnehmenden kollaborieren zu können, sind online Dateispeicherung und online Dateibearbeitung essentiell.
Häufig werden hierfür die Angebote großer Tech-Konzerne aus dem Ausland genutzt. Es gibt aber auch die Möglichkeit solche Lösungen selbst zu betreiben. Dadurch ist der Datenschutz gewährleistet, da keine Daten außerhalb der EU gespeichert werden. Außerdem ist man unabhängig von den vermeintlich günstigen Angeboten der Tech-Konzerne.
Die Probleme, die eine solche Abhängigkeit auch im privaten Alltag herbeiführen, erfahren Sie in der folgenden Aufgabe.
Aufgabe 1: Mark und sein Sohn
Lesen Sie den folgenden Artikel: SPIEGEL: Autoupload in die Google-Cloud
Welche grundlegenden Probleme führten zu Marks Situation?
In diesem Fall ist einiges schief gelaufen. Wir werden darüber in der ersten Präsenzsitzung diskutieren.
Auf jeden Fall hat Mark jedoch seine informationelle Selbstbestimmung aufgegeben.
Informationelle Selbstbestimmtheit
Unter dem Begriff informationelle Selbstbestimmtheit wird verstanden, dass Personen selbst über ihre Daten bestimmen können. Das Bundesverfassungsgericht hat dazu bereits 1983 geurteilt:
“Das Grundrecht gewährleistet insoweit die Befugnis des Einzelnen, grundsätzlich selbst über die Preisgabe und Verwendung seiner persönlichen Daten zu bestimmen.”
Aber wie können wir selbst über die Preisgabe unserer Daten bestimmen?
Digitale Mündigkeit
Um selbst über seine Daten zu bestimmen, sollte man die Daten und deren Zustandenkommen verstehen. D.h. angewendete Technik sollte verstanden und hinterfragt werden. Stimmt etwas nicht, sollte Kritik geübt werden oder ggf. nach Alternativen gesucht werden. Fragen Sie sich beim Einsatz digitaler Tools immer:
Welche Daten gibt es?
Wann entstehen welche Daten?
Wer hat Zugriff auf diese Daten?
Welche Daten möchte ich wem preis geben und welche behalte ich für mich?
Wie digital mündig sind Sie?
Lesen Sie den folgenden Artikel von Digitalcourage
Welche der im Artikel genannten Punkte setzen Sie bereits um? In welchen Bereichen können Sie noch “mündiger” werden?
Nutzen Sie ein kostenloses E-Mailpostfach? Speichern Sie Daten in verdächtig günstigen Onlinespeichern? Wie abhängig sind Sie von Big Tech (Apple, Google, Amazon, Microsoft)?
Mehr zum Thema digitale Mündigkeit findet sich auch bei Simon 2024 1
Digitale Selbstbestimmtheit
Zu einem selbstbestimmten Leben gehört auch eine digitale Selbstbestimmtheit.
Deshalb:
eingesetzte Technik verstehen
Open-Source statt Closed Source
Community statt Großkonzern
Noch mehr zu digitaler Selbstbestimmtheit und Selbstverteidigung
Noch mehr Informationen zum Thema finden Sie bei Interesse unter anderem bei den folgenden Quellen:
E. Snowden, Permanent Record - Meine Geschichte, (Berlin 2019)
J. Caspar, Wir Datensklaven - Wege aus der digitalen Ausbeutung, (Berlin 2023)
Ziele und Inhalte des Kurses
Allgemeine Ziele
Einstieg die Linux-(Server)-Welt
Weniger Angst vor Technik (und Fehlern)
Einstieg in die Systemadministration
Einrichten einer selbst betriebenen Webanwendung zur Dateiverwaltung (“Cloud”) mittels Docker
Inhaltliche Schwerpunkte
- Betriebssystem: Installation und grundlegende Verwaltung:
Wir beginnen ganz am Anfang mit der Installation und dem Kennenlernen des Linux-Betriebssystems. Wir nutzen dazu das Betriebssystem Ubuntu in der Servervariante, welches wiederum auf dem Debian-Betriebssystem aufbaut.
- Sicherheit: Backup, Firewall, Fern-Zugriff:
Vor der Installation der eigentlichen Cloud-Software muss der Server eingerichtet werden. Dazu zählen z.B. Funktionen zum Fernzugriff (SSH), verschiedene Techniken zum Absichern des Servers (Firewall, Benutzer und Zugriffsrechte) aber auch das Thema Backup.

- Docker und Webserver
Im zweiten Teil des Kurses liegt der Fokus auf Webservern, mit welchen Webanwendungen verfügbar gemacht werden und Docker, mit welchem Software unabhängig vom Betriebssystem installiert und konfiguriert werden kann. Als Webserver werden wir mit Apache2 und NGINX arbeiten und lernen, wie wir TLS-Zertifiakte zur Sicherung der Webanwendung erhalten.
- Nextcloud und mehr Services
Im dritten Teil des Kurses werden die zuvor erlernten Grundlagen angewendet, um mit Docker die Kollaborationsplattform Nextcloud und andere spannende Webanwendungen zu installieren und zu konfigurieren.
Voraussetzungen
Allgemeine Voraussetzungen
Sie sollten sicher mit Ihrem PC (Windows oder Linux) oder Ihrem Mac umgehen können
Sie sollten keine Angst vor Technik und der Kommandozeile haben
Sie benötigen ein Notebook oder Tablett mit Tastatur (keine Touch-Geräte).
Zugriff mit Ihrem Gerät auf das Eduroam- und das VPN-Netzwerk der Universität Tübingen
Technische Voraussetzungen
Allen Teilnehmenden wird ein virtueller Server im Rechenzentrum der Universität zur Verfügung gestellt. Sie benötigen keinen eigenen Server. Sollten Sie die im Kurs erlangten Kenntnisse später auf eigener Hardware umsetzen wollen, eignen sich Einplatinen-Computer (System-on-Chip, kurz SoC) wie ein Raspberry Pi 5.
Organisatorisches
Wöchentlicher Ablauf:
Die Wochen laufen i.d.R. wie folgt ab:
- Sie arbeiten das Selbstlernmaterial auf Github durch
Sie setzen die Arbeitsschritte selbstständig auf Ihrem Server um. Dazu können Sie zum Übungstermin kommen.
Sie kommen am Ende jeder Studieneinheit (3x pro Semester) zu einem Vertiefungsgespräch
Leistungsnachweis
Bei erbrachter Leistung erhalten Sie für diesen Kurs 3 ECTS-Punkte
Der Kurs ist anrechenbar für das Zertifikat Data Literacy im Wahlbereich praktische Anwendungen
-
Die erforderlichen Leistungen sind:
wöchentliche Bearbeitung der Lernmaterialien
selbstständige Konfiguration eines Cloud-Servers
3 Vertiefungsgespräche im Semester
Verfassen eines Abschlussberichts (ca. 3-4 Seiten)
Der Workload beträgt entsprechend 3 ECTS ca. 90 Stunden im Semester. Davon entfallen ca. 21 Stunden auf die Übungen, 9 Stunden auf den Abschlussbericht und 60 Stunden auf die Vor- und Nachbereitung der Sitzungen inkl. den Vertiefungsgesprächen. D.h. pro Woche müssen Sie während der Vorlesungszeit durchschnittlich ca. 4,3 Stunden Arbeitszeit zusätzlich zu den Übungssitzungen einplanen.
Mehr Informationen folgen in der ersten Präsenzsitzung.
- Die eigene Cloud schützt die Privatsphäre und reduziert die Abhängigkeit von großen Monopolisten
- Der Kurs begleitet Sie vom Linux Betriebssystem über die Grundkonfiguration des Servers bis hin zur Installation und Konfiguration des eigenen Cloudservers im Docker Container
- Sie müssen jede Woche Selbstlernmaterial durcharbeiten und die praktischen Aufgaben absolvieren
- Am Ende des Kurses müssen Sie noch einen Abschlussbericht verfassen
- Für den Kurs erhalten Sie 3 ECTS-Punkte
L. Simon, Digitale Mündigkeit - Wie wir mit einer neuen Haltung die Welt retten können, (Bielefeld 2024)↩︎
Content from Betriebssystem und Linuxgrundlagen
Zuletzt aktualisiert am 2026-05-12 | Diese Seite bearbeiten
Übersicht
Fragen
Wie wähle ich die richtige Hard- und Software aus?
Wie installiere ich ein Linux-Betriebssystems?
Wie bediene ich ein Linux-Betriebssystem?
Ziele
- Begriffsklärung
- Betriebssystem installieren
- Grundlagen mit der Linux-Kommandozeile
Die Hard- und Software
Hardware
Zu Beginn der meisten IT-Projekte steht die Frage, wo diese Projekte umgesetzt werden sollen. Dabei gibt es heutzutage unterschiedliche Möglichkeiten. Abgesehen von Tests auf lokalen Endgeräten wie PC oder Notebook, werden für viele Projekte spezialisierte Geräte genutzt. Vor allem für Firmen, Rechenzentren und andere Hochleistungsszenarien werden Computer mit spezialisierter Hardware (Prozessoren, Festplatten, Arbeitsspeicher oder RAID-Controller) eingesetzt, die für diese anspruchsvollen Aufgaben geeignet ist und häufig nicht mit Endanwender-Hardware vergleichbar ist.
Neben eigener Hardware besteht heute auch die Möglichkeit, seine Projekte auf fremder Hardware umzusetzen. Diese fremde Hardware befindet sich in einem entfernten Rechenzentrum (“der Cloud”) und ist über das Internet erreich- und steuerbar. Häufig wird die Hardware dabei virtualisiert, d.h. dass z.B. die Leistung eines echten Prozessors mithilfe von Software für mehrere virtuelle Computer zur Verfügung gestellt wird.
Für dezentrale Projekte können sogenannte Embedded Devices genutzt werden. Hierbei handelt es sich häufig um Spezialanfertigungen für genau einen Einsatzzweck, z.B. als Kassensystem oder Waage im Supermarkt oder als Informationsdisplay im öffentlichen Raum. Für diese Geräte werden auch spezielle Betriebssysteme und Software eingesetzt.
Für kleinere Projekte wie Heimanwender können normale PCs genutzt werden. Passender für Projekte mit wenig Leistungsanspruch (und im Heimanwenderbereich ist das i.d.R. der Fall) sind Mini-PCs, bei denen sämtliche oder die meisten Bauteile (Prozessor, Arbeitsspeicher, Datenspeicher und externe Schnittstellen wie Netzwerk und USB) auf einer Platine verbaut sind. Diese sogenannten Systems-on-a-Chip (SoC) haben den Vorteil, dass sie besonders energiesparsam sind, wenig Platz benötigen, keinen oder kaum Lärm verursachen und im Vergleich mit herkömmlichen PCs oder gar professionellen Servern deutlich günstiger sind.
Server vs. Client
Bezogen auf ihre Funktion innerhalb eines Computernetzwerks werden Geräte unterschiedlich bezeichnet:
- Client
Klassisches Endgerät wie PC, Notebook oder Smartphone. Hat keine zentralen Aufgaben. Ist ein Client-Gerät ausgefallen, ist das Netzwerk nicht betroffen.
- Server
Übernimmt als Kommunikationsknotenpunkt zentrale Aufgaben im Netzwerk. Je nach Leistungsbedarf werden spezialisierte Hochleistungshardware, normale PCs oder SoCs genutzt. Fällt ein Server aus, fehlt damit i.d.R. eine zentrale Funktion im Netzwerk. Je nachdem welche Aufgaben der Server hat, kann dies zum vollständigen versagen des Netzwerks führen oder nur zum Ausfall eines Dienstes (z.B. einer Website).
Software
Unter Software kann all das verstanden werden, was nicht angefasst werden kann. Also sämtlicher Programmcode, der auf einem Computer installiert ist. Dazu gehört sowohl das Betriebssystem, die Boot-Umgebung (welche das Betriebssystem lädt) aber auch alle anderen Programme wie Treiber, eine Firewall, ein Office-Programm oder ein Webserver-Programm.
Möchte man ein bestimmtes IT-Projekt umsetzen und hat die Hardware besorgt, gilt es auch die richtige Software auszuwählen. Hierbei ist zu beachten, dass Hard- und Software miteinander kompatibel sein müssen. Z.B. unterstützt nicht jedes Betriebssystem jede Art von Prozessor (siehe auch diesen Wikipedia-Artikel).
Abhängig von den Programmen, die man nutzen möchte, kann das passende Betriebssystem gewählt werden. Für viele Serveranwendungen, wie die in diesem Kurs genutzte Software Nextcloud, werden Linux-Betriebssysteme empfohlen. In vielen Fällen werden für die Funktion des Hauptprogramms weitere Programme benötigt. Das sind häufig ein Datenbankmanagementsystem wie Mysql oder MariaDB, die Skriptsprache PHP, und ein Webserver wie Apache2. In dieser Kombination spricht man auch von einem LAMP-Stack (Linux, Apache, Mysql/MariaDB und PHP).
Die genauen Anforderungen an die Hard- und Software sind häufig den Handbüchern der Programme zu entnehmen. Allerdings hängt die richtige Wahl auch von der Intensivität der Nutzung, persönlichen Vorlieben oder Vorgaben innerhalb einer Organisation ab.
System requirements
Szenario: Sie wollen für eine kleine Forschungsgruppe (ca. 10 Personen) eine Datenmanagement-Lösung betreiben und als Serversoftware Nextcloud installieren.
Welche Hardware wählen Sie dafür? Schauen Sie sich dafür die System requirements von Nextcloud an und wählen Sie aus einer der folgenden Hardware-Optionen:
Raspberry Pi 4 mit 8GB RAM für ca. 100€ und einer externen 2 TB USB-HDD-Festplatte
Raspberry Pi 5 mit 8GB RAM für ca. 110€ und einer 2 TB SSD-Festplatte
Odroid H4 Ultra mit einer 2 TB SSD-Festplatte
Einen Tower Server Intel RI1104-SMXEH Serie
Die genauen Hardwareanforderungen sind (v.a. am Anfang des Projekts und ohne Vorkenntnisse) schwer abzuschätzen. Geeignete Lösungen können aber die Nummern 2. und 3. sein. Die Nummer 4 wäre überdimensioniert und mit der Nummer 1. kommt das System an seine Grenzen. Auch der Raspberry Pi 5 ist für 10 Personen vermutlich zu schwach. Das hängt aber stark von der Art und der Intensivität der Nutzung ab.
Installation des Betriebssystems
Um ein Betriebssystem neu zu installieren, muss beim Starten des PCs/Servers (egal ob virtualisiert oder als physisches Gerät) ein bootbares Medium mit den Installationsdateien angeschlossen und beim Startvorgang ausgewählt werden.
In diesem Kurs wird mit virtuellen Servern gearbeitet, die mit der Virtualisierungsplattform Proxmox betrieben werden. Beim Start Ihres Servers ist bereits ein Installationsmedium eingebunden und als Startmedium hinterlegt.
Loggen Sie sich in der Proxmox-Webconsole ein und wählen Sie Ihren Server im rechten Menü aus. Gehen Sie nun im vertikalen Menü der virtuellen Maschine in den Bereich Console und klicken Sie im Konsolen-Fenster auf starten. Die virtuelle Maschine startet und der Ubuntu-Installationsassistent leitet durch die Installation des Servers.
Installationsassistent
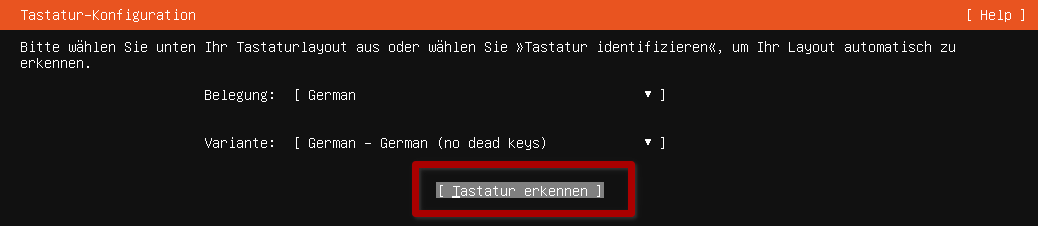
Die meisten Schritte sind selbsterklärend und können für den Einsatz in diesem Kurs auf dem Standardwert belassen werden. Vorsicht ist aber bei der Wahl des richtigen Tatstaturlayouts walten zu lassen. Nutzen Sie am besten die Möglichkeit der Tastaturerkennung.
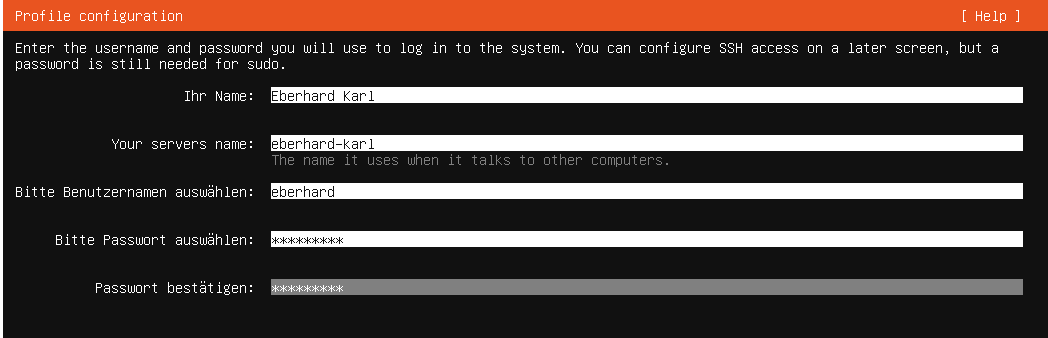
Bei der Erstellung des ersten Benutzerprofils ist auf folgendes zu achten:
Name: Der Name des Benutzers sollte der natürliche Name der Person sein, die das System verwenden wird.
Servername (Hostname): Der Servername, auch Hostname genannt, ist der eindeutige Name des Servers im Netzwerk. Er sollte nur aus Kleinbuchstaben bestehen und keine Leerzeichen enthalten. Der Hostname dient zur Identifikation des Servers und sollte sinnvoll gewählt werden, um Verwechslungen zu vermeiden.
Benutzername: Der Benutzername sollte ebenfalls nur aus Kleinbuchstaben bestehen und keine Leerzeichen enthalten. Dies stellt sicher, dass der Benutzername in allen Systemkomponenten korrekt erkannt und verarbeitet wird.
Passwort: Im Produktivbetrieb sollte das Passwort mindestens 20 Zeichen lang sein. Ein starkes Passwort erhöht die Sicherheit des Systems und schützt vor unbefugtem Zugriff. Es wird empfohlen, eine Kombination aus Groß- und Kleinbuchstaben, Zahlen und Sonderzeichen zu verwenden.
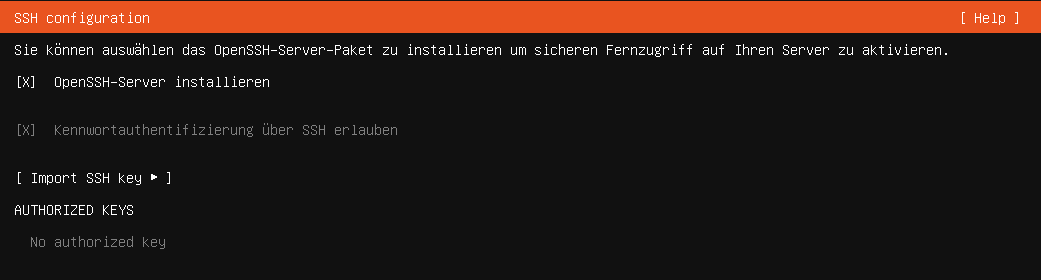
Wählen Sie außerdem die Option, den SSH-Server (Secure Shell) zu installieren. Der SSH-Server ermöglicht einen sicheren Fernzugriff zu Ihrem Server, um ihn zu Administrieren. Mehr dazu folgt in den nächsten Sitzungen.
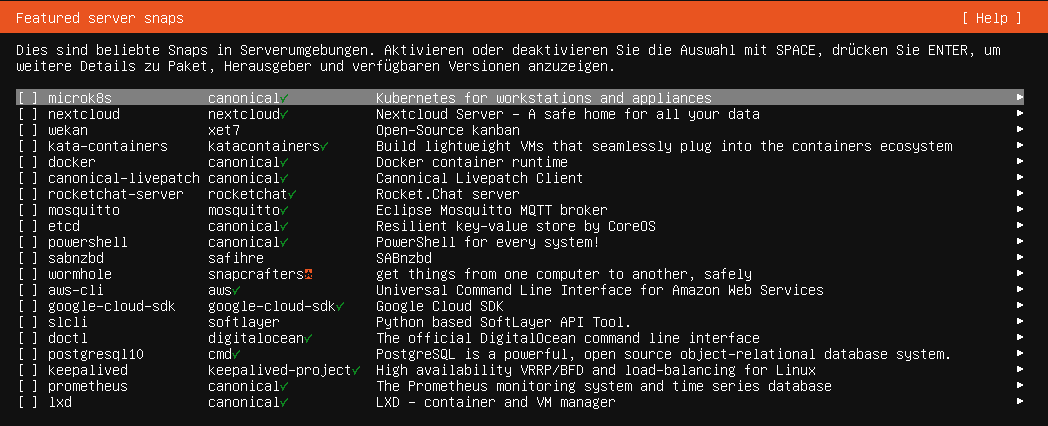
Achten Sie darauf, dass Sie keine Snap-Pakete installieren. Snap-Pakete sind speziell verpackte Programme von Ubuntu, die einfach zu installieren sind und in einer isolierten Umgebung ausgeführt werden. Allerdings bieten Snap-Pakete aufgrund ihrer isolierten Umgebung nicht immer die beste Leistung und sind weniger flexibel als traditionelle Paketverwaltungsmethoden wie apt. Für eine Serverumgebung, in der Leistung und Flexibilität wichtig sind, ist es daher empfehlenswert, auf Snap-Pakete zu verzichten.
Nachdem die Installation abgeschlossen ist, starten Sie den Server neu, um sicherzustellen, dass alle Änderungen übernommen wurden. Anschließend können Sie sich mit den während der Installation erstellten Anmeldeinformationen anmelden.
Linux Grundlagen
Dateisystem
Das Linux-Dateisystem ist für alle Linux-Distributionen weitestgehend
einheitlich. Die oberste Hierarchie-Ebene ist dabei immer das
Verzeichnis / (Slash). Dieses ist vergleichbar mit der
obersten Hierarchieebene unter Windows, welche in der Regel dem
“C:”-Laufwerk entspricht.
Weitere wichtige Verzeichnisse sind:
- die Benutzerverzeichnisse unter
/home/<username>/, z.B./home/linus/
Hier liegen die Dateien, Dokumente und Konfigurationen der User.
Schreib- und Leserechte haben nur die jeweiligen User und Personen mit
administrativen Rechten. Die Verzeichnisse sind mit dem
Benutzerverzeichnis unter Windows (in der Regel unter
C:\Users\<username>\ zu finden) vergleichbar.
- Die Systemverzeichnisse (z.B.
/etc/,/var/,/mnt/,/lib/,/bin/,/sys/)
Diese Verzeichnisse beinhalten Systemdaten, z.B. Programme, Programmbibliotheken, temporäre Dateien, Log-Dateien oder systemweite Konfigurationen. Deshalb haben in diesen Verzeichnissen i.d.R. nur Personen mit administrativen Rechten Schreibrechte.
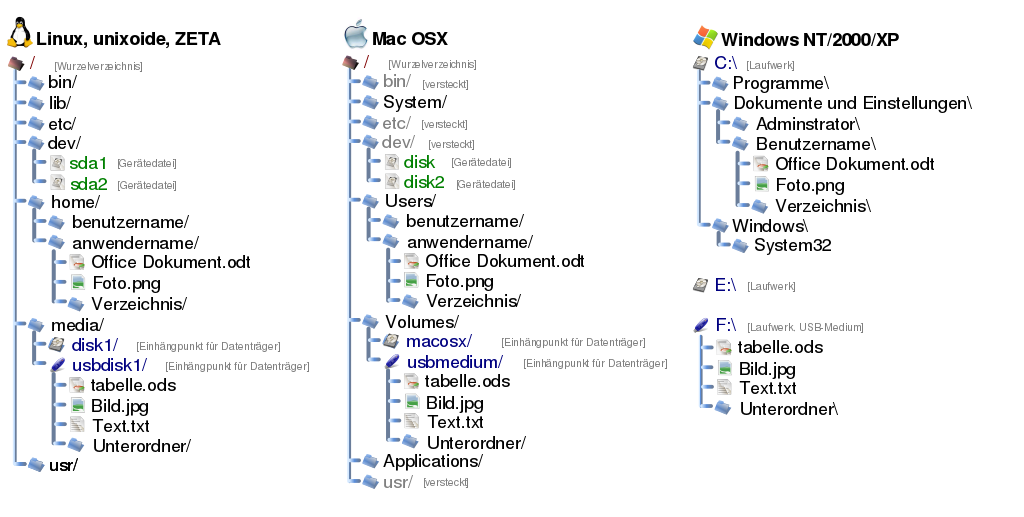
Im Vergleich mit dem Dateisystem von Windows fällt auf, dass es unter
Linux nur einen Verzeichnisbaum für alle Dateien, Festplatten und
Laufwerke gibt. Auch zusätzliche Festplatten oder externe Datenträger
werden in Linux-Systemen zunächst durch eine Gerätedatei im Verzeichnis
/dev/ identifiziert und können dann über sogenannte
Einhängepunkte oder Mountpoints an einer beliebigen Stelle des
Verzeichnisbaumes verfügbar gemacht werden (“eingehängt” oder
“gemountet” werden). Unter Windows haben zusätzliche Datenträger und
Laufwerke stets ihre eigene unabhängige Verzeichnishierarchie, was die
Verwaltung von Festplatten weniger flexibel macht.
- Systemweite Konfigurationen in
/etc/
Das Verzeichnis /etc/ enthält zahlreiche
Konfigurationsdateien für die systemweite Verwaltung von Programmen.
Viele Programme haben hier eigene Unterordner (z.B.
/etc/apache2 für die Konfiguration des Apache-Webservers).
Möchte man die Konfiguration eines Programms systemweit ändern, ist das
/etc/ Verzeichnis i.d.R. ein guter Startpunkt.
Schreibrechte haben hier nur Personen mit administrativen Rechten.
-
Programmverzeichnnisse:
/bin/,/sbin/,/usr/bin//usr/sbin//bin/: Essentielle Systemprogramme (Start, Restore, Basisprogramm des Betriebssystems)/usr/bin/: ergänzende Systemprogramme/sbin/und/usr/sbin/: Systemprogramme für die Systemadministration, die i.d.R. nur von Personen mit administrativen Rechten nutzbar sind
Dynamische Programmdateien:
/var/
Das Betriebssystem und darauf installierte Software erzeugt ständig
neue Dateien, z.B. werden in Log-Dateien Systemereignisse protokolliert.
Solche dynamischen Inhalte werden i.d.R. im
/var/-Verzeichnis gespeichert (v.a. im Unterverzeichnis
/var/log).
- Einhängepunkte
/mnt/und/media/
Externe Laufwerke und Wechselmedien werden standardmäßig in den
Verzeichnisse /mnt/ und /media/ eingebunden.
Dies ist allerdings keine zwingende Vorgabe und häufig gibt es gute
Gründe eine Festplatte an einer anderen Stelle des Verzeichnisbaumes
einzuhängen, z.B. im Home-Verzeichnis eines Users.
- Temporäre Dateien:
/tmp/
Das Verzeichnis /tmp/ dient der Speicherung von
temporären Dateien. Viele Anwendungen und Systemprozesse nutzen es, um
ihre Arbeit auszuführen. Die Dateien in /tmp/ werden in der
Regel automatisch gelöscht, wenn der Rechner neu gestartet wird oder
wenn sie nicht mehr benötigt werden.
- Prozesse und Hardware:
/proc/und/sys/
Das Verzeichnis /proc/ enthält Informationen über
laufende Prozesse und Systemhardware. Viele Systemtools lesen
Informationen aus /proc/, um die Systemleistung zu
überwachen. Das Verzeichnis /sys/ enthält Informationen
über Systemhardware und Gerätetreiber. Systemtools und Anwendungen
nutzen /sys/, um Informationen über die Systemhardware zu
erhalten und die Hardware-Konfiguration zu ändern. Mit dem Befehl
cat /proc/cpuinfo erhält man z.B. Informationen zum
verbauten Prozessor oder mit cat /sys/power/state
Informationen zu den unterstützten Standby- und Power-Modi des
Systems.
- Weitere Quellen
Mehr zur Verzeichnisstruktur von Linux findet sich z.B. bei Ubuntuusers.
Softwareverwaltung
Programme (oder auch Pakete, Packages, Software oder Apps) werden in Linux i.d.R. durch eine zentrale Paketverwaltung ähnlich einem App-Store auf dem Smartphone installiert. Da auch Android auf dem Linux-Kernel aufbaut, sind die Prozesse zur Softwareverwaltung in Ubuntu vergleichbar mit den Prozessen, die im Hintergrund ablaufen, wenn man auf dem Smartphone eine App installiert oder aktualisiert.
- Paketquellen
Zur Installation verfügbare Software wird unter Linux in Paketrepositorien (oder auch Paketkatalog oder Paketquelle) aufgelistet und verfügbar gemacht. Ein Repositorium wird i.d.R. vom Hersteller des Betriebssystems zur Verfügung gestellt und ähnelt in der Funktion dem Google-Play-Store auf einem Android-Smartphone.
Die in den Repositorien des OS-Herstellers beinhaltete Software ist kompatibel mit dem Betriebssystem und, je nach konkretem “Unterkatalog”, auch getestet. Allerdings handelt es sich nicht immer um die neueste Version eines Programms. Denn neue Versionen werden aufgrund der Tests und Abhängigkeiten zu anderer Software erst zeitverzögert in die Kataloge aufgenommen.
Mehr Informationen zur Funktionalität der Paketquellen findet sich bei Ubuntuusers.
Bevor Software Software installiert werden kann, muss das
Betriebssystem die aktuelle Version des Katalogs herunterladen. Dies
erfolgt auf der Kommandozeile mit dem Befehl
sudo apt-get update oder sudo apt update.
Möchte man anschließend ein Programm installieren, muss der Name des
entsprechenden Pakets bekannt sein. Die Installation erfolgt mit
sudo apt-get install <Paketname>.
Der Vorteil der zentralen Paketverwaltung ist, dass in den
Repositorien stets festgehalten ist, welche Version eines Programms die
aktuelle ist. Durch den Abgleich der Versionen aller installierter
Programme mit dem Repositorium kann die Paketverwaltung schnell
ermitteln, für welche Programme es Aktualisierungen gibt. Um diese zu
installieren, muss der Befehl sudo apt-get upgrade
ausgeführt werden.
- Fremdquellen
Ist in den Paketquellen des OS-Herstellers nicht die nötige Software enthalten, können auch Fremdquellen zum System hinzugefügt werden. Hierbei handelt es sich um Paketkataloge, die nicht vom OS-Hersteller (oder der Community) überprüft wurden. Deshalb besteht hier stets die Gefahr, dass die enthaltende Software das System beschädigt oder es sich um Schadsoftware handelt. Es gibt jedoch immer wieder Fälle, bei welchen solche Fremdquellen nötig sind. Wie diese dem System hinzugefügt werden können, ist z.B. hier geschildert.
- Weitere Befehle wichtige Befehle für die Paketverwaltung
sudo apt-get autoremove: entfernt Abhängigkeiten von Programmen, die selbst nicht mehr installiert sind. Dadurch wird das System aufgeräumt.sudo apt list --upgradeable: zeigt installierte Programme an, für welche Aktualisierungen verfügbar sindsudo apt-get remove <Paketname>: entfernt ein Paket, nicht jedoch dessen Konfigurationsdateiensudo apt-get purge <Paketname>: entfernt ein Paket inkl. dessen Konfigurationsdateien
- Stolpersteine bei der Paketverwaltung
Abhängigkeitsprobleme: v.a. bei der manuellen Installation von Paketen oder der Nutzung von Fremdquellen besteht die Möglichkeit, dass ein Programm ein anderes Programm als Abhängigkeit benötigt. Diese Abhängigkeit ist aber nicht in den Paketquellen enthalten. Dadurch kommt es zu einem nicht automatisch auflösbaren Abhängigkeitsproblem. Mögliche Maßnahmen sind die manuelle Installation der Abhängigkeiten (die aber weitere Abhängigkeiten haben können) oder der Downgrade auf eine kompatible Version.
Paketname: häufig sind die Paketnamen für ein Programm nicht eindeutig. Um den genauen Namen für die Installation zu finden, können die Programmkataloge durchsucht werden:
sudo apt-cache search <Suchbegriff>. Alternativ kann natürlich auch im Internet nach dem genauen Namen eines Pakets gesucht werden.
Webserver
Sie möchten auf Ihrem Linux-Server eine Website betreiben. Dazu wollen Sie den Webserver Apache installieren. Wie gehen Sie vor?
Der erste Schritt bei der Softwareverwaltung sollte immer die
Aktualisierung der Paketquellen sein:
sudo apt-get update.
Anschließend wird das System auf den aktuellen Stand gebracht:
sudo apt-get upgrade.
Nun müssen Sie herausfinden, wie das Paket, das den Apache-Webserver
für Ubuntu liefert, heißt. Das können Sie mit einer Internetrecherche
oder dem Befehl sudo apt-cache search apache tun.
Wenn Sie wissen, wie das Paket lautet, können Sie dieses mit dem
Befehl sudo apt-get install <Paketname>
installieren.
Kommandozeile
-
Grundlegende Bedienung:
ENTER-Taste nach Eingabe eines Befehls wird dieser mit der ENTER-Taste ausgeführt
Pfeiltasten hoch/runter: durch bisherige Befehle blättern und diese wieder aufrufen
Tab-Taste: Autovervollständigung von Pfaden und Befehlen. Erste Buchstaben eines Pfades tippen, dann TAB-Taste für die Autovervollständigung oder anzeigen von Optionen.
STRG + C: bricht den laufenden Befehl ab
Kopieren: mit dem Cursor Text auswählen, dann STRG + Umschalt + C
Einfügen: STRG + Umschalt + V
Cursor-Position: mit Pfeiltasten ändern, geht nicht per Mausklick
-
Mit der Kommandozeile im Dateisystem navigieren:
Verzeichnis wechseln:
cd <Pfadangabe>, z.B.cd /home/david/Dokumentein das eigene Home-Verzeichnis wechseln:
cdEine Ordnerebene nach oben gehen:
cd ..Zwei Ordnerebenen nach oben gehen:
cd ../..Aktuelle Position im Dateisystem anzeigen:
pwdVerzeichnisinhalt anzeigen lassen:
lsoder mit mehr Informationenls -l
-
Dateioperationen:
Datei erstellen:
touch <Dateipfad>/<Dateiname>Verzeichnis anlegen:
mkdir <Dateipfad>/<Neuer-Ordner>Inhalt einer Textdatei ausgeben:
cat <Dateiname>Oberste oder letzte 10 Zeilen einer Datei anzeigen lassen:
head <Dateiname>odertail <Dateiname>-
Datei kopieren/verschieben/löschen:
Copy:
cp <Quelldatei> <Zieldatei>Move:
mv <Quelldatei> <Zeildatei>remove:
rm <Dateiname>oder remove recursive:rm -r <Verzeichnispfad>
Textdateien bearbeiten: Nano-Editor:
Es gibt viele Texteditoren für Linux. Weit verbreitet sind z.B. nano und vim, wobei nano der einsteigerfreundlichere Editor ist. Deshalb arbeiten wir im Kurs mit dem nano-Editor. Wer dennoch mit dem Vim-Editor arbeiten möchte, kann sich z.B. dieses Tutorial anschauen
Datei im Nano-Editor öffnen:
nano <Dateipfad>/<Dateiname>Die Navigation erfolgt ohne Maus, nur mit den Pfeiltasten!
Datei schließen und speichern: STRG + X, dann J, dann ENTER
Schließen ohne zu speichern: STRG + X, dann N
Komplette Zeile löschen: STRG + K
Kopieren und einfügen erfolgt wie auf dem Terminal
Text suchen: STRG + W, dann Suchbegriff eingeben oder für weitere Treffer direkt mit ENTER bestätigen
Zu bestimmter Zeile springen: STRG + /, dann Zeilennummer eingeben
- Die Wahl der richtigen Hard- und Software erfolgt ganz am Anfang und muss auf den Einsatzzweck abgestimmt sein und untereinander komptibel sein.
- In diesem Kurs wird auf einem virtuellen Server mit Linux-Betriebssystem die Cloud-Software Nextcloud als Docker-Container installiert.
- Das Dateisystem unter Linux hat nur einen Verzeichnisbaum, unter welchem alle Festplatten eingebunden sind
- Software wird unter Linux in einer zentralen Paketverwaltung organisiert
- Linux-Server-Systeme werden mit der Kommandozeile verwaltet
Content from Remote Access: das SSH-Protokoll
Zuletzt aktualisiert am 2026-05-12 | Diese Seite bearbeiten
Übersicht
Fragen
Wie kann ein Computer (ggf. aus der Ferne) verwaltet werden, auch wenn er keinen Bildschirm hat?
Wie kann eine SSH-Verbindung sicher über unsichere Netzwerke hergestellt werden?
Ziele
Grundlagen des SSH-Protokolls verstehen
SSH-Server sicher konfigurieren
Sichere SSH-Verbindungen mit Schlüssel-Authentifikation aufbauen
den Raspberry Pi im Headless-Setup aus der Ferne steuern
Das SSH-Protokoll
Server stehen häufig an unzugänglichen Orten (Keller, gekühlte Serverräume, weit entfernte Rechenzentren o.Ä.). Dennoch müssen sie verwaltet werden. Dies wird heutzutage mittels des SSH-Protokolls gemacht (früher wurde das inzwischen veraltete Telnet-Protokoll genutzt).
Das SSH-Protokoll baut eine sichere Verbindung zwischen einem Clientgerät (z.B. Ihrem Notebook) und einem Server (z.B. Ihrem Raspberry Pi) über ein (ggf. auch unsicheres) Netzwerk auf. Über diese Verbindung besteht in der Regel Zugriff auf die Kommandozeile des entfernten Geräts, womit dieses verwaltet werden kann.
Die Verbindung kann aber auch zum Übertragen anderer Daten genutzt
werden. So können Dateien übertragen werden (mit dem scp-Befehl),
entfernte Dateisysteme lokal genutzt werden (per SSHFS, siehe Wikipedia) oder die
graphische Ausgabe eines entfernten Programms lokal dargestellt werden
(siehe
diesen Heise-Artikel).
Protokoll
Bei einem Protokoll handelt es sich um eine Sammlung genau festgelegter technischer Parameter für den Kommunikationsaustausch zwischen Computern. Ähnlich der Sprache und ihrer Grammatik, auf die sich zwei Menschen zum Kommunizieren einigen. Ein Protokoll hat einen genauen Einsatzzweck und eine klar definierte Funktionsweise. z.B. ist das HTTPS-Protokoll dafür gemacht, Daten zwischen einem Browser und einem Webserver verschlüsselt mittels der TLS-Verschlüsselung zu übertragen. Mehr zum Thema findet sich bei StudySmarter
Das SSH-Protkoll nutzt mehrere etablierte Verfahren der Kryptographie und Netzwerkkommunikation zur Gewährleistung der sicheren Übertragung. Ähnlich einer HTTPS-Verbindung werden beim Verbindungsaufbau zunächst die Kommunikationsstandards zwischen Client und Server ausgehandelt, dann werden Session-Keys zur Verschlüsselung ausgetauscht, welche jedoch nur für die aktuelle Verbindung Gültigkeit haben. Mit diesen Session-Keys wird die eigentliche Verbindung in Form einer symmetrischen Verschlüsselung aufgebaut (welche deutlich schneller ist, als die zuvor stattfindende asymmetrische Verschlüsselung, siehe dazu auch die Ressourcen von Studyflix zur symmetrischen und asymmetrischen Verschlüsselung).
Mehr zur Funktionsweise des SSH-Protkolls können Sie im Netz finden, z.B. bei IP-Insider.
Voraussetzung für die SSH-Verbindung
Sie haben wie in Sitzung 2 besprochen auf Ihrem Server Ubuntu installiert. Nun wollen Sie eine SSH-Verbindung von Ihrem Notebook mit Ihrem Server herstellen. Was sind die Bedingungen für eine erfolgreiche SSH-Verbindung?
Netzwerkverbindung: der Server muss im Netzwerk erreichbar sein. Dazu müssen entweder Server und Client im selben Netzwerk (z.B. demselben Heimnetzwerk) sein oder der Server muss im Internet erreichbar sein.
Software: Auf dem Server muss die SSH-Server-Software installiert sein (das Paket openssh-server) und auf dem Client ein SSH-Client-Programm (das OpenSSH-Client-Programm für die Kommandozeile ist i.d.R. auf allen PCs installiert. Für Windows kann auch das graphische Programm Putty installiert werden).
Berechtigungen: die Anmeldung am entfernten Server ist nur möglich, wenn Sie die Berechtigungen dazu haben. Sie benötigen also einen Account unter Ubuntu und dessen Passwort.
Firewall: eine Firewall am Server oder auf dem Weg dorthin muss die SSH-Verbindung zulassen
Identifizierung: der Server muss für eine ordentliche Verbindung eindeutig identifizierbar sein. Dies geschieht durch sogenannte Host-Keys, die bei der erstmaligen Verbindung vom Server zum Client übertragen werden und manuell akzeptiert werden müssen. Ändert sich der Host-Key (z.B. nach einer Neuinstallation oder weil ein bösartiger Akteur sich als Ihr Server ausgibt) und passt nicht mehr zum ursprünglich übertragenen Key, schlägt die Verbindung fehl. Erst wenn der neue Key akzeptiert wird ist eine Verbindung wieder möglich (gespeicherte Keys finden Sie in der Datei know_hosts.conf im Verzeichnis .ssh in Ihrem persönlichen Ordner).
Grundlegender Verbindungsaufbau
Wenn die Voraussetzungen stimmen (siehe Vorraussetzungen für
die SSH-Verbindung), kann eine einfache SSH-Verbindung mit folgendem
Befehl aufgebaut werden: ssh <user>@<server>
Dabei ist <user> der Username am entfernten Gerät und
<server> ist die Adresse des Servers. Die Adresse
kann entweder in Form einer IP-Adresse (z.B. 192.168.178.10), als URL
(z.B. mein-cloudserver.domain.de) oder als Hostname (z.B.
mein-cloudserver) angegeben werden. Die Variante mit dem Hostnamen
funktioniert jedoch nur, wenn dieser im lokalen Netzwerk bekannt ist
(z.B. in einem Heimnetzwerk im Router angezeigt wird).
Beim erstmaligen Verbindungsaufbau mit einem Server,
muss dessen Host-Key akzeptiert werden. Mit dem Host-Key authentisiert
(d.h. weist sich aus) sich der Server gegenüber dem Client. Durch die
Überprüfung des Host-Keys kann festgestellt werden, ob der Server, mit
dem eine Verbindung aufgebaut werden soll, auch der korrekte Server ist
und nicht etwa die eigene SSH-Anfrage von schädlichen Akteuren umgelenkt
wurde. Diese Überprüfung erfolgt durch den Abgleich des Fingerabdrucks
des Host-Keys. Dazu muss Serverseitig der Befehl
ssh-genkey -lf /etc/ssh/<key.pub> (dabei den Namen
des zu überprüfenden Schlüssels angeben).
Wird ein Host-Key akzeptiert, speichert der openSSH-Client diesen Key in der Datei “known_hosts.conf” im Verzeichnis .ssh ab. Ändert sich der Key des Servers, muss der neue Key akzeptiert werden (vgl. auch Vorraussetzungen für die SSH-Verbindung).
SSH-Verbindung
-
So bauen Sie eine einfache SSH-Verbindung auf:
ssh <user>@<server>- dabei ggf. die besonderen Bedingungen im Kurssetup beachten
Schlüsselauthentifikation
Die einfache SSH-Verbindung genügt zwar schon, um das entfernte System zu verwalten. Allerdings kann eine angreifende Person versuchen, den Usernamen und das Passwort zu erraten und damit Zugriff auf den Server erlangen (leider sind Passwörter häufig nicht allzu kreativ erdacht). Um dies zu verhindern, kann die Verbindung zusätzlich gesichert werden:
am Client, indem statt Passwörtern kaum zu erratende Schlüsselpaare zur Anmeldung genutzt werden
am Server, indem die Einstellungen des SSH-Servers optimiert werden, z.B. um bei häufigen Fehlanmeldungen Verursacher derselben zu blockieren
Die Anmeldung per Schlüssel erfolgt mit einem Schlüsselpaar. Ein solches Schlüsselpaar besteht aus einem privaten und einem öffentlichen Schlüssel. Während der öffentliche Schlüsse herausgegeben werden kann, muss der private Schlüssel privat bleiben und darf das eigene Gerät niemals verlassen. Vereinfacht kann man sich das Konzept wie ein Vorhängeschloss und den dazugehörigen Schlüssel vorstellen. Das Schloss ist in dieser Analogie der öffentliche Schlüssel und wird in geöffnetem Zustand an den Server übergeben. Dieser “verschließt” damit die Tür zum SSH-Server. Zwar können alle sehen, dass Ihr (öffentliches) Schloss an der Tür hängt, aber nur Sie können mit Ihrem privaten Schlüssel die Tür wieder öffnen.
Aufgrund der komplexen kryptographischen Struktur der Schlüssel sind diese deutlich schwerer bis gar nicht zu erraten. Zusätzlich empfiehlt es sich, den privaten Schlüssel mit einer Passphrase vor unbefugtem Zugriff zu schützen. Dann muss jedes mal, wenn der private Schlüssel genutzt wird, ein zusätzliches Passwort eingegeben werden.
Schlüsselauthentifikation
Für eine sichere SSH-Verbindung empfiehlt es sich, auf Passwörter zu verzichten und sich stattdessen mit einem Schlüsselpaar zu authentifizieren.
Ist ein Schlüsselpaar erzeugt, erfolgt die Verbindung wie folgt:
ssh <user>@<server> -i <Pfad-zum-privaten-schlüssel>.
Mit dem Befehlsparameter -i wird der Pfad zum privaten
Schlüssel am Client angegeben (Achtung: für die Kursumgebung die besonderen Bedingungen im Kurssetup
beachten).
Mehr zur Schlüsselauthenfikation finden Sie z.B. bei ManageEngine (hier v.a. die ersten drei Absätze).
Schlüsselpaar erstellen
Die Erstellung eines Schlüsselpaars erfolgt am Client. Dazu wird auf
der Kommandozeile (“Eingabeaufforderung” unter Windows) folgender Befehl
abgesetzt:
ssh-keygen -t <Schlüsseltyp> -b <Schlüssellänge>
Es müssen Angaben zum Speicherort und der Passphrase gemacht werden.
Wird kein Speicherort angegeben, wird das Schlüsselpaar im Ordner
.ssh des Benutzerverzeichnisses gespeichert.
Es stehen unterschiedliche Schlüsseltypen- und -längen zur Verfügung:
RSA: weit verbreitet, kann mit sehr viel Rechenaufwand evtl. geknackt werden (siehe letzter Absatz dieses Artikels). Als Schlüssellänge sollte 4096 bit gewählt werden.
ecdsa: ist ein neueres Verfahren, das aber kurze Schlüssel nutzt und damit auf Sicherheit verzichtet
ed25519: ist ein neues Verfahren, das auf sog. elliptische Kurven setzt und aktuell als am sichersten gilt. Dieses Verfahren wird empfohlen.
Zur Wahl des Schlüsseltyps gibt es bei goteleport.com eine informative Vergleichstabelle.
WICHITG
Das Schlüsselpaar muss am Client erstellt werden. Sonst ist der private Schlüssel bereits mit der Erstellung auf einem fremden Gerät und damit kompromittiert.
Konfiguration des SSH-Servers
Um die Sicherheit des SSH-Servers weiter zu erhöhen, sollten einige
Einstellungen am Server vorgenommen werden. Dies kann nach erfolgreicher
SSH-Verbindung getan werden. Die Konfigurationsdatei für den SSH-Server
findet sich unter /etc/ssh/sshd_config und kann mit dem
nano-Editor bearbeitet werden.
Folgende Änderungen sollen an der Konfigurationsdatei vorgenommen werden:
Nur spezifischen Usern eine SSH-Verbindung erlauben (neue Zeile am Ende ergänzen):
AllowUsers <username>Anmeldung mit Passwort verbieten und nur per Schlüssel erlauben (vorhandene Zeilen ändern):
PasswordAuthentication no
PubkeyAuthentication yes
KbdInteractiveAuthentication no
UsePAM noStandardport ändern:
#Port 22ändern zuPort <eine Nummer größer 1024>, siehe dazu auch die Liste der Well-Know-PortsRoot-User-Anmeldungen verbieten:
PermitRootLogin noZeit für erfolgreiche Anmeldeversuche auf 30 Sekunden limitieren:
LoginGraceTime 30Leere Passwörter verbieten:
PermitEmptyPasswords noAbmeldung bei Inaktivität:
ClientAliveInterval 300undClientAliveCountMax 0
Nach Änderungen an der Konfiguration eines Programms muss dieses in
der Regel neu gestartet werden, um die neue
Konfiguration zu übernehmen. Dies geschieht für den SSH-Server mit den
Befehlen sudo systemctl daemon-reload und
sudo systemctl restart ssh.service (siehe dazu auch das Callout zu systemd)
Weitere Anpassungen des SSH-Servers sind je nach eigenem Sicherheitsbedürfnis möglich. Z.B. finden sich bei cyberciti.biz einige weitere Möglichkeiten.
Möchte man sich nun per SSH anmelden, müssen die vorgenommenen
Änderungen berücksichtigt werden. V.a. muss die geänderte Portnummer
angegeben werden:
ssh -p <Portnummer> -i <Pfad-zum-privaten-Schlüssel> <user>@<server>
(Achtung: für die Kursumgebung die besonderen Bedingungen im Kurssetup
beachten).
Programme mit systemd Steuern
Programme können unter Debian-basierten Systemen mit dem
Systemd-Dienst gesteuert werden. Voraussetzung dafür ist, dass eine sog.
Unit-Datei vorhanden ist (i.d.R. unter /etc/systemd/system
zu finden). Damit können die Programmge gestartet, gestoppt,
neugestartet und deren Status geprüft werden. Der Systemd-Dienst wird
mit dem Befehl systemctl (kurz für systemcontrol)
bedient:
Programm starten:
sudo systemctl start <Servicename>Programm stoppen:
sudo systemctl stop <Servicename>Programm neustarten
sudo systemctl restart <Servicename>Status überprüfen:
sudo systemctl status <Servicename>Ein Programm zum Autostart hinzufügen:
sudo systemctl daemon-reload && sudo systemctl enable <Servicename>
Fehlerhafte SSH-Anmeldung
Sie wollen sich per SSH mit Ihrem Server verbinden. Sie nutzen dafür
den folgenden Befehl:
ssh linus@eberhard-karl.uni-tuebingen.de -p 2746 -i .ssh\eberhard.key
Die Verbindung schlägt aber mit der Meldung Permission denied (publickey) fehl. Worauf weißt diese Fehlermeldung hin?
Der SSH-Server erfordert ein Schlüsselpaar für die Anmeldung. Zwar wurde der private Schlüssel eberhard.key angegeben. Allerdings wurde er nicht akzeptiert. Dies kann daran liegen, dass auf dem Server der dazugehörige öffentliche Schlüssel nicht hinterlegt ist oder nicht im Account des angegebenen Users (linus) in der Datei authorized_keys gespeichert ist.
Weitere Gründe können sein:
Falsche URL/IP-Adresse: die Anmeldung wird deshalb an einem fremden/falschen Server versucht.
Der User linus existiert nicht auf dem Server
Tip: mit Angabe des Parameters -v erhält man beim Verbingungsversuch mehr Informationen im Falle eine fehlschlags.
das SSH-Protokoll erlaubt den Zugriff auf die Kommandozeile entfernter Computer
zur Erhöhung der Sicherheit empfiehlt sich die Nutzung eines Schlüsselpaares anstatt eines Passworts
zur Reduzierung der Angriffsfläche sollte die Konfiguration des SSH-Servers angepasst werden
ein privater (SSH-)Schlüssel darf niemals das eigene Gerät verlassen
der Aufbau der SSH-Verbindung geschieht wie folgt:
ssh -p <Portnummer> -i <Pfad-zum-privaten-Schlüssel> <user>@<server>
Content from Sicherheit 1: Benutzer und Dateirechte
Zuletzt aktualisiert am 2026-05-12 | Diese Seite bearbeiten
Übersicht
Fragen
Wer darf was auf meinem System?
Welche Benutzer gibt es unter Linux?
Was sind Dateirechte?
Ziele
Grundlagen der Benutzerverwaltung unter Linux
Dateirechte verstehen und anpassen
Befehle
chmod,chown,adduser,deluserundusermodkennen lernen
Benutzerverwaltung
Benutzerkategorien
Jeder User-Account in Linux besteht aus einem Loginnamen, einer User-ID, ggf. einem beschreibendem Namen und weiteren Metainformationen (z.B. Adresse, Telefonnummer etc). Auf einem üblichen Linux-System gibt es drei Typen von Benutzerkonten:
root: der Root-Account ist der Systemadministrator und hat damit die meisten Rechte im System. Er ist vergleichbar mit dem “Administrator”-Konto in Windows. Die User-ID des root-Accounts ist immer die 0.
Standardaccount: bei der Installation des Betriebssystems (Ubuntu) wurde bereits ein erster Standardaccount erstellt. Standardaccounts sind i.d.R. mit echten Personen in Verbindung zu bringen, haben ein Benutzerverzeichnis unter
/home/und können sich mit einem Passwort am System anmelden. Der erste Standardbenutzer erhält die User-ID 1000. Für alle weiteren wird die ID jeweils um 1 erhöht. Ein Standardaccount kann administrative Rechte erhalten. Wurden ihm diese erteilt, können mit demsudo-Befehl die eigenen Rechte eskaliert werden, d.h. Befehle mit administrativen Rechten ausgeführt werden.Systemaccount: Auf einem frisch installierten Linuxsystem gibt es bereits zahlreiche Systemaccounts. Sie haben i.d.R. User-IDs
<1000. Systemuser sind nicht mit echten Personen zu verbinden und können sich nicht interaktiv am System anmelden. Ein Systemaccount ist im Normalfall für eine explizite Aufgabe vorhanden. Z.B. ist der Account www-data für die Steuerung eines Webservers gedacht.
Sämtliche Benutzeraccounts des Systems können der Datei
/etc/passwd entnommen werden (z.B. öffnen mit
less /etc/passwd).
Möchte man einen neuen Account erstellen, nutzt man den Befehl
adduser. Um z.B. den Account “Linus” hinzuzufügen lautet
der Befehl wie folgt: sudo adduser linus Anschließend kann
das Passwort sowie weitere Metainformationen des Accounts gesetzt
werden. Es wird automatisch ein Homeverzeichnis für den User erstellt.
Möchte man dies nicht, kann der Parameter --no-create-home
dem Befehl angehängt werden.
Gruppen
Neben einzelnen Accounts gibt es auch Gruppen, um mehrere Accounts zusammen zu fassen. Standardmäßig ist jeder Account (System- und Standardaccounts) auch Mitglied in seiner eigenen Gruppe. So ist z.B. der Systemaccount www-data auch Mitglied in der Gruppe www-data. Ein Account hat dabei immer die Rechte, die ihm selbst erteilt wurden plus die Rechte, die den Gruppen erteilt wurden, in welchen er Mitglied ist. Wird ein Recht an einer Stelle verweigert, so hat dies Vorrang vor einer Erlaubnis an anderer Stelle.
Um zu sehen in welchen Gruppen man Mitglied ist, kann der Befehl
id genutzt werden. Der bei der Installation des
Betriebssystems erstellte Standardbenutzer ist bereits in mehreren
Gruppen Mitglied (z.B. der sudo-Gruppe um sudo-Befehle ausführen zu
können). Um alle Gruppen und deren Mitglieder zu sehen kann die Datei
/etc/groups geöffnet werden.
Möchte man einen Account einer Account-Gruppe hinzufügen, nutzt man
den usermod-Befehl (kurz für user modification):
sudo usermod -aG <Gruppenname> <Username>
Möchte man einem Account administrative Rechte erteilen, muss dieser der
sudo-Gruppe hinzugefügt werden:
sudo usermod -aG sudo <Username>
sudo
Mit dem sudo-Befehl können die eigenen Benutzerrechte
eskaliert werden. Das heißt, Befehle mit erhöhten, also administrativen,
Rechten ausgeführt werden. Dazu muss lediglich das
sudo-Kommando vor den Befehl gestellt werden. Um z.B. einen
neuen Account zu erstellen, muss vor den entsprechenden Befehl das
sudo gestellt werden:
sudo adduser <username>
Der sudo-Befehl
Um Befehle mit erhöhten Rechten auszuführen muss das
sudo-Kommando vor den Befehl gestellt werden, z.B.
sudo adduser <username>
Der sudo-Befehl wird auch genutzt, um zwischen Accounts
zu wechseln oder Befehle mit den Rechten eines anderen Accounts
auszuführen. Um z.B. in den Root-Account zu wechseln genügt das
Kommando sudo -i. Anschließend befindet man sich auf der
Kommandozeile des Root-Accounts und alle Befehle werden mit Root-Rechten
ausgeführt. Dementsprechend sollte man hier Vorsicht walten lassen. Um
wieder zur vorhergehenden Kommandozeile des Standardaccounts zu kommen
wird die Root-Befehlszeile mit dem Befehl exit
verlassen.
Möchte man einen Befehl mit den Rechten eines anderen Accounts
ausführen geschieht dies wie folgt:
sudo -u <username> <Befehl> Um z.B. mit den
Rechten des Accounts www-data die Datei startpage.html
zu öffnen lautet der Befehl
sudo -u www-data nano startpage.html
Passwortabfrage bei sudo-Befehl
Um zu verhindern, dass der sudo-Befehl ohne die Kenntnis des
Passworts ausgeführt wird (z.B. wenn ein Angreifer einen Weg ins System
gefunden hat und nun Zugriff auf den Account hat), sollte das System so
konfiguriert werden, dass für den sudo-Befehl immer ein
Passwort verlangt wird.
Standardmäßig ist Ubuntu so konfiguriert, dass Mitglieder der sudo-Gruppe zwar administrative Rechte haben, aber diese immer mit ihrem Passwort bestätigen müssen.
Dieses Verhalten kann aber den eigenen Wünschen angepasst werden,
indem im Verzeichnis /etc/sudoers.d/ mit dem
visudo-Programm eine neue Datei erstellt wird, z.B.:
sudo visudo /etc/sudoers.d/010_<username>-passwd. Um
die Passwortabfrage für einen bestimmten Account zu forcieren, kann
folgende Syntax genutzt werden:
<username> ALL=(ALL) PASSWD: ALLDabei muss <username> durch den eigenen Usernamen
ersetzt werden. Siehe zur sudoers-Datei auch die Diskussion
auf askubuntu und den Artikel bei ubuntuusers.
Benutzerverwaltung
Sie sind mit Ihrem Standardaccount am System angemeldet, dieser hat bereits administrative Rechte. Nun wollen Sie Ihrem System den neuen Account Linus hinzufügen. Dieser Account soll ebenfalls administrative Rechte erhalten. Wie lauten die korrekten Befehle?
adduser linusundusermod -aG linus sudosudo adduser linusundsudo usermod -aG sudo linussudo visudo linusundsudo usermod -aG www-data linus
- Antwort 2 ist die richtige Lösung.
Bei Antwort 1 fehlt das sudo-Kommando vor den
eigentlichen Befehlen und beim usermod-Befehl sind user und Gruppe
vertauscht.
Bei Antwort 3 macht der erste Teil gar keinen Sinn und der zweite ist zwar technisch korrekt, führt aber nicht zum gewollten Ziel.
Dateirechte
Jede Datei des Systems ist einem Besitzer und einer Gruppe zugeordnet. Darüber kann gesteuert werden, wer auf welche Dateien mit welchen Rechten zugreifen darf. Die genauen Rechte werden über den sogenannten mode gesteuert. Der mode gibt für jede Datei an, welche Rechte der Besitzer, die besitzende Gruppe und “andere Accounts” haben. Andere Accounts sind dabei alle anderen Accounts des Systems, auch Gastaccounts oder Systemaccounts.
Mit dem Befehl ls -l <Dateipfad> können die
Inhalte eines Verzeichnisses und deren Berechtigungen angezeigt werden.
Ohne Pfadangabe wird das aktuelle Verzeichnis gewählt. Die Ausgabe des
Befehls ls -l /home/linus könnte z.B. wie folgt
aussehen:
BASH
total 4
drwxrwxr-x 2 linus linus 4096 Aug 21 15:35 Ordner1
-rw-rw-r-- 1 linus linus 15 Aug 21 15:34 testdatei.txtDies ist wie folgt zu verstehen:
drwxrwxr-x = es handelt sich um ein Verzeichnis (d für directory, l für Link, - für Datei)
drwxrwxr-x = der Besitzer hat Lese- Schreib -und Ausführberechtigungen
drwxrwxr-x = die besitzende Gruppe hat Lese- Schreib -und Ausführberechtigungen
drwxrwxr-x = alle anderen haben nur Lese- und Ausführberechtigungen
linus linus = die Datei/das Verzeichnis gehört dem User linus
linus linus = die Datei/das Verzeichnis gehört der Gruppe linus
4096 = Dateigröße in Bytes
Aug 21 15:35 = Änderungszeit
Ordner1 = Verzeichnis-/Dateiname
Der ls-Befehl ist bei Ubuntuusers auch ausführlich erklärt.
Möchte man den Eigentümer einer Datei oder eines Verzeichnisses
ändern, wird der Befehl chown genutzt (kurz für change
ownership):
chown <neuer besitzer>:<neue Grupppe> <Datei/Verzeichnisname>.
Um z.B. die Datei test.txt dem User und der Gruppe
linus zu übertragen lautet der Befehl wie folgt:
sudo chown linus:linus test.txt. Soll ein gesamtes
Verzeichnis übertragen werden, wird der Parameter -R
(rekursiv) genutzt: sudo chown -R linus:linus Ordner1
Möchte man den mode ändern (also die Rechte für Besitzer und
Gruppe), nutzt man den Befehl chmod (kurz für change mode):
sudo chmod <Modus> <Datei/Verzeichnis> Der
Modus setzt sich dabei stets aus drei Angaben zusammen:
-
Angabe für wen etwas geändert wird (Gruppe oder Account)
u= userg= groupoother (=alle anderen)
-
Angabe, ob ein Recht erteilt oder entzogen werden soll
+= Recht erteilen-= Recht entziehen
-
Angabe zum betroffenen Recht.
r= read (Leseberechtigung)w= write (Schreibbrechtigung)e= execute (Ausführen von Dateien oder Verzeichnisinhalt von Ordnern anzeigen lassen)
Eine ausführliche Erklärung zu Dateirechten findet sich wieder bei Ubuntuusers
Beispiel
Die Datei test.txt gehört dem User linus und der
Gruppe www-data. Um nun dem User Lese- Schreib- und
Ausführberechtigung zu erteilen, der Gruppe aber nur Leserechte, lauten
die Befehle wie folgt: sudo chmod u+rwx testdatei.txt für
die Userberechtigung und sudo chmod g+r testdatei.txt für
die Gruppenberechtigung. Möchte man der Gruppe www-data wieder das
Leserecht entziehen, lautet der Befehl wie folgt:
sudo chmod g-r testdatei.txt
Dateiberechtigungen
Sie wollen mit Ihrem Standardaccount (dieser ist Mitglied der
sudo-Gruppe) im Verzeichnis /opt/ den neuen Ordner
webservice erstellen. Der Ordner soll dem User
linus und der Gruppe www-data gehören. Der User soll
volle Rechte haben, die Gruppe soll lesen und ausführen dürfen, alle
anderen sollen keine Rechte erhalten. Wie lauten die korrekten
Befehle?
mkdir /opt/webservicechown linus:www-data /opt/webservicechmod 750
sudo mkdir /opt/webservicesudo chown linus:www-data /opt/webservicesudo chmod u+rwxsudo chmod g+rsudo chmod o-rwx
sudo touch /opt/webservicesudo chmod linus:www-data /opt/webservicesudo chown u+rwxsudo chown g+rsudo chown o-rwx
sudo mkdir /opt/webservicesudo chown linus:www-data /opt/webservicechmod linus:+rwxchmod www-data:+rchmod others:-rwx
- Antwort 2 ist korrekt. Die drei
chmod-Befehle könnten noch durchsudo chmod 750zusammengefasst werden, siehe dazu den Ubuntuusers-Artikel zu Dateirechten
Antwort 1 schlägt fehl, da keine administrativen Rechte genutzt werden
Antwort 3 erstellt eine Datei anstatt eines Verzeichnisses. Außerdem
sind die Befehle chmod und chown
vertauscht.
In Antwort 4 ist der chmod-Befehl fehlerhaft
der root-Account ist der Administrator des Systems
Mitglieder der sudo-Gruppe haben administrative Rechte, welche sie mit dem
sudo-Kommando nutzen könnenDateien und Ordner sind immer einem Benutzer und einer Gruppe zugeordnet. Die Besitzverhältnisse können mit
chowngeändert werden.Dateien und Ordner haben einen mode, welcher die Rechte von Besitzer und besitzender Gruppe steuert, er kann mit
chmodgeändert werden
Content from Sicherheit 2: Firewall und Fail2Ban
Zuletzt aktualisiert am 2026-05-12 | Diese Seite bearbeiten
Übersicht
Fragen
Wie kommunizieren Computer im Netzwerk?
Wie schütze ich meinen Server im Netzwerk?
Ziele
Grundlagen der Netzwerkkommunikation verstehen
Eine einfache Firewall einrichten
Fehlerhafte Logins mit Fail2Ban überwachen
Netzwerkkommunikation
OSI-Referenz-Modell
Um allgemeine Leitlinien für Hersteller von Hard- und Software zu etablieren, wurde das OSI-Referenz-Modell entwickelt, welches die Kommunikationsabläufe in Computernetzwerken definiert. Gemäß dem Modell läuft ein Datenpaket beim Sender durch sieben Kommunikationsschichten und beim Empfänger wieder durch die selben Schichten, allerdings in umgekehrter Reihenfolge. Jede dieser Schichten hat klar definierte Aufgaben und spezifische Protokolle. Ein Datenpaket wird dabei in einer Schicht verarbeitet, z.B. in der obersten Schicht (Anwendungsschicht) per HTTP abgerufen und dann an die nächste Schicht übergeben. Dort werden weitere Schritte unternommen. Z.B. könnte das jetzt fertig geschnürte HTTP-Paket zu einem HTTPS-Paket verschlüsselt werden. Am untersten Ende (auf der Bitübertragungsschicht) wird schließlich nur noch festgelegt, wie der Strom über die Leitung fließt.
Da auf jeder Schicht beim Sender weitere Informationen zum Datenpaket hinzugefügt werden (z.B. eine Veschlüsselung oder die IP-Adresse des Empfängers) wird das Datenpaket immer größer (sog. Overhead). Beim Empfänger wird das Paket wieder Schritt für Schritt “ausgepackt”.
Eine ausführliche Erklärung zum OSI-Modell inkl. Video findet sich bei Studyflix.
IP-basierte Netzwerke
Um Kommunikationspartner im Netzwerk zu identifizieren, besitzt jedes
Netzwerkfähige Gerät (genauer gesagt: jedes Netzwerinterface) eine
Hardwareadresse: die MAC-Adresse. Die MAC-Adresse ist
auf Schicht 2 des OSI-Modells definiert. Um nun zu definieren, wo sich
diese MAC-Adresse im Netzwerk befindet, werden in Schicht 3 des
OSI-Modells IP-Adressen eingeführt. Mit IP-Adressen
werden zunächst logische Netzwerksegmente definiert. Dabei wird jedes
Netzwerk mit einer IP-Adresse beschrieben. Diese Netzwerkadresse ist der
Startpunkt des Netzwerkes (z.B. 192.168.178.0). Mit der
Subnetzmaske wird die Anzahl an möglichen Adressen
innerhalb dieses Netzwerks festlegt (z.B. 255.255.255.0
oder in Kurzform /24 für ein Netzwerk mit max. 254
Geräten). Das Ende des Netzwerksegments wird durch die
Broadcast-Adresse definiert (z.B.
192.168.178.255). Datenpakete, die an die Broadcast-Adresse
gesendet werden, werden an alle Adressen des Segments weitergeleitet.
Innerhalb des Segments werden einzelne Geräte durch eine IP-Adresse
definiert (z.B. 192.168.178.25). Wandert das Gerät in ein anderes
Netzwerksegment erhält es eine andere IP-Adresse.
Um eine Kommunikation zwischen verschiedenen Netzwerken (z.B. einem Heimnetzwerk mit der Adresse 192.168.178.0 und der Subnetzmaske 255.255.255.0 und dem Internet) zu ermöglichen, wird ein Standardgateway benötigt. Dies ist i.d.R. die IP-Adresse des Routers. An diesen werden alle Pakete geschickt, die keine Adresse im lokalen Netzwerk haben, und werden dann z.B. ins Internet weiter geleitet.
Es werden unterschiedliche Typen von Netzwerken unterschieden: Private Netzwerke und öffentliche Netzwerke. Private Netzwerke sind nicht öffentlich erreichbar und sind durch Router und Firewalls von öffentlichen Netzwerken getrennt. Dadurch können private Netzwerke mit derselben IP-Adresskonfiguration mehrfach existieren, da sie sich gegenseitig nicht “sehen”.
Folgende Adressbereiche für private Netzwerke gibt es:
| Netzadressbereich | Subnetzmaske | Max. Anzahl Geräte | Bedeutung |
|---|---|---|---|
| 10.0.0.0 bis 10.255.255.0 | 255.0.0.0 | 16777216 | Privates Netzwerk |
| 172.16.0.0 bis 172.31.255.255 | 255.240.0.0 | 1048576 | Privates Netzwerk |
| 192.168.0.0 bis 192.168.255.255 | 255.255.0.0 | 256 | Privates Netzwerk |
| 169.254.0.0 bis 169.254.255.255 | 255.255.0.0 | 65536 | Link Local/APIPA = Standardbereich, wenn automatische Adresszuweisung fehlschlägt |
| 127.0.0.1 bis 127.255.255.254 | 255.0.0.0 | 16777216 | Loopback-Adresse für Kommunikation innerhalb eines Geräts |
IP-Adressen
Werden zentrale Dienste betrieben oder genutzt, muss man sich auch mit dem zugrunde liegenden Netzwerk befassen. Informieren Sie sich deshalb über Ihr Netzwerk:
Welche IP-Adresse hat Ihr Computer?
Wie lautet die Subnetzmaske?
Welche IP-Adressen können Geräte in Ihrem Netzwerk erhalten?
Welche IP-Adressen hat Ihr Router?
Typische Adressen könnten wie folgt lauten:
IP-Adresse: 192.168.178.25
Subnetzmaske: 255.255.255.0
Daraus folgt der Adressbereich 192.168.178.1 bis 192.168.178.254 (die erste Adresse ist als Netzwerkadresse und die letzte als sogenannte Broadcastadresse reserviert und nicht für Geräte verfügbar).
Router geben sich meistens selbst die erste Adresse im Netzwerk, in diesem Beispiel also 192.168.178.1. Zusätzlich erhält der Router auch eine IP-Adresse im Netzwerk des Internetanbieters. Erst dadurch, dass der Router in beiden Netzwerken eine Adresse hat, kann er auch Datenpakete zwischen den Netzwerken verteilen.
Ports
Ist ein Datenpaket innerhalb eines IP-Netzwerks an einem Host (also einem Gerät) angekommen, muss noch geklärt werden, wohin das Paket innerhalb des Geräts gehört. Da auf einem Computer viele Programme gleichzeitig aktiv sind, muss entschieden werden, für welches der Programme ein Paket gedacht ist. Dazu werden Ports genutzt. Ein Programm, welches Daten aus dem Netzwerk empfangen soll, nutzt dabei einen festgelegten Port. Kommt am Gerät ein Datenpaket an, das mit dem Port des Programms adressiert ist, wird das Paket an das entsprechende Programm geleitet und von diesem verarbeitet. Zum Beispiel “lauscht” der SSH-Server standardmäßig auf Port 22 für eingehenden Datenverkehr. Wir haben diesen Port in Lektion 3 manuell abgeändert.
Einige Ports sind fest für bestimmte Programme definiert und sollten nicht von anderen Programmen oder manuell belegt werden. Andere Ports können jedoch von Systemadministratoren frei genutzt werden. Die Portnummern reichen von 0 bis 65.535. Eine Auflistung aller Ports und deren Verwendung findet sich bei Wikipedia.
Ein Port kann auf einem Gerät offen oder geschlossen sein, z.B. kann eine Firewall die Kommunikation über einen Port blockieren. Außerdem muss ein Prozess hinter einem Port “hören”, damit eine Kommunikation aufgebaut werden kann.
Um zu sehen, welche Prozesse auf welchen Ports hören, kann der Befehl
netstat -tulp ausgeführt werden. Vorher muss dafür das
Paket net-tools installiert werden.
Firewall
Um Kommunikation in einem Netzwerk zu kontrollieren, werden Firewalls eingesetzt. Zu unterscheiden ist hierbei zwischen Hardware- und Desktopfirewalls. Eine Hardware- oder auch externe Firewall ist in der Regel ein dediziertes Gerät, welches primär unterschiedliche Netzwerke trennt. In einfacher Form kommt ein Heimrouter wie eine Fritz.Box dieser Aufgabe nach. Denn der Router trennt mit seiner Firewall das Internet vom Heimnetz und verhindert dadurch, dass aus dem Internet auf Geräte im Heimnetzwerk zugegriffen werden kann. In komplexeren Netzwerken (z.B. in Unternehmen) werden professionellere Geräte eingesetzt, welche mehr Funktionalität und Leistung bieten.
Eine Desktop- oder auch personal firewall dagegen ist meistens in Form von Software auf einem Gerät installiert. Unter Microsoft Windows wäre dies die Windows Defender Firewall, die den PC vor Zugriffen aus einem angeschlossenen Netzwerk schützt. Unter Linux kann dafür die uncomplicated firewall (kurz: UFW) genutzt werden.
Funktionsweise
Vereinfacht kann die Funktionsweise einer Firewall in mehrere Bereiche unterteilt werden. Dabei unterstützt nicht jede Firewall alle dieser Funktionen.
Paketfilter: filtert nach Adressen der Datenpakete (IP-Adressen, MAC-Adressen, Ports, URLs) -> Wer darf wohin?
Content/Proxy/Deep Packet-Filter: filtert nach dem Inhalt und kann so spezifische Inhalte blockieren. Z.B. kann Malware erkannt werden -> Was darf unterwegs sein?
Kombinierte Filter: durch die Kombination verschiedener Kriterien wie Uhrzeit, Herkunft der Anfrage, Ziel der Anfrage oder die Häufigkeit der Anfrage kann Datenverkehr blockiert oder erlaubt werden -> wie darf etwas unterwegs sein?
Geoblocking: häufig bieten Firewalls auch die Möglichkeit, Anfragen aus bestimmten Ländern zu blockieren. Allerdings können Angreifer solche Blockaden umgehen, indem sie Ihre Anfragen über Server in nicht blockierten Ländern leiten. Dennoch kann ein Geoblocking bisweilen massenhafte und wenig zielgerichtete Angriffsversuche unterbinden. -> Woher darf etwas kommen?
Ist ein Filterkriterium erfüllt, wird eine Aktion ausgeführt. Wird ein Paket verworfen (drop oder deny), wird es schlicht nicht weitergeleitet. Der Absender erhält darüber keine Auskunft. Wird ein Paket zurückgewiesen (deny oder reject) wird das Paket ebenfalls nicht weitergeleitet, der Absender wird allerdings direkt über den Kommunikationsabbruch informiert. Wird das Paket akzeptiert wird es an die Zieladresse weitergeleitet.
Allgemeine Tips zur Firewall
die Firewall muss immer aktiv sein
standardmäßig sollen eingehende Verbindungen blockiert werden
eingehende Verbindungen sollen nur für einzelne Ports und Anwendungen geöffnet werden
Sicherheit durch alternative Ports (wie beim SSH-Server) bringt nur ein wenig (siehe dazu den Wikipedia-Artikel zu Security through obscurity)
ein im Netzwerk exponiertes Programm (inkl. dem Betriebssystem) muss immer aktuell gehalten werden
die Kommunikation soll über verschlüsselte Protokolle stattfinden (TLS, SSH, HTTPS…)
für noch mehr Sicherheit kann gesorgt werden, wenn auch der ausgehende Datenverkehr gefiltert wird und nur explizit notwendige Anfragen, z.B. für Softwareupdates, zugelassen werden aber Anfragen ins lokale Netzwerk unterbunden werden. Siehe dazu ein Beispiel mit der IP-Tables-Firewall
Für Fortgeschrittene: mittels Port-knocking kann die Firewall nur kurzzeitig und explizit geöffnet werden und nach dem Ende der Kommunikation wieder geschlossen werden. Siehe dazu z.B. dieses Tutorial im Netz.
Umsetzung auf dem Server
(Installation:
sudo apt-get install ufw(ist standardmäßig bereits installiert))Regel hinzufügen:
sudo ufw allow <Portnummer>odersudo ufw deny <Portnummer>Standardregel für eingehenden Verkehr:
sudo ufw default deny incomingStandardregel für ausgehenden Verkehr:
sudo ufw default allow outgoingZugriff auf SSH-Port nur aus einem lokalen Netzwerk zulassen (Netzwerkadresse anpassen!):
sudo ufw allow from 192.168.178.0/24 to any port 22Firewall aktivieren:
sudo ufw enableStatus anzeigen lassen:
sudo ufw statusStatus mit Nummer anzeigen lassen:
sudo ufw status numberedRegel löschen:
sudo ufw delete <Nummer-der-Regel>
Im Netz finden sich zahlreiche Anleitungen für die UFW. Empfehlenswert sind die Anleitungen von DigitalOcean und PiMyLifeUp
Fail2Ban
Nachdem in der (uncomplicated) Firewall ein Port geöffnet wurde, kann die Kommunikation mit dem hinter dem Port wartenden Dienst stattfinden. Jedoch ist es empfehlenswert diese Kommunikation weiterhin im Blick zu behalten.
Für einfache Szenarien kann das Programm Fail2Ban genutzt werden, um unerwünschte Eindringversuche zu erkennen und zu blockieren. Ein typischer Angriffsversuch, welcher mit Fail2Ban abgefangen werden kann, ist eine Brute-Force-Attacke, bei welcher durch massenhafte Anfragen versucht wird, Benutzername und Passwort zu erraten. Die dabei unweigerlich zahlreich auftretenden Fehlversuche werden in einer Protokolldatei im System notiert. Durch die Überwachung dieser Protokolldatei (auch als Logdatei bezeichnet) kann Fail2Ban die Absenderadresse der massenhaften Loginversuche erkennen und blockieren, indem die Adresse der Firewall als zu blockierende Adresse mitgeteilt wird.
Zu Fail2Ban gibt es im Netz verschiedne Anleitungen. Z.B. im offiziellen Raspberry Pi Handbuch oder wieder bei PiMyLifeUp.
Umsetzung auf dem Ubuntu-Server:
Installation:
sudo apt-get install fail2banAktivierung:
sudo cp /etc/fail2ban/jail.conf /etc/fail2ban/jail.local-
Beispielkonfiguration der Standardparameter mittels
sudo nano /etc/fail2ban/jail.localStandard Sperrzeit:
bantime = 20mStandardanzahl möglicher Fehlversuche:
maxretry = 3Standardzeit für “maxretry”:
findtime = 10m
-
Zu überwachende Services/Ports werden am Ende der Datei
/etc/fail2ban/jail.localmit[<Name>]definiert und mit Detaileinstellungen konfiguriert:Aktivierung:
enabled = trueAngabe des Ports:
port = <Portnummer des ServicesAngabe der zu überwachenden Logdatei:
logpath = <Pfad zur Logdatei>Angabe des Filters, mit dem die Logdatei geprüft wird:
filter = <Name der Datei im Verzeichnis /etc/fail2ban/filter.d/>
Beispiel für den SSH-Server:
BASH
#Standardeinstellungen vornehmen
bantime = 60m
findtime = 15m
maxretry = 3
# Im Bereich [sshd]
[sshd]
enabeld = true
port = <ssh-port>
logpath = %(sshd_log)s
backend = systemd
filter = sshdNetzwerksicherheit
Sie sollen für Ihre Arbeitsgruppe einen kleinen Server mit diversen Diensten betreiben (z.B. einen Cloudserver). Wie gewährleisten Sie die Netzwerksicherheit, um unbefugten Zugriff auf den Server zu verhindern?
Einige wichtige und grundlegende Maßnahmen können sein:
Firewall auf dem Server aktivieren
Eingehende Verbindungen blockieren
nur einzelne Ports für die notwendigen Dienste und nur innerhalb des lokalen Netzwerkes freigeben
Mit Fail2Ban oder vergleichbaren Tools fehlerhafte Loginversuche überwachen
Regelmäßige Wartung: Sowohl der Server als auch alle anderen Netzwerkkomponenten (Router, Switche etc) müssen stets mit aktueller Soft- und oder Firmware ausgestattet werden.
der SSH-Serverdienst sollte entsprechend Lektion 3 konfiguriert werden
Noch mehr Sicherheit erhalten Sie durch eine Netzwerksegmentierung: sie trennen das Netzwerk in mehrere logische Bereiche auf, zwischen denen ein Router mit Firewall vermittelt.
Schützen Sie den Server(raum) auch physikalische vor unbefugtem Zugriff: die Hardware sollte nur für berechtigte Personen zugänglich sein.
Computer kommunizieren im Netzwerk nach Standards, das OSI-Schichten-Modell stellt einen Leitrahmen für diese Standards dar
Versendete Daten im Netzwerk haben immer einen Absender- und einen Empfänger (in Form von MAC-Adresse, Netzwerk-ID, IP-Adresse und Port)
Mit einer Firewall können Ports geöffnet und geschlossen werden
Mit Fail2Ban können fehlerhafte Loginversuche festgestellt und blockiert werden
Content from Grundlegendes zu Docker
Zuletzt aktualisiert am 2026-05-12 | Diese Seite bearbeiten
Übersicht
Fragen
Was ist Virtualisierung
Was sind Container
Wie nutze ich Docker
Ziele
Theoretische Grundlagen von Virtualisierungstechnologien
Vergleich von Containern und virtuellen Maschinen
Installation und Nutzung der Docker Engine
Virtualisierungsstrategien:
Bereitstellung von Serverdiensten
Die traditionelle Bereitstellung von Serverdiensten erfolgt durch die Installation eines Betriebssystems direkt auf der Hardware, gefolgt von der Installation der benötigten Anwendungen. Diese Methode hat jedoch einige Nachteile: Es erfolgt keine Trennung der Anwendungen und Prozesse, wodurch bei Kompromittierung einer Anwendung das gesamte System betroffen ist. Zudem werden die Hardwareressourcen ineffizient genutzt, was zu höheren Kosten bei Hardwarebeschaffung und Stromverbrauch führt und damit auch den Prinzipien der Green-IT widerspricht.
Heute wird daher häufiger auf Virtualisierung gesetzt. Virtualisierung bedeutet, dass Hardwareressourcen wie Prozessor, Arbeitsspeicher, Festplattenspeicher, Netzwerk oder Grafikkarte durch spezielle Virtualisierungsprogramme unterteilt werden und virtuellen Maschinen zugeteilt werden. Dies führt zu einer effizienteren Nutzung der Hardware und erhöht die Sicherheit durch die Trennung der Anwendungen.
Dabei wird das System mit der physischen Hardware, auf welchem die Virtualisierungsprogramme laufen, als Host oder Wirt bezeichnet. Als Gast wird die virtualisierte Umgebung bezeichnet.
Unterschiedliche Typen der Virtualisierung:
Typ-1: Hierbei handelt es sich um spezielle Betriebssysteme, die primär der Virtualisierung dienen. Solche Systeme werden auch als Hypervisor bezeichnet. Bei diesen Systemen werden der virtuellen Maschine die Hardwareressourcen direkt zugeteilt. Diese Methode ist performanter als Typ-2 und wird hauptsächlich für die Servervirtualisierung in Rechenzentren oder Unternehmensnetzwerken verwendet.
Typ-2: Bei dieser Methode läuft ein normales Desktop-Betriebssystem (Windows, Linux, MacOS) auf der physischen Hardware. Innerhalb dieses Systems wird die Virtualisierungssoftware installiert und diese Software verwaltet die Zuteilung der Hardwareressourcen auf die virtuellen Maschinen. Diese Methode wird häufig für lokale Tests, in der Entwicklung oder für die parallele Nutzung von (unterschiedlichen) Betriebssystemen verwendet. Sie ist einfacher in der Handhabung, bietet aber weniger Leistung und Funktion.
Containervirtualisierung: Hierbei haben die virtualisierten Anwendungen direkten Zugriff auf die Hardware und den Kernel des Betriebssystems. Anstatt die Hardware zu virtualisieren wird nur die Software virtualisiert. Dabei wird nicht das gesamte Betriebssystem virtualisiert, sondern nur die benötigte Anwendung und deren Abhängigkeiten. Man spricht hier auch von Microservices. Dies führt zu einer geringeren Trennung der Anwendungen und reduziert damit die sicherheitstechnischen Vorteile einer virtuellen Maschine. Die Containervirtualisierung bietet jedoch eine höhere Performance, da sie “näher” an der Hardware des Hosts arbeitet. Containervirtualisierung wird häufig für die Bereitstellung von Anwendungen in komplexen Serverumgebungen oder als Entwicklungsumgebung verwendet. Ein Beispiel für Containervirtualisierung ist Docker: Dockercontainer haben ihr eigenes Dateisystem mit eigenen Benutzerrechten, nutzen jedoch direkt den Kernel des Hosts.
Weiterführende Quellen
- Virtualisierung allgemein (IBM 1)
- Container vs. virtuelle Maschinen (IBM 2)
- Containervirtualisierung (IBM 3)
Virtualisierungstypen
Recherchieren Sie zu den folgenden Produkten und ordnen Sie diese den entsprechenden Virtualisierungstechnologien zu:
- Proxmox
- VirtualBox
- Docker
- Kubernetes
- Hyper-V
Proxmox: Typ-1-Virtualisierung basierend auf dem Betriebssystem Debian und aufbauend auf der KVM-Technologie.
VirtualBox: Typ-2-Virtualisierung. VirtualBox ist eine Open-Source-Virtualisierungssoftware, die auf einem bestehenden Betriebssystem läuft und es ermöglicht, mehrere Gastbetriebssysteme zu betreiben.
Docker: Containervirtualisierung. Docker ist eine Plattform, die es ermöglicht, Anwendungen in Container zu verpacken, die unabhängig von der zugrunde liegenden Infrastruktur ausgeführt werden können.
Kubernetes: Containervirtualisierung. Kubernetes ist ein von Google entwickeltes Open-Source-System zur Automatisierung der Bereitstellung, Skalierung und Verwaltung von containerisierten Anwendungen.
Hyper-V: Typ-1-Virtualisierung. Hyper-V ist eine Virtualisierungsplattform von Microsoft, die es ermöglicht, mehrere Betriebssysteme auf einem einzigen physischen Server zu betreiben.
Docker Engine
Docker ist eine bekannte und weit verbreitete Open-Source-Software für Containervirtualisierung. Die Docker Engine läuft als Hintergrundprozess auf dem Betriebssystem (Daemon), um die Container zu steuern. Dieser Prozess muss aktiv sein, um Docker nutzen zu können.
Komponenten
Einige wichtige Komponenten der Docker Engine sind die folgenden:
Images
Images bilden die Grundlage eines Containers. Ein Image enthält alle notwendigen Dateien und Abhängigkeiten, die benötigt werden, um eine Anwendung auszuführen. Dies umfasst das Betriebssystem, die Anwendungssoftware, Bibliotheken und Konfigurationsdateien. Images werden über Registries wie Docker Hub oder GitHub zur Verfügung gestellt, wo sie heruntergeladen und verwendet werden können.
Container
Ein Container ist eine aktive Instanz, die aus einem Image erstellt wird. Aus einem einzigen Image können mehrere Container erstellt werden. Jeder Container ist eine isolierte Umgebung, die unabhängig von anderen Containern läuft. Dies ermöglicht es, mehrere Anwendungen auf demselben Host-System auszuführen, ohne dass sie sich gegenseitig beeinflussen.
Volumes
Volumes sind persistente Datenspeicher, die verwendet werden, um Daten dauerhaft zu speichern. Im Gegensatz zu den Dateien innerhalb eines Containers, die bei der Beendigung des Containers verloren gehen, bleiben die Daten in einem Volume erhalten. Volumes sind besonders nützlich für Anwendungen, die Daten über mehrere Container-Instanzen hinweg speichern müssen, wie z.B. Datenbanken oder Log-Dateien.
Installation
Die Installation der Docker Engine auf Ubuntu kann mittels einer von Docker zur Verfügung gestellten Fremdquelle erfolgen. Die Schritte sind dem offiziellen Handbuch zu entnehmen. Nutzen Sie die Installationsvariante mittels apt-Repository und installieren Sie die aktuellste Version (“Latest”).
Überprüfen Sie anschließend die Installation mit dem Befehl
docker -v. Dieser Befehl sollte Ihnen die aktuelle
Versionsnummer von Docker zurück liefern.
Konfiguration
Nach der Installation der Docker Engine sind einige Konfigurationsschritte notwendig, um die Docker-Umgebung optimal zu nutzen.
Der Docker Daemon kann mit der Datei
/etc/docker/daemon.json angepasst werden. Diese muss
manuell erstellt werden
(sudo nano /etc/docker/daemon.json). Die
Konfigurationsoptionen für den Docker Daemon werden in dieser Datei im
JSON-Format eingetragen. Eine wichtige Konfiguration ist die
Logrotation, die sicherstellt, dass die Log-Dateien nicht unbegrenzt
wachsen.
Logrotation
Um die Logrotation zu konfigurieren, fügen Sie die die folgenden
Zeilen der daemon.json-Datei hinzu.
Weitere Informationen zur Logrotation finden Sie in der offiziellen Dokumentation: Docker Logging Drivers.
Autostart einrichten
Um sicherzustellen, dass der Docker-Dienst beim Systemstart automatisch gestartet wird, müssen Sie den Autostart einrichten. Dies erfoglt unter Ubuntu mit Systemd:
Weitere Informationen dazu finden Sie in der Dokumentation.
Die Qual der Wahl
Sie haben den Auftrag erhalten, an Ihrem Institut für eine kleine Arbeitsgruppe eine Website und eine Webapplikation zum Dateiaustausch (“Cloud”) zu betreiben. Dazu wird Ihnen ein kleiner Server mit Ubuntu-Betriebssystem zur Verfügung gestellt. Ihr Institut hat mehrere Arbeitsgruppen, die bislang Ihre Daten nur auf lokalen Festplatten speichern.
Welche Installationsvariante wählen Sie?
Ich installiere einen Webserver in Ubuntu (“bare metal”). Dieser stellt sowohl die Website als auch auf einer zweiten Internetseite die Webapplikation zum Datenaustausch bereit.
Ich installiere einen Webserver in Ubuntu und einen Docker-Container für die Webapplikation. Der Webserver stellt die Website bereit und leitet Anfragen an die Webapplikation an den Docker-Container weiter.
Ich installiere einen Webserver in Ubuntu und je einen Docker-Container für die Webapplikation und die Website. Der Webserver leitet alle Anfragen an den jeweiligen Docker-Container weiter.
Ich installiere drei Docker-Container: Webserver, Website und Webapplikation. Der Webserver-Container leitet die Anfragen an den Website- oder Webapplikations-Container weiter.
Ich installiere eine virtuelle Maschine für die Webapplikation und betreibe die Website direkt im Ubuntu-System (“Bare metal”)
In Anbetracht der weiteren Arbeitsgruppen, die evtl. zukünftig ebenfalls eine Plattform zum Datenaustausch benötigen, erscheint es sinnvoll, diese Plattform als Docker-Container zu betreiben. Dadurch besteht die später die Möglichkeit, diesen Container einfach zu duplizieren und damit weiteren Arbeitsgruppen eine Instanz zur Verfügung zu stellen.
Der Webserver kann ebenfalls als Docker-Container betrieben werden. Dadurch ist das gesamte Setup unabhängig vom Host-Betriebssystem und kann wenn nötig einfacher auf andere Hardware migriert werden.
Demnach erscheint Antwort 4 passend. Die genaue Wahl hängt aber auch von individuellen Gegebenheiten ab (Know-How des IT-Teams, Performance des Servers, Vorgaben der Organisation, vorhandene Strukturen, künftige Projekte).
Steuerung der Docker Engine
Die Steuerung von Docker erfolgt über den docker Befehl,
der in der Regel mit sudo ausgeführt werden muss, um die
notwendigen administrativen Rechte zu haben. Hier sind einige wichtige
Befehle und ihre Funktionen:
docker ps
Der Befehl docker ps listet alle aktiven Container auf.
Dies ist nützlich, um einen Überblick über die laufenden Container zu
erhalten und deren Status zu überprüfen.
docker run
Der Befehl docker run wird verwendet, um einen neuen
Container aus einem Image zu starten. Dieser Befehl erfordert mindestens
das Image, aus dem der Container erstellt werden soll, und kann
zusätzliche Optionen enthalten, wie z.B. die Zuweisung von Ressourcen
oder die Angabe von Umgebungsvariablen.
docker cp
Der Befehl docker cp wird verwendet, um Dateien oder
Verzeichnisse zwischen dem Host-System und einem Container zu kopieren.
Dies ist nützlich, um Daten in einen Container zu importieren oder aus
einem Container zu exportieren.
docker network
Der Befehl docker network bietet verschiedene
Unterbefehle zur Verwaltung von Docker-Netzwerken: -
docker network ls listet alle vorhandenen Netzwerke auf. -
docker network inspect <Netzwerkname> zeigt
detaillierte Informationen über ein bestimmtes Netzwerk an, z.B.
IP-Adressen und verbundene Container -
docker network create <Netzwerkname> erstellt ein
neues Netzwerk (standardmäßig als sog. Bridge-Netzwerk).
Siehe dazu auch Dockernetzwerke
docker prune
Der Befehl docker prune bietet verschiedene Unterbefehle
zur Bereinigung von Docker-Ressourcen: -
docker system prune entfernt alle ungenutzten Daten
(Images, Container, Netzwerke und Volumes). -
docker image prune entfernt alle ungenutzten Images. -
docker network prune entfernt alle ungenutzten Netzwerke. -
docker volume prune entfernt alle ungenutzten Volumes.
Kommunikation im “Dockerversum”: Dockernetzwerke
Um Containern die Kommunikation im Netzwerk zu ermöglichen, erstellt die Docker beim Start der Container standardmäßig auch virtuelle Netzwerke. In der Standardkonfiguration haben Container Internetzugriff über die Internetschnittstelle des Hosts. Allerdings kommunizieren Sie in einem eigenen Subnetz und sind daher nicht von außen erreichbar.
Docker-Netzwerke
Es gibt verschiedene Netzwerktypen, die von der Docker Engine oder manuell erstellt werden können. Die wichtigsten sind Bridge, Host und Overlay.
Bridge-Netzwerke sind virtuelle Netzwerke, an welche Container gebunden werden können. Alle Container innerhalb desselben Bridge-Netzwerks können miteinander kommunizieren, entweder über ihre IP-Adressen oder über ihre Container-Namen. Auf dem Host ist das Bridg-Netzwerk ebenfalls sichtbar, allerdings ist das Bridge-Netzwerk nicht direkt mit der Netzwerkschnittstelle des Hosts verbunden, sondern befindet sich hinter der Netzwerkschnittstelle des Hosts. Damit hat das Bridge-Netzwerk keinen Zugriff auf das LAN des Hosts. Über Portmapping kann aber die Kommunikation mit dem LAN-Netzwerk des Hosts ermöglicht werden.
Host-Netzwerke verbinden Container auf derselben physischen Netzwerkschnittstelle wie den Host. Dadurch befindet sich das Host-Netzwerk “neben” dem Host selbst und hat direkten Zugriff auf das LAN des Hosts und erhält auch dort eine IP-Adresse. Dies hat zwar den Vorteil des direkten Zugriffs, ist aber aufgrund der geringeren Isolierung des der verbundenen Container auch weniger sicher.
Overlay-Netzwerke dienen der Verbindung von Containern über unterschiedliche Hosts hinweg. So ist es z.B. möglich Docker-Container, die auf zwei unterschiedlichen Servern laufen und dort jeweils in einem Bridge-Netzwerk isoliert sind, zusätzlich mit einem Overlay-Netzwerk kommunizieren zu lassen.
Portmapping
Um die Kommunikation von Host zu Gast zu ermöglichen können Anfragen
an bestimmte Ports des Hosts an bestimmte Ports des Gasts weitergeleitet
werden. Dadurch können Container von außerhalb eines Bridge-Netzwerks
erreicht werden. Es ist jedoch wichtig zu beachten, dass dadurch die
Regeln der UFW umgangen werden. Deshalb sind für im Internet exponierte
Container ggf. eigene Firewallregeln zu erstellen (siehe dazu das Handbuch).
Um Ports des Containers auf dem Host verfügbar zu machen (zu
veröffentlichen (“publish”)) dient der Parameter -p des
docker run-Befehls.
Mehr Informationen zu Docker-Netzwerken findet sich im Handbuch.
Container mit der Docker Engine erstellen
Der Befehl
docker run <Imagename>:<Image-Tag> wird
verwendet, um einen neuen Container aus einem Image zu starten. Wenn das
angegebene Image nicht lokal vorhanden ist, wird es automatisch aus
einer Registry wie Docker Hub heruntergeladen und der Container
wird gestartet. Dabei gibt es verschiedene Parameter, die die
Konfiguration des Containers beeinflussen können. Einige wichtig
Parameter sind dabei die Folgenden:
-pfür Portfreigaben: Dieser Parameter wird verwendet, um Ports auf dem Host-System an Ports im Container zu binden. Dies ermöglicht es, auf Dienste im Container von außerhalb zuzugreifen. Beispiel:docker run -p 80:80 nginx. Dieser Befehl startet einen Docker-Container basierend auf dem nginx-Image. Dabei wird der Port80auf dem Host-System auf den Port80innerhalb des Containers weitergeleitet. Dadurch kann von außerhalb des Containers auf Port80innerhalb des Containers zugegriffen werden. Es ist aber auch möglich unterschiedliche Ports zu nutzen:docker run -p 12000:80 nginx-vfür Volumes: Dieser Parameter wird verwendet, um Verzeichnisse oder Dateien zwischen dem Host-System und dem Container zu teilen. Dies ist nützlich, um Daten persistent zu speichern oder Konfigurationsdateien zu teilen.Weitere Parameter: Eine vollständige Liste der verfügbaren Parameter kann mit dem Befehl
docker run --helpangezeigt werden.tag: Der tag gibt die Version des Images an. Wenn kein tag angegeben wird, wird standardmäßig das Image mit dem tag
latestverwendet.
Beispiel: Apache Webserver
Um einen Apache Webserver in einem Docker-Container zu starten, können Sie den folgenden Befehl verwenden:
-
Starten des Containers:
sudo docker run -dit --name apache -p 8080:80 -v "$PWD":/usr/local/apache2/htdocs/ httpd:2.4-
-dit: Startet den Container im Hintergrund und behält die Terminalsitzung offen. -
--name apache: Gibt dem Container den Namenapache. -
-p 8080:80: Bindet den Port 8080 auf dem Host-System an den Port 80 im Container. -
-v "$PWD":/usr/local/apache2/htdocs/: Bindet das aktuelle Arbeitsverzeichnis (“Working directory:pwd) auf dem Host-System an das Verzeichnis/usr/local/apache2/htdocs/im Container. -
httpd:2.4: Verwendet das Imagehttpdmit dem tag2.4.
-
Ansprechen des Containers: Um zu überprüfen, ob der Apache Webserver läuft, können Sie den folgenden Befehl verwenden:
curl localhost:8080Dieser Befehl sendet eine HTTP-Anfrage an den Apache-Container und gibt die Antwort auf der Kommandozeile zurück.Stoppen des Containers: Um den Apache Webserver-Container zu stoppen, können Sie den folgenden Befehl verwenden:
docker stop apache
- durch Virtualisierung können Ressourcen effektiver genutzt werden
- Container bieten eine performante Virtualisierungslösung an
- mit Docker können verschiedene Anwendungen in isolierten Umgebungen (Containern) auf demselben System betrieben werden
- Mit Docker Netzwerken kann die Kommunikation zwischen Containern und dem Host gesteuert werden
Content from Docker compose
Zuletzt aktualisiert am 2026-05-12 | Diese Seite bearbeiten
Übersicht
Fragen
Muss ich Container immer mit dem komplexen
docker run-Befehl starten?Wie kann ich mehrere Container auf einmal starten?
Wie funktioniert Docker Compose?
Ziele
- Grundlegende Befehle für docker compose
- Syntax von docker-compose.yml-Dateien
- Docker-Projekte mit mehreren Containern als Docker-Compose-Projekt
docker run versus docker compose
In Lektion 6: Docker Grundlagen
wurde gezeigt, wie mit dem docker run-Befehl einzelne
Container erstellt werden können. Allerdings kann der Befehl recht
komplex werden, wenn Portmappings, Volumes, Umgebungsvariablen und
Netzwerk hinzukommen. Um die langen Befehle nicht immer von neuem zu
tippen, können sie in eine Konfigurationsdatei
(compose.yaml oder docker-compose.yaml)
geschrieben werden. Diese wiederum kann mit dem
docker compose-Befehl gelesen und ausgeführt werden. Um
Docker Compose nutzen zu können, muss dies installiert werden. Folgt man
der offiziellen Installationsanleitung für die Docker Engine (siehe Lektion 6), ist docker
compose bereits installiert. Dies kann z.B. mit
docker compose -v überprüft werden.
Allerdings müssen die Befehle in einer bestimmten Syntax, der YAML-Syntax geschrieben werden.
Vorteile:
Gemeinsame Verwaltung mehrerer Container: Mit Docker Compose können mehrere Container in einer einzigen YAML-Datei definiert werden.
Verwaltung: Mit Docker Compose können alle Container der YAML-Datei mit einem einzigen Befehl verwaltet werden. Dies macht es einfacher, Container zu starten, zu stoppen oder zu aktualisieren.
Kommunikation: Alle Container der YAML-Datei sind standardmäßig in einem dedizierten Bridge-Netzwerk isoliert. Dies erleichtert die Kommunikation zwischen den Containern und erhöht gleichzeitig die Sicherheit durch die Trennung von anderen Compose-Projekten.
Nachhaltiger: Da die YAML-Datei leicht einsehbar ist und weitergegeben werden kann, ist Docker Compose eine nachhaltigere Lösung als der
docker run-Befehl.Anpassbar: Docker Compose ist einfach anpassbar, da nur die YAML-Datei geändert werden muss, um die Konfiguration der Container anzupassen.
Gut steuerbar: Mit der Docker CLI besteht durch den
docker compose-Befehl eine einfache Möglichkeit, die Docker-Container des Compose-Projekts zu starten, zu stoppen oder zu aktualisieren:docker compose up,docker compose down,docker compose restart,docker compose startunddocker compose stop.
Nachteile:
Der größte Nachteil von docker compose ist, dass zum Starten eines Containers erst eine Konfigurationsdatei im YAML-Syntax erstellt werden muss. Sobald diese einmal erstellt ist, ist dieser Nachteil aber überwunden.
YAML-Syntax
YAML ist eine einfache und leicht lesbares Dateiformat zur strukturierten Abbildung von Daten. Die YAML-Syntax wird in vielen Bereichen, einschließlich Docker, verwendet um Konfigurationsdateien zu verfassen.
Die grundlegende Syntax von YAML besteht aus Key-Value-Paaren:
key: value, z.B. image: nginx. Dabei wird auch
von Maps gesprochen. Im vorhergehenden Beispiel wird die Map “Image”
erstellt. Eine Map kann aber außer einem Value auch eine Liste
enthalten:
Dieser Auszug einer compose-Datei zeigt die “ports”-Map mit zwei
Listeneinträgen. Der entsprechende docker run-Befehl würde
wie folgt lauten:
docker run <image> -p 80:80 -p 443:443
Um der Konfigurationsdatei Informationen und Erklärungen
hinzuzufügen, erlaubt die YAML-Syntax Kommentare: alle Zeilen, die mit
# beginnen werden als Kommentar betrachet.
Wichtige Keys in Docker Compose sind:
-
services: Top-Level-Map, die eine pro zu startendem Service eine weitere Map enthält. Ein Service entspricht dabei einem Container. - Die Maps pro Service haben dann weitere Parameter, teils als weitere Maps, teils als Liste. Wichtig sind dabei:
-
imagefür die Angabe des Dockerimages -
dockerfilefür die Angabe eines manuell erstellten Dockerfiles (mehr dazu später) -
portsfür die Angabe des Portmappings -
networksfür die Angabe des Netzwerks, in welchem der Container sich befinden soll -
environmentum Umgebungsvariablen zu definieren -
volumesum Dateien/Ordner des Hosts in den Container zu binden -
networks: Findet sich der Keynetworksauf obererster Ebene, dient er der Erstellung eines Docker-Netzwerks oder der Verbindung zu einem zuvor außerhalb von Compose erstellten Docker-Netzwerks.
Ein Beispiel für eine compose.yaml-Datei könnte wie
folgt aussehen:
YAML
services:
frontend:
image: nginx:latest
ports:
- "80:80"
networks:
- web
environment:
- NGINX_PORT=80
volumes:
- ./html:/usr/share/nginx/html
networks:
web:
name: web
external: trueIn diesem Beispiel definiert die compose.yaml-Datei
einen Service namens frontend, der auf einem Nginx-Image
basiert und auf Port 80 hört. Der Service ist Teil des Netzwerks
web und hat eine Umgebungsvariable namens
NGINX_PORT. Der Service hat auch einen Volume-Mount, der
auf eine lokale Datei ./html verweist. Am Ende wird in der
Network-Map das Netzwerk web als extern definiert (es muss also zuvor
mit docker network create web erstellt worden sein).
Viele Softwareprojekte stellen compose.yaml-Dateien für ihre Dienste bereits in Handbüchern oder als Teil des Source-Codes zur Verfügung (z.B. Jellyfin, Nextcloud oder Nginx Proxy Manager). Diese Vorlagen müssen meistens noch den eigenen Gegebenheiten angepasst werden oder können mit weiteren Services ergänzt werden.
Weitere Informationen zur YAML-Syntax finden sich z.B: bei Red Hat und dockerspezifische Infos im Handbuch
Umgebungsvariablen
Docker ermöglicht es, einem Container beim Start vordefinierte Werte
für bestimmte Einstellungsparameter mitzugeben, z.B.
Verbindungsinformationen für eine Datenbank. Diese Umgebungsvariablen
können entweder in der compose.yaml-Datei als Liste innerhalb der Map
environment genannt werden oder in einer eigenen
Konfigurationsdatei auflistet werden. Standardmäßig sucht Docker Compose
nach der Datei mit dem Nachem .env. Man kann diese aber
auch anders bennenen und in der Compose-Datei darauf verweisen. Die
Variablen können dann an mehreren Stellen der Compose-Datei als
Platzhalter verwendet werden.
Compose.yaml mit environment-Map
Hier ein Beispiel für eine compose.yaml-Datei für einen
Webservice, welcher sich mit einer Datenbank verbindet. Dei
Verbindungsinformationen kommen aus einem environment Eintrag, müssen
jedoch für beide Services erklärt werden.
YAML
version: '3'
services:
web:
image: web-app
ports:
- "5000:5000"
environment:
- DATABASE_USER=db_user
- DATABASE_PASSWORD=db_password
- DATABASE_HOST=db
- DATABASE_NAME=my_db
depends_on:
- db
db:
image: mariadb
environment:
- MYSQL_USER=db_user
- MYSQL_PASSWORD=db_password
- MYSQL_DATABASE=my_db
- MYSQL_ROOT_PASSWORD=root_passwordIn diesem Beispiel gibt es zwei Dienste: web und
db. Der web-Dienst verwendet das (erfundene)
web-app-Image und macht den Port 5000 verfügbar. Der
db-Dienst verwendet das mariadb-Image und
erstellt eine Datenbank mit dem Namen my_db.
Der web-Dienst hat einen
environment-Eintrag, der die DATABASE_USER,
DATABASE_PASSWORD, DATABASE_HOST und
DATABASE_NAME-Variablen setzt. Diese Variablen werden
verwendet, um die Verbindung zur Datenbank herzustellen.
Der db-Dienst hat auch einen
environment-Eintrag, der die MYSQL_USER,
MYSQL_PASSWORD, MYSQL_DATABASE und
MYSQL_ROOT_PASSWORD-Variablen setzt. Diese Variablen werden
verwendet, um den Benutzernamen, das Passwort, den Datenbanknamen und
das Root-Passwort für die MariaDB-Datenbank zu konfigurieren.
Der web-Dienst hat auch einen
depends_on-Eintrag, der angibt, dass er vom
db-Dienst abhängig ist. Das bedeutet, dass der
db-Dienst gestartet wird, bevor der web-Dienst
gestartet wird.
Compose.yaml mit externer .env-Datei für Variablen
Eleganter ist in diesem Beispiel die Nutzung einer dedizierten
.env-Datei (hier mit dem Namen variables.env
):
YAML
DATABASE_USER=db_user
DATABASE_PASSWORD=db_password
DATABASE_HOST=db
DATABASE_NAME=my_db
MYSQL_USER=db_user
MYSQL_PASSWORD=db_password
MYSQL_DATABASE=my_db
MYSQL_ROOT_PASSWORD=root_passwordDurch den Verweis auf diese Datei in der compose.yaml-Datei, müssen die Variablen nur einmal geschrieben werden:
YAML
version: '3'
services:
web:
image: my-web-app
ports:
- "5000:5000"
env_file:
- variables.env
depends_on:
- db
db:
image: mariadb
env_file:
- variables.envÄndert sich der Wert einer der genannten Variablen, genügt es bei diesem Setup, nur in der variables.env-Datei die Änderung einzutragen.
Compose Projekte steuern
Mit dem docker compose-Befehl können die in der
compose.yaml-Datei definierten Services gesteuert werden.
Die grundlegenden docker-compose-Befehle sind:
-
docker compose up: Startet alle in derdocker-compose.yml-Datei definierten Dienste im Vordergrund -
docker compose down: Beendet alle Dienste und entfernt alle Container. -
docker compose restart: Beendet alle Dienste und startet sie neu. -
docker compose start: Startet alle Dienste. -
docker compose stop: Beendet alle Dienste. -
docker compose up -d: startet alle Container im Hintergrund -
docker compose ps: zeigt den Status der Dienste an -
docker compose exec: ermöglicht es, einen Befehl in einem Docker-Container auszuführen. Zum Beispiel:docker-compose exec <container-name> bash.
Allen Befehlen kann auch ein expliziter Container-Name mitgegeben, um
die Aktion nur auf diesen Container anzuwenden, z.B.
docker compose restart nginx
Mit Docker Compose können Dockercontainer effektiver verwaltet werden
Docker Compose benötigt die compose.yaml-Konfigurationsdatei
Diese compose.yaml-Datei verwendet den YAML-Syntax
die Steuerung erfolgt mit dem Befehl
docker compose
Content from Webserver mit Docker Compose
Zuletzt aktualisiert am 2026-05-12 | Diese Seite bearbeiten
Übersicht
Fragen
Wie können Webapplikation im Internet erreichbar gemacht werden?
Wie funktionieren Webserver?
Wie sichere ich die Kommunikation ab?
Wie kann ein Webserver in Docker Compose erstellt werden
Ziele
- Grundlagen von Webservern
- Domainnamen mit DDNS erhalten
- TLS-Zertifikate mit Letsencrypt erhalten
- Webserver mit Docker compose erstellen
Allgemeines zu Webservern
Webserver sind Softwarekomponenten, die auf Anfragen von Clients (z.B. Browsern) reagieren und diese Anfragen an eine Webapplikation (oder weitere Webserver) weiterleiten. Damit spielen sie eine wichtige Rolle in der Bereitstellung von Webapplikationen.
Abhängig von der angefragten Domain (uni-tuebingen.de)
oder der konkreten Datei (uni-tuebingen.de/index.html) wird
der Webserver Dateien zurück liefern, an eine Webapplikation
weiterleiten oder Funktionen ausführen. Dies ermöglicht es auch, mehrere
Webapplikationen auf einem einzigen Server zu hosten und den
Datenverkehr effizient zu verwalten.
Durch die Überwachung der Verbindung zwischen Client und Webapplikation kann sichergestellt werden, dass die Verbindung stabil und zuverlässig ist. Für Verbindungen über das Internet oder andere unsichere Netzwerke sollte immer eine verschlüsselte Kommunikation aufgebaut werden. Diese wird ebenfalls im Webserver konfiguriert (z.B. mit TLS-Zertifikaten für die HTTPS-Verbindung).
Webserver können auch die Authentifizierung von Benutzern ermöglichen oder Anfragen auf Basis bestimmter Kriterien (z.B. Herkunft der IP-Adresse oder Anfragehäufigkeit) blockieren. Dadurch kann unerwünschter Traffic blockiert werden, die Leistung der Webapplikation verbessert werden und die Sicherheit erhöht.
Eine weitere Funktionalität ist das Load-Balancing. Hierbei kann ein Webserver große Mengen an angefragten Daten auf mehrere sogenannten Upstream-Server verteilen, um die Last je Server in Grenzen zu halten.
Da der Webserver der zentrale Kommunikationsknoten zwischen Webapplikation und Client ist, ist dessen Konfiguration für die Sicherheit und Stabilität der Webapplikation (bzw. der Kommunikation mit dieser) äußerst wichtig. Die genaue Konfiguration eines Webservers ist jeweils abhängig vom genauen Einsatzzweck. Für viele Webapplikationen stellen die Hersteller Vorlagen für Konfigurationen der Webserver bereit.
Einige wichtige Webserver sind:
- Nginx (offene Lizenz, modern, eher leichtgewichtig, weit verbreitet)
- Apache2 (offene Lizenz, der “Dinosaurier” unter den Webserver, performant, weit verbreitet)
- Microsoft IIS (proprietär)
- Google Web Server (proprietär, nur von Google-Diensten verwendet)
Externer Zugriff
Um einen Webserver aus dem Internet erreichen zu können, muss der Server, auf welchem die Webserver-Software installiert ist, und das Netzwerk in welchem sich der Server befindet eine öffentliche IP-Adresse und idealerweise auch einen öffentlich bekannten Domainnamen haben.
Für diesen Kurs ist der Hypervisor, auf welchem die virtuellen Server laufen, über eine IP-Adresse im Internet erreichbar. Ein zentraler Webserver ist als Proxy-Server konfiguriert und leitet Anfragen abhängig von der angefragten Domain intern an die jeweilige virtuelle Maschine weiter. Dort muss dann ein eigener Webserver die Anfrage annehmen und verarbeiten.
Allerdings müssen Sie eine Domain für Ihren Server konfigurieren.
Hierzu kann kostenpflichtig eine vollwertige Domain erworben werden
(domain.de) oder man nutzt kostenlose DDNS-Dienste
(DDNS=Dynamic Domain Name System).
DDNS funktioniert unter Zuhilfenahme eines externen Dienstleisters. Bei diesem wird eine Subdomain beantragt, z.B. server.ddns-anbieter.de. Auf dem eigenen Server kann das Programm DDClient installiert werden. Dieses kontaktiert regelmäßig eine Internetseite und erhält von dieser die eigene öffentliche IP-Adresse als Echo zurück. Dadurch erfährt DDClient, unter welcher IP-Adresse der Server erreichbar ist und schickt diese an den DDNS-Anbieter, bei welchem die eigene Domain beantragt wurde. Dieser Anbieter wiederum trägt die IP-Adresse in seinem DNS ein und macht dadurch die IP-Adresse zur Domain öffentlich bekannt.
DNS
DNS kann als Telefonbuch des Internets verstanden werden, in welchem IP-Adressen in Domainnamen übersetzt werden, z.B. wird die IP-Adresse 49.13.55.174. in wikipedia.de übersetzt. Mehr zum Thema DNS findet sich z.B. beim Elektronikkompendium.
Ruft ein Computer die Adresse server.ddns-anbieter.de auf, wird im DNS des DDNS-Anbieters die öffentliche IP-Adresse des Servers (in unserem Fall die Adresse des zentralen Proxy-Servers) ausgelesen und übermittelt. Dadurch wird die Anfrage an die richtige IP-Adresse geschickt.
Es gibt verschiedene Anbieter für DDNS-Dienste. Gut geeignet sind z.B. No-IP oder DDNSS.
DDNS wird eigentlich primär verwendet, um an privaten Internetanschlüssen, die häufig eine sich änderende IP-Adresse haben, immer über die gleiche Domain erreichbar zu sein. Im Fall des Kurses ist eine statische öffentliche IP-Adresse vorhanden und es wäre sauberer eine ordentliche Domain zu kaufen (oder im Rechenzentrum der Universität zu beantragen). Für die Testzwecke dieses Kurses genügt aber eine DDNS-Domain. Zeitgleich kann die damit erlernte Technik auch gut für Zwecke des Selfhostings im heimischen Wohnzimmer oder kleinen Büros ohne statische IP-Adresse angewendet werden.
Umsetzung DDNS unter Ubuntu
Für die Implementierung des DDNS-Verfahrens wird wie folgt vorgegangen:
Account bei einem DDNS-Anbieter registrieren
Im Falle von No-IP muss im Webportal des Anbieters nach der Registrierung noch ein Benutzername festgelegt werden
Beim gewählten Anbieter muss ein Domainname reserviert werden (A-Record für IPv4 oder AAAA-Record für IPv6)
-
ddclient auf dem Server installieren und konfigurieren:
sudo apt-get install ddclientIm Anschließenden Dialog wird im Falle von No-IP no-ip gewählt, ansonsten anderer
als Benutzername und Passwort werden die Zugangsdaten des DDNS-Anbieters eingetragen
als IP-Adressen-Ermittlungsmethode wird Web-basierter IP-Ermittlungsdienst gewählt
der zu aktualisierende Rechner ist der beim DDNS-Anbieter reservierte Domainnamen
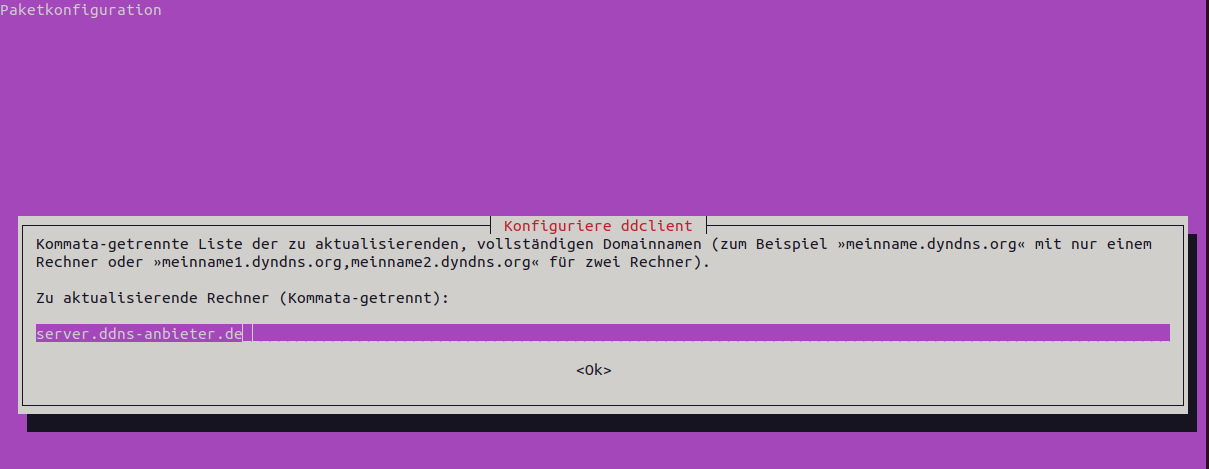
Nach der Installation sollte die Konfigurationsdatei
überprüft und ggf. angepasst werden:
sudo nano /etc/ddclient.conf. Je nach DDNS-Anbieter sieht
die Konfigurationsdatei unterschiedlich aus.
Wird die Konfigurationsdatei manuell geändert, muss ddclient neu
gestartet werden:
sudo systemctl restart ddclient.service
Webserver mit Docker
Damit auf dem eigenen Server auf Anfragen aus dem Internet auch reagiert wird, muss ein Webserver installiert werden. Dazu kann in einem Docker Compose Projekt der Apache-Webserver installiert werden. Um die Grundfunktionalität zu testen, wird vorerst keine besondere Konfiguration vorgenommen.
Docker Compose Projekt erstellen
Arbeitsverzeichnis anlegen: z.B.
sudo mkdir /opt/apache-docker/undsudo chown <username>:<username> /opt/apache-dockerIns Arbeitsverzeichnis wechseln (
cd- Befehl)Dort die Compose-Datei erstellen (
nano compose.yaml)
YAML
services:
apache:
image: httpd:latest
container_name: apache
ports:
- '80:80'
volumes:
- ./website:/usr/local/apache2/htdocsVolume-Verzeichnis für den Datenaustausch mit dem Container erstellen:
mkdir websiteWebsite-Beispiel erstellen:
nano website/index.html, z.B. wie folgt
HTML
<!DOCTYPE html>
<html>
<head>
<title>Apache-Test</title>
<style>
body {
font-family: Arial, sans-serif;
}
h1 {
color: blue;
}
p {
font-size: 18px;
}
</style>
</head>
<body>
<h1>Welcome to Apache-Test</h1>
<p>This is a simple paragraph to test the Apache server.</p>
</body>
</html>Docker Container starten:
sudo docker compose upoder im Hintergrundsudo docker compose up -dErreichbarkeit testen: öffnen Sie auf einem Endgerät im Webbrowser ihre registrierte DDNS-Domain. Wird Ihnen die Beispiel-HTML-Datei angezeigt?
Container stoppen:
STRG+coder im Hintergrundsudo docker compose down
TLS-Verschlüsselung
Kommunikationsweg:
Aktuell erfolgt die Kommunikation mit dem Server über das HTTP-Protokoll mit Port 80. Diese Verbindung ist unverschlüsselt. Das bedeutet, dass sämtliche Daten (z.B. Passwörter und Dateien) die zum Server geschickt oder vom Server verschickt werden, von einem “Zuhörer” auf der Leitung mitgelesen werden können (das geht z.B. mit dem Tool Wireshark v.a. im LAN recht einfach, siehe z.B. diese Anleitung von Varonis).
Grundlagen der HTTPS-Verbindung
Um das Auslesen der Verbindung und damit das Abfangen sämtlicher Kommunikation zu unterbinden, muss die Verbindung verschlüsselt werden. Um eine HTTP-Verbindung zu verschlüsseln wird diese durch das TLS-Protokoll zu einer HTTPS-Verbindung erweitert. HTTPS ist heute glücklicherweise der Standard bei den meisten Internetseiten. Dass Sie eine HTTPS-Verbindung zu einer Seite aufgebaut haben, erkennen Sie in der Adresszeile Ihres Browsers anhand eines Schlosssymbols, bei besonders starken Zertifikaten ggf. zusätzlich auch anhand einer grünen Markierung (siehe die folgende Abbildung).

Die Grundlage des TLS-Protokolls stellen Zertifikate dar, die die Authentizität der Website bestätigen.
Dazu ein nicht technisches Vergleichsbeispiel: Sie wollen bei einem Geschäftsvorgang die Identität des Gegenübers überprüfen. Zeigt Ihnen die Person einen selbst ausgestellten Ausweis, werden Sie diesem Personalausweis nicht vertrauen. Zeigt die Person jedoch einen Ausweis, der von einer staatlichen Behörde ausgestellt wurde, welcher Sie vertrauen, können Sie auch dem vorgelegten Ausweis vertrauen.
Übertragen auf die HTTPS-Verbindung sieht es wie folgt aus: Ein Website-Betreiber kann sich selbst ein TLS-Zertifikat ausstellen (unter Linux z.B. mit dem Programm OpenSSL) und dieses einem anfragendem Webbrowser oder sonstigem Client präsentieren. Allerdings kann einem solchen selbst ausgestellten Zertifikat nicht von Dritten vertraut werden. Der Browser wird die Verbindung als unsicher ablehnen und eine Warnmeldung zeigen. Damit ein Client dem Zertifikat vertrauen kann, muss dieses genau wie beim Personalausweis von einer zentralen Stelle ausgestellt werden. Diese zentralen Stellen (als Zertifizierungsstellen oder im Englischen als Certificate Authority bezeichnet) können auf Anfrage ein Zertifikat ausstellen, sofern die Identität der anfragenden Stelle gewährleistet ist.
Gleichzeitig besitzt die Zertifizierungsstelle selbst ein Zertifikat, dass deren Identität bestätigt. Dieses Zertifizierungsstellenzertifikat wiederum ist vom Hersteller Ihres Betriebssystems auf Ihrem PC hinterlegt und als vertrauenswürdig eingestuft worden. Überprüft Ihr Browser nun das Zertifikat der Website, stellt er zunächst fest, dass das präsentierte Zertifikat von einer Zertifizierungsstelle ausgestellt wurde, welcher er vertraut. Außerdem wird überprüft, ob die aufgerufene Adresse auch der im Zertifikat hinterlegten Adresse entspricht.
Rufen Sie eine Website auf, die ein falsches Zertifikat präsentiert (z.B. für die falsche Adresse, ein abgelaufenes oder selbst ausgestelltes Zertifikat), erhalten Sie eine Warnmeldung. Diese sollten Sie ernst nehmen, da es auf einen Betrugsversuch hindeuten kann, in welchem eine angreifende Person sich für die Website ausgibt, die Sie eigentlich aufrufen wollten (z.B. die Seite Ihres Online-Bankings).
TLS-Verschlüsselung einrichten
Um die eigene Website per HTTPS erreichen zu können, muss der Server ein Zertifikat von einer Zertifizierungsstelle erhalten, die von allen Computern anerkannt ist. Während dies früher nur gegen Bezahlung möglich war, existiert seit einigen Jahren mit Letsencrypt ein gemeinnütziger Anbieter, der kostenlose Zertifikate zur Verfügung stellt. Diese sind jedoch nur drei Monate gültig und müssen dann verlängert werden.
Um ein solches Zertifikat zu erhalten, muss man gegenüber Letsencrypt nachweisen, dass man die Eigentümer der Domain ist, für welche das Zertifikat angefragt wird. Das heißt: wenn Sie für die Adresse server.ddns-provider.de ein Zertifikat erhalten wollen, müssen Sie nachweisen, dass sie den Webserver, der die Seite server.ddns-provider.de ausliefert, verwalten. Diesen Nachweis erbringen Sie nicht manuell, sondern mit Hilfe verschiedener Programme (z.B. Certbot). Mit diesen Programmen werden automatisiert einige Informationen zwischen Ihrem Webserver und den Servern von Letsencrypt ausgetauscht, anhand deren die Eigentümerschaft nachgewiesen werden kann. Anschließend wird das Zertifikat von der Zertifizierungsstelle (Letsencrypt) ausgestellt und kann dann in den eigenen Webserver integriert werden.
Zertifikat erhalten:
In Docker kann das Hilfsprogramm für den Erhalt des Zertifikats in das Docker Compose Projekt integriert werden. Hierzu bestehen, wie eine Internetrecherche schnell aufzeigen wird, verschiedene Möglichkeiten.
Im Folgenden eine Möglichkeit, in welcher das Program certbot als zweiter Container dem Docker Compose Projekt hinzugefügt wird:
YAML
services:
apache:
image: httpd:latest
container_name: apache
ports:
- "80:80"
- "443:443"
volumes:
#Webinhalte für certbot challenge
- ./certbot/www:/usr/local/apache2/htdocs
#Beispiel-Internetseite
- ./website/index.html:/usr/local/apache2/htdocs/index.html
networks:
- webapp
certbot:
container_name: apache-certbot
image: certbot/certbot:latest
volumes:
- ./certbot/www:/var/www/certbot:rw
- ./certbot/conf:/etc/letsencrypt:rw
- ./certbot/log:/var/log/letsencrypt:rw
networks:
- webapp
networks:
webapp:
name: webapp
external: trueChallenge
Schauen Sie sich die compose.yaml-Datei genau an. Was bewirken die einzelnen Parameter?
Im Unterschied zum ersten einfachen Beispiel, ist in diesem Projekt der certbot-Container als zweiter Dienst hinzugekommen. Außerdem hat der Apache-Container zusätzliche Volumes erhalten. Certbot und Apache teilen sich dabei einige der Volumes, da beide Container auf die Dateien zugreifen müssen.
Um nun das Zertifikat zu erhalten, muss im Certbot-Container ein
Befehl abgesetzt werden. Dazu wird der
docker compose run-Befehl genutzt:
sudo docker compose run --rm certbot certonly --webroot --webroot-path /var/www/certbot -d <server.ddns-provider.de> --dry-run
(eigenen Domainnamen nutzen). Hierbei wird die Zertifikatsausstellung
simuliert. Verläuft der Prozess erfolgreich (Rückmeldung
The dry run was successful.), wird der Parameter
--dry-run weggelassen, um die Ausstellung auszuführen.
Wurde das Zertifikat erhalten, kann es später mit folgendem Befehle
erneuert werden: docker compose run --rm certbot renew
Webserver von HTTP auf HTTPS umstellen
Um das Zertifikat für die Sicherung des eigenen Webservers zu nutzen, müssen einige Konfigurationsschritte vorgenommen werden.
Apache-Konfigurationsdateien aus dem Container zum Host kopieren (bei laufendem Container):
sudo docker cp apache:/usr/local/apache2/conf apache-conf/Wurde das Zertifikat erhalten muss ggf. in der Firewall Port 80 geschlossen und Port 443 geöffnet werden. Im Falle von Docker-Container, wird die UFW-Firewall standardmäßig umgangen, weshalb die Ports nicht explizit geöffnet werden müssen.
Konfigurationsdatei für die Test-Webseite erstellen:
sudo nano apache-conf/webseite.conf
<VirtualHost *:80>
DocumentRoot /usr/local/apache2/htdocs
ServerName <ddns-domain>
RewriteEngine on
RewriteCond %{SERVER_NAME} =<ddns-domain>
RewriteRule ^ https://%{SERVER_NAME}%{REQUEST_URI} [END,NE,R=permanent]
</VirtualHost>
#SSL-Einstellungen (siehe auch apache-conf/extra/httpd-ssl.conf)
Listen 443
SSLSessionCache "shmcb:/usr/local/apache2/logs/ssl_scache(512000)"
SSLSessionCacheTimeout 300
SSLCipherSuite HIGH:MEDIUM:!MD5:!RC4:!3DES
SSLProxyCipherSuite HIGH:MEDIUM:!MD5:!RC4:!3DES
SSLHonorCipherOrder on
SSLProtocol all -SSLv3
SSLProxyProtocol all -SSLv3
SSLPassPhraseDialog builtin
<VirtualHost *:443>
SSLEngine on
DocumentRoot /usr/local/apache2/htdocs
ServerName <ddns-domain>
SSLCertificateFile /usr/local/apache2/server.crt
SSLCertificateKeyFile /usr/local/apache2/server.key
</VirtualHost>
- Angepasste Apache-Konfiguration über die compose.yaml Datei einbinden:
YAML
services:
apache:
#... wie gehabt
volumes:
#Webinhalte für certbot challenge
- ./certbot/www:/usr/local/apache2/htdocs:ro
#Zertifikat und Key
- ./certbot/conf/live/<ddns-domain>/cert.pem:/usr/local/apache2/server.crt:ro
- ./certbot/conf/live/<ddns-domain>/privkey.pem:/usr/local/apache2/server.key:ro
#Beispiel-Internetseite
- ./website/indey.html:/usr/local/apache2/htdocs/index.html
#Konfiguration
- ./apache-conf/:/usr/local/apache2/conf
#...wie gehabt- Apache-Konfiguration anpassen:
sudo nano apache-conf/httpd.conf
#...
#SSL-Modul aktivieren
LoadModule ssl_module modules/mod_ssl.so
#...
#Rewrite-Modul aktivieren
LoadModule rewrite_module modules/mod_rewrite.so
#...
#Socache aktivieren
LoadModule socache_shmcb_module modules/mod_socache_shmcb.so
#...
#Neue Zeile ergänzen
Include conf/webseite.confDas gesamte Compose-Projekt stoppen und wieder starten:
sudo docker compose down && sudo docker compose up -dÜberprüfen mit
sudo docker compose logsund im Webbrowser am Endgerät durch Eingabe der eigenen Domain.Ggf. stoppen mit
sudo docker compose down
Webserver sind die Kommunikationszentrale zwischen Client und Webapplikation
Um den Webserver per Domain zu erreichen, kann bei einem DDNS-Dienst eine dynamische Domain beantragt werden
Zur Absicherung der Kommunikation zwischen Server und Client muss ein TLS-Zertifikat beantragt und eingerichtet werden
Mit Docker Compose kann der Apache-Webserver zusammen mit Certbot für das HTTPS-Protokoll eingerichtet werden
Content from Proxysrever mit docker compose
Zuletzt aktualisiert am 2026-05-12 | Diese Seite bearbeiten
Übersicht
Fragen
Gibt es auch eine vereinfachte Möglichkeit für TLS-Zertifikate
Wie installiere ich NGINX-Proxy-Manager
Wie erstelle ich einen Proxy Host zur Weiterleitung an einen Upstream-Server
Ziele
NGINX Proxy Manager installieren und konfigurieren
TLS-Zertifikate mit dem NGINX-Proxy Manager erhalten
Upstream-Server im Docker Netzwerk erreichen
Reverse Proxy: Logistikhub für Webapplikationen
Ein Reverse Proxy ist ein (Web)Server, der Anfragen von Clients entgegennimmt und sie an einen oder mehrere Backend-Server weiterleitet. Der Client weiß dabei nicht, dass die eigentliche Antwort von einem anderen Server kommt – er kommuniziert nur mit dem Reverse Proxy.
Wozu wird ein Reverse Proxy eingesetzt?
- Lastverteilung: Verteilt Anfragen auf mehrere Server,
um Überlastung zu vermeiden.
- Sicherheit: Versteckt die eigentlichen Server hinter
dem Proxy und kann Angriffe abwehren (z. B. DDoS-Schutz).
- Verschlüsselung (SSL/TLS): Kann die
HTTPS-Verschlüsselung zentral übernehmen (z. B. mit Let’s
Encrypt).
- Caching: Speichert häufig abgerufene Inhalte, um die
Ladezeiten zu verbessern.
- URL-Routing: Leitet Anfragen basierend auf der URL an
unterschiedliche Anwendungen weiter (z. B. /api →
Backend-Service, / → Webseite).
Beispiele für Einsatzszenarien:
- Ein Unternehmen verwendet einen Reverse Proxy (z. B.
Nginx oder Apache HTTP Server) zur
zentralen Verwaltung mehrerer Webanwendungen auf einem Server.
- Eine große Website nutzt einen Reverse Proxy, um Traffic über mehrere
Server zu verteilen und die Verfügbarkeit zu erhöhen.
- Eine Firma setzt einen Reverse Proxy ein, um HTTPS für alle Dienste zu
aktivieren, ohne dass die einzelnen Anwendungen selbst SSL konfigurieren
müssen.
In der vorherigen Sitzung wurde ein Apache-Webserver betrieben, der alle Anfragen direkt verarbeitet hat und die HTML-Datei an die Client geliefert hat. Möchte man jedoch mehrere Webapplikationen parallel betreiben, empfiehlt sich die Nutzung eines Reverse Proxies. Der Apache-Webserver kann dafür konfiguriert werden. Im Docker Compose Projekt der vorherigen Sitzung müsste dafür die Konfigurationsdatei angepasst werden.
NGINX-Proxy-Manager
Für den NGINX-Webserver existiert mit dem NGINX-Proxy-Manager jedoch ein Softwareprojekt, dass eine graphische Oberfläche für den NGINX-Webserver bereitstellt. Der NGINX-Proxy-Manager verfügt über die meisten Funktionen, die für das Betreiben eines Reverse Proxy notwendig sind. Allerdings bietet er nicht die volle Funktionalität, die NGINX hat, wenn dieser händisch (ohne graphische Oberfläche) konfiguriert und betrieben wird.
Installation
Der NGINX-Proxy-Manager wird ebenfalls als Docker Compose Projekt erstellt. Dazu gehen Sie zunächst wie in der vorhergehenden Sitzung geschildert vor (Verzeichnis erstellen, Berechtigungen anpassen, compose.yaml-Datei erstellen).
Nun lesen Sie das Handbuch durch.
Übernehmen Sie die Vorlagen-Dateien und passen Sie die folgenden Punkte an:
Netzwerk: Datenbank und Webapp bekommen ihr eigenes Netzwerk: proxy-db und proxy-web. Der Webapp-Container ist mit beiden Netzwerken verbunden
Umgebunsvariablen: ersetzen Sie die Standardpasswörter und Usernamen
Starten Sie das Projekt: `sudo docker compose up -d
Öffnen Sie im Webbrowser den NGINX-Proxy-Manager mit der URL:
http://server.ddns-provider.de:81
Challenge
Was bedeutet die angehängte Nummer in der URL
http://server.ddns-provider.de:81 und warum ist sie
wichtig?
Die Nummer in einer URL gibt den spezifischen Port an, über den der Client (z.B. ein Webbrowser) mit dem Webserver kommunizieren soll. Standardmäßig verwenden Webserver Port 80 für HTTP und Port 443 für HTTPS. Wenn eine andere Portnummer angegeben wird – wie in diesem Fall Port 81 – bedeutet das, dass der Server auf diesem Port angefragt wird.
Die Portnummer ist wichtig, weil ein Server auf einem Gerät (z.B. einem Rechner) gleichzeitig mehrere Dienste betreiben kann, die jeweils auf einer anderen Portnummer laufen. In unserem Fall wollen wir die Weboberfläche des NGINX-Proxy-Managers erreichen, welche auf Port 81 läuft (vergleiche dazu auch die compose.yaml-Datei). Port 80 wird benötigt werden, um Zertifikate von Letsencrypt zu beantragen.
Nutzung
Die Nutzung des NGINX-Proxy-Managers ist (zumindest in den Grundlagen) recht einfach. Um Anfragen an eine Webapplikation weiterzuleiten, wird ein Proxy-Host erstellt. Um diesen mit einem TLS-Zertifikat abzusichern wird ein solches bei der Erstellung gleich mit beantragt. Damit der NGINX-Proxy-Manager weiß, wohin die Daten weiter geleitet werden sollen, muss das Ziel angegeben werden.
Als ersten Proxy-Host erstellen Sie einen Eintrag für NGINX-Proxy-Manager selbst, um den Zugriff darauf ebenfalls per HTTPS zu sichern. Folgende Screenshots zeigen die Konfiguration.
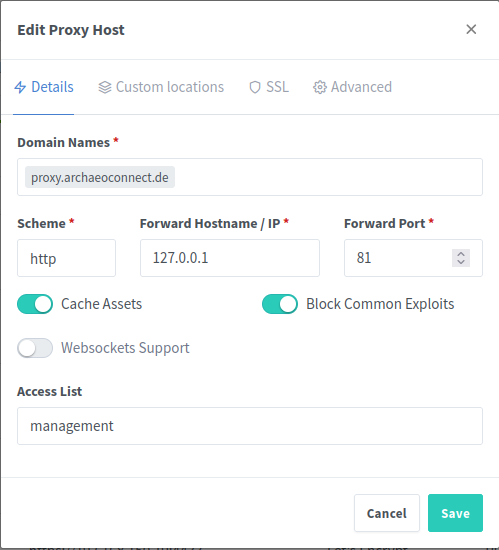
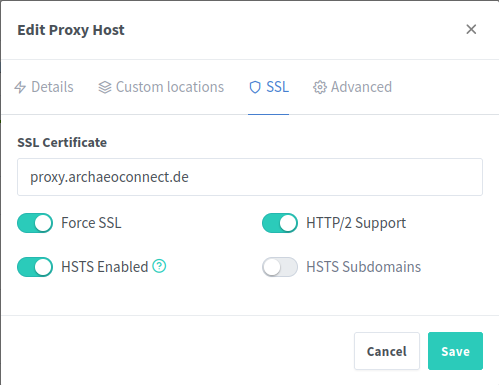
Weitere Upstream Server konfigurieren
Proxy-Hostkonfiguration
Was bewirken die vorgenommenen Einstellungen für den ersten Proxy-Host?
Die IP-Adresse 127.0.0.1 bedeutet, dass sämtliche Anfragen an die konfigurierte Domain an die lokale Netzwerkkarte (also ohne den Server zu verlassen) mit Port 81 weitergeleitet werden. D.h. Sie können die Weboberfläche jetzt über das HTTPS ansteuern: https://server.ddns-provider.de
Die weiteren Parameter im SSL-Tab bewirken, dass eine unverschlüsselte Kommunikation über das HTTP-Protokoll unterbunden wird.
Sobald NGINX-Proxy Manager per HTTPS erreichbar ist, müssen Sie Ihr Passwort ändern, da Sie dieses zuvor unverschlüsselt per HTTP übertragen haben.
Für jeden weiteren Proxy-Host benötigen Sie eine eigene Domain. D.h. Sie müssen entweder bei Ihrem DDNS-Anbieter eine weitere Domain registrieren oder, sollten Sie eine eigene Domain besitzen, für diese zusätzliche Subdomains erstellen.
Anschließend können Sie für diese Domains weitere Proxy-Hosts erstellen und TLS-Zertifikate beantragen. Voraussetzung ist dabei natürlich, dass 1. die Domain auf die richtige IP-Adresse verweist (die öffentliche IP-Adresse, unter welcher Ihr Server erreichbar ist) und 2. dass Ihre Firewall die Kommunikation über Port 80 für die Zertifikatsausstellung und Port 443 für die HTTPS-Verbindung erlaubt.
Apache als Upstream-Server
Erstellen Sie einen weiteren Proxy Host. Registrieren Sie dafür eine weitere (Sub-)Domain und beantragen Sie ein TLS-Zertifikat.
Als Ziel dient der Apache-Webserver, welcher in der vorherigen Sitzung konfiguriert wurde. Die Weiterleitung kann dabei über das HTTP-Protokoll erfolgen, da die Kommunikation zwischen Proxy und Apache-Webserver auf demselben Gerät erfolgt. Unter welcher Adresse (IP oder URL) erreicht NGINX den Apache-Container?
Wie müssen Sie dafür die Apache-Konfigurationsdatei und die compose.yaml-Datei des Apache-Projekts anpassen?
Da die Kommunikation für die Beispiel-Internetseite jetzt wieder per HTTP erfolgt, kann die Apache-Konfigurationsdatei wieder vereinfacht werden:
<VirtualHost *:80>
DocumentRoot /usr/local/apache2/htdocs
ServerName server.ddns-provider.de
</VirtualHost>Aus der compose.yaml-Datei kann der certbot-Container und dessen Volumes entfernt werden. Um die Kommunikation mit dem Proxy zu ermöglichen, muss das Netzwerk angepasst werden.
YAML
services:
apache:
image: httpd:latest
container_name: apache
ports:
- '80:80'
volumes:
#Beispiel-Internetseite
- ./website:/usr/local/apache2/htdocs
networks:
- proxy-web
networks:
proxy:
name: proxy-web
external: trueWenn beide Container (Apache und NGINX) im Selben Netzwerk eingebunden sind, kann die Weiterleitung über den Container-Namen erfolgen.
Mit dem NGINX-Proxy Manager besteht eine vereinfachte Möglichkeit für den Erhalt von TLS-Zertifikaten
Mit einem Reverse Proxy können mehrere Webapplikationen parallel betrieben werden
Mit korrekter Docker Netzwerkkonfiguration ist die Kommunikation zwischen Containern schnell hergestellt
Content from Nextcloud mit Docker installieren
Zuletzt aktualisiert am 2026-05-12 | Diese Seite bearbeiten
Übersicht
Fragen
Gibt es Alternativen zu den Cloud-Plattformen der Tech-Giganten aus Übersee?
Welche Funktionen und Vorteile bietet Nextcloud?
Wie installiere ich den Nextcloud-Server auf meinem Server?
Ziele
NGINX Proxy Manager für Nextcloud konfigurieren
Nextcloud All-in-One Dockerimage installieren
Nextcloud: Freie Online-Kollaboration und Datensynchronisation
Nextcloud ist eine Open-Source-Software-Suite, die es Nutzern ermöglicht, Dateien, Kalender, Kontakte und weitere Daten auf einem Server zu speichern und zu synchronisieren. Es handelt sich um eine Alternative zu proprietären Cloud-Diensten wie Dropbox oder Google Drive.
Hauptmerkmale - Dateisynchronisation: Sichere Speicherung und Synchronisation von Dateien auf mehreren Geräten (Desktop, Mobil, Web). - Dateibearbeitung: (Gemeinsame) Bearbeitung von Dokumenten (Nextcloud Office) - Datensicherheit: Ende-zu-Ende-Verschlüsselung und Self-Hosting/on Premise möglich sowie viele weitere Sicherheitsfunktionen - Multimedia: Anzeigen, Organisieren und Teilen von Bildern, Musik und Videos. - Kommunikation: Chat und Videotelefonie mit Nextcloud Talk - Groupware: Kalender, Kontakte, Notizen und Aufgaben-Management.
Nextcloud ist unter freien Lizenzen (AGPL- und GPL) veröffentlicht. Dies bedeutet, dass die Software frei genutzt und modifiziert werden kann, solange die Quellcodes frei zugänglich bleiben. Für größere Organisationen gibt eine Enterprise-Version, die erweiterte Funktionen (v.a. Integration von Dritt-Diensten) und Support bietet.
Hinter dem Projekt Nextcloud steht die Nextcloud GmbH, die die Entwicklung steuert und durchführt aber auch Enterprise-Support anbietet. Die Community spielt aber ebenso eine wichtige Rolle bei der Weiterentwicklung von Nextcloud. Aufgrund des freien Lizenzmodells steht es jedem und jeder offen, sich an der Weiterentwicklung zu beteiligen oder eigene Apps zur Funktionserweiterung zu entwickeln.
Benutzer können Nextcloud auf einem eigenen Server installieren und selbst verwalten. Dies bietet maximale Kontrolle über die Daten und erlaubt die Nutzung von Nextcloud ohne Abhängigkeit von einem externen Dienstleister. Alternativ kann bei einem frei zu wählenden Hosting-Provider ein Nextcloud-Server und dessen Verwaltung gemietet werden. Dann liegen die eigenen Daten aber auch auf den Servern dieses Dienstleisters. Im Unterschied zu proprätären Diensten, kann ich mir aber einen Dienstleister meines Vertrauens heraussuchen, ähnlich wie bei der Wahl eines Mail-Providers.
Nextcloud Server: Installationsvarianten
Nextcloud kann auf verschiedenen Plattformen und in unterschiedlichen Installationsvarianten betrieben werden. Die Wahl der Methode hängt von den spezifischen Anforderungen, der verfügbaren Infrastruktur und den Präferenzen der nutzenden Person ab. Hier ist ein Überblick über die häufigsten Installationsvarianten:
Bare-Metal: Hierbei wird Nextcloud direkt auf einem physischen Server installiert. Dies bietet maximale Kontrolle und Performance, erfordert jedoch mehr technisches Know-how und ist weniger flexibel als virtuelle Umgebungen. Unterstützt werden Linux und Windows-Betriebssysteme, wobei i.d.R. Linux genutzt wird
Docker: Docker bietet zwei Möglichkeiten für die Nextcloud-Installation: Das “all-in-one”-Image und die manuelle Installation. Das “all-in-one”-Image ist die als offizielel Installationsvariante empfohlene Option der Nextcloud GmbH. Es ist ein einfach zu installierendes Docker-Image, das gleich mehrere weitere Container für zusätzliche Funktionalität und Optmierung mit bringt. Es erfordert jedoch durch die zusätzlichen Container mehr Ressourcen als die manuelle Installation mit Docker Compose. Bei der manuellen Installation müssen jedoch die einzelnen Komponenten (Nextcloud-Server, Datenbank, Webserver, Caching-Server u.a.) separat konfiguriert werden. Dafür besteht beim manuell erstellten Docker Compose Projekt mehr Flexibilität.
Virtuelle Maschinen (VM): Nextcloud kann auf einer virtuellen Maschine betrieben werden, was die Isolierung von Ressourcen und die Verwaltung mehrerer Instanzen erleichtert.
Nextcloud Pi: Nextcloud Pi ist eine spezielle Version von Nextcloud, die für den Einsatz auf Raspberry Pi-Geräten optimiert ist. Sie bietet eine einfache Installation und Verwaltung und ist ideal für kleine Netzwerke oder Heimserver.
In dieser Lektion wird gezeigt, wie das Nextloud All-in-One-Dockerimage installiert werden kann.
Nextcloud All-in-One
Vor der Installation sollten Sie sich die Informationen im Github-Repository durchlesen. Allgemein zur Installation, Konfiguration und Nutzung von Nextcloud ist das [Handbuch][nextlcoud-doc] die erste Anlaufstelle.
Wie bei jedem Docker Compose Projekt wird wieder ein Arbeitsverzeichnis vorbereitet.
Anschließend muss der NGINX-Proxy-Manager eingerichtet werden (Proxy Host mit TLS-Zertifikat). Genaue Konfigurationshinweise finden sich auch im Github-Repository.
Für die compose.yaml-Datei existiert eine Vorlage. Diese muss jedoch noch stark angepasst werden. In diesem Thread auf Github gibt es einige aus der Community berichtete Beispiele (Tip: die Seite nach “NGINX Proxy Manager” durchsuchen).
Hat man eine compose.yaml-Datei erstellt müssen, müssen ggf. lokale
Ordner und Dateien für die Docker Volumes erstellt werden. Anschließen
kann das Projekt mit sudo docker compose up gestartet
werden. Hier empfiehlt sich tatsächlich das Starten im Vordergrund, da
bei diesem großen Projekt vermutlich zunächst noch Fehler aufkommen, die
so direkt gesehen werden.
Nextcloud All-in-One
Installieren Sie einen Nextlcoud-Server mit Hilfe des Nextcloud All-in-One Images. Nutzen Sie dabei den NGINX Proxy Manager als Reverse Proxy.
Ergänzend zu den oben verlinkten Materialien ist folgendes zu beachten:
Es werden drei Domains benötigt: 1. für NGINX-Proxy-Manager, zweiters für den Nextcloud Mastercontainer, 3. für Nextcloud selbst.
eine Domain muss weiterleiten an https://nextcloud-aio-mastercontainer:8080
eine Domain muss während der Installation weiterleiten an http://nextcloud-aio-domaincheck:11000 und anschließend an http://nextcloud-aio-apache:11000
NGINX-Proxy-Manager muss in das Docker-Netzwerk nextcloud-aio integriert werden
Bei der Installation sollten alle optionalen Container abgewählt werden (der Speicherplatz auf den virtuellen Computern ist limitiert)

- Die Compose-Datei kann wie folgt angepasst und ggf. noch entsprechend den eigenen Bedürfnisse geändert werden:
YAML
services:
nextcloud-aio-mastercontainer:
image: ghcr.io/nextcloud-releases/all-in-one:latest
init: true
restart: always
container_name: nextcloud-aio-mastercontainer
volumes:
- nextcloud_aio_mastercontainer:/mnt/docker-aio-config
- /var/run/docker.sock:/var/run/docker.sock:ro
networks: ["nextcloud-aio"]
ports:
- 8080:8080
environment:
APACHE_PORT: 11000
APACHE_IP_BINDING: 127.0.0.1
volumes:
nextcloud_aio_mastercontainer:
name: nextcloud_aio_mastercontainer
networks:
nextcloud-aio:
name: nextcloud-aio
external: true- die bei der Installation angezeigten Passwörter für den mastercontainer und den admin-Account unbedingt notieren!
Die Nextcloud-Software-Suite ist eine Open Source Alternative für Datensychronistaion und Kollaboration im Team
Nextcloud auf dem eigenen Server installiert werden
Eine Installationsvariante für einen schnellen Start ist das All-in-One Dockerimage
Content from Nextcloud AIO: Konfiguration
Zuletzt aktualisiert am 2026-05-12 | Diese Seite bearbeiten
Übersicht
Fragen
Wie kann die Funktion von Nextcloud AIO erweitert werden?
Wie kann ich die Leistung und Sicherheit von Nextcloud AIO verbessern?
Wie war das noch einmal mit dem Backup?
Ziele
Funktionen im Docker Compose Projekt ergänzen
Verwaltungsoberfläche von AIO
Datensicherung von Nextcloud AIO
Anpassung von Nextcloud All-in-One (AIO)
Nach der Installation sind weitere Anpassungen zu empfehlen. Dazu zählen z.B. Optmierungen der Performance oder der Sicherheit. Aber auch die Konfiguration eines Backupplans. Die Anpassungen sind an mehreren Stellen möglich, die im Folgenden gezeigt werden.
In der compose.yaml-Datei
Bereits für die Konfiguration des Reverse Proxy wurden an der Compose-Datei des sogenannten “Mastercontainers” (der Container, der alle anderen Container verwaltet) Änderungen vorgenommen. Die Hinweise in der offiziellen Vorlage der compose.yaml-Datei geben schon einen guten Hinweis, was hier noch optimiert werden kann und wie dies geschehen kann.
Perfomance
Die Anpassungen erfolgen i.d.R. durch Anpassung einer der Umgebungsvariablen. Einen Blick Wert sind dabei z.B. NEXTCLOUD_MEMORY_LIMIT, NEXTCLOUD_MAX_TIME und NEXTCLOUD_UPLOAD_LIMIT. Verfügt der Docker Host über eine Grafikkarte, besteht die Möglichkeit deren Rechenleistung für AIO zur Verfügung zu stellen. Dies ist v.a. für Funktionen wie die Gesichtserkennung oder KI-Anwendungen innerhalb von Nextcloud relevant. Für die Konfiguration der Grafikkarte sind die Umgebungsvariablen NEXTCLOUD_ENABLE_DRI_DEVICE oder NEXTCLOUD_ENABLE_NVIDIA_GPU relevant
Fail2Ban
Um Brute-Force-Angriffe auf seinen Nextcloud-Server zu unterbinden, sollte Fail2Ban auch für Nextcloud eingerichtet werden. Auf Github und im Handbuch finden sich dafür die nötigen Informationen. In Kurzform: fügen Sie der Fail2Ban-Konfiguration des Hosts ein neues Jail hinzu. Passen Sie den Pfad der Log-Datei an und nutzen Sie die Docker-User Chain (da der Datenverkehr an der UFW-Firewall vorbei geht. Folgend ein mögliches Beispiel der Fail2Ban-Konfiguration (vergessen Sie jedoch nicht, wie im Handbuch geschildert, die Filter-Datei zu erstellen):
Über die Verwaltungsoberfläche von AIO
Nach der Installation von Nextcloud AIO kann die
Verwaltungsoberfläche des Docker Mastercontainers im Webbrowser erreicht
werden. Entweder unter
https://<öffentliche-Ip-Adresse>:8080 oder unter
https://<ihre-domain>:8443. Da sich in unserem Fall
hinter der gleichen IP-Adresse mehrere Server verstecken, wird der
Zugriff über die IP-Adresse nicht erfolgreich sein. Beim Zugriff über
den Domainname, kann der Hauptproxy-Server die Anfrage aber korrekt
weiterleiten (an den NGINX-Proxy-Manager, welcher dann wiederum an den
AIO-Container weiterleitet).
Über die Administrationsoberfläche von Nextcloud
Wie bei einer “normalen” Nextcloud-Installation (z.B. Bare-Metal) kann der Server auch über die Administrationsseite des Nextcloud-Servers verwaltet werden. Wobei manche Einstelllungen hier nicht möglich sind. Melden Sie sich dazu auf Ihrem Nextcloud-Server mit einem Administrator-Account an. Öffnen Sie über den Button rechts oben das Menü und wählen Sie “Verwaltungseinstellungen” aus. Wählen Sie nun links den Punkt “Grundeinstellungen” aus. Dort werden Ihnen Fehler und Warnungen angezeigt, die insbesondere direkt nach der Installation noch auftreten können. Beheben Sie all diese Fehler und möglichst auch alle Warnungen.
Mit dem occ-Tool
Das occ-Tool
ist ein php-Programm, das mit Nextcloud installiert wird (egal ob als
Docker-Container oder Bare-Metal). Mit dem occ-Tool kann der Server in
vielerlei Hinsicht verwaltet und angepasst werden. Sämtliche
Befehlsoptionen können dem Handbuch entnommen werden. Im Falle von
Nextcloud AIO ist zu beachten, dass das Tool im Docker-Container läuft
und in diesem mit den Rechten des www-data-Users ausgeführt werden muss.
Entsprechend den Informationen im AIO-GitHub-Repository
lautet der Befehl wie folgt:
sudo docker exec --user www-data -it nextcloud-aio-nextcloud php occ <Befehlsoption>,
z.B.
sudo docker exec --user www-data -it nextcloud-aio-nextcloud php occ maintenance:mode --on
um den Wartungsmodus von Nextcloud zu aktivieren.
Backup
Grundlagen
Um Datenverlust zu vermeiden, sollte stets ein Backup erstellt werden. Sowohl im Falle des Nextcloud-Servers, des physischen Server aber auch jedes Endgeräts (PC, Notebook, Telefon).
Was muss gesichert werden?
Welche Inhalte eines Systems gesichert werden sollen, ist von den eigenen Bedürfnissen abhängig. Es kann jedoch zwischen drei Hauptkategorien an Daten unterschieden werden:
Dateien (Bilder,Dokumente, Videos, Emails…)
Programme und Lizenzen (Installationsdateien, Konfigurationen, ganze Installationen)
System (Betriebssystem mit (allen?) Konfigurationen)
In vielen Fällen wird die Sicherung der Dateien ausreichen, da Programme und System mit etwas Zeitaufwand wieder neu aufgesetzt werden können. In zeitkritischen Umgebungen, wenn ein defektes System schnell wieder verfügbar sein muss, empfiehlt es sich aber, dass gesamte System zu sichern.
Wie muss gesichert werden?
Es kann zwischen drei Varianten einer Sicherung unterschieden werden:
Vollsicherung
Differentielle Sicherung
Inkrementelle Sicherung
Bei der Vollsicherung werden zu jeder Sicherungszeit (z.B. täglich oder wöchentlich) alle Daten gesichert. Der Vorteil dieser Variante ist, dass für eine Wiederherstellung der Daten nur die letzte Sicherungsversion benötigt wird. Der Nachteil liegt im großen Speicher- und Zeitbedarf, da bei jeder Sicherung alle Daten kopiert werden müssen, also sowohl die ursprünglichen Daten, als auch die Daten, die seit der letzten Sicherung neu hinzugekommen sind.
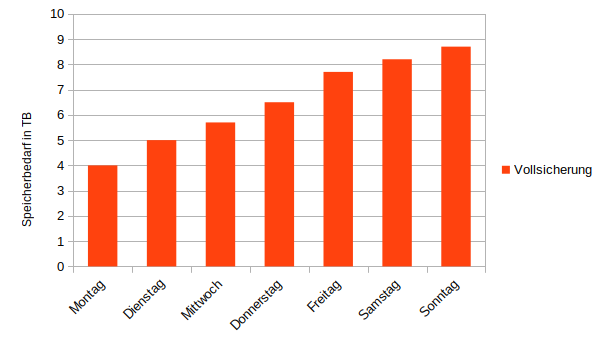
Bei der differentiellen Sicherung wird zur ersten Sicherungszeit eine Vollsicherung durchgeführt. Anschließend wird jeden Tag eine Sicherung erstellt, welche alle seit der letzten Vollsicherung geänderten oder neu erstellten Daten enthält. Der Vorteil dieser Variante besteht darin, dass bei einer Wiederherstellung nur die letzte Vollsicherung und die letzte differentielle Sicherung benötigt werden. Der Nachteil liegt wie bei der Vollsicherung darin, dass nach wie vor ein großer Speicherplatzbedarf besteht und die Daten dupliziert vorliegen.
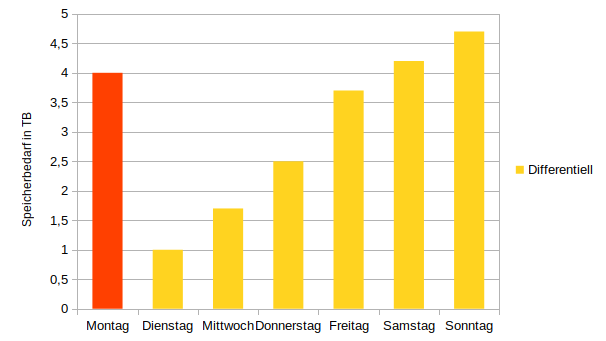
Bei der inkrementellen Sicherung werden jeden Tag nur diejenigen Daten gesichert, die an diesem Tag geändert bzw. neu hinzugekommen sind. Der Vorteil der inkrementellen Variante besteht darin, dass vergleichsweise wenig Zeit und Speicherplatz benötigt wird, da nur zu Beginn eine Vollsicherung erstellt wird und zu jeder weiteren Sicherungszeit nur die Änderungen gesichert werden. Der Nachteil besteht darin, dass im Falle einer Wiederherstellung die letzte Vollsicherung und alle inkrementellen Zwischensicherungen benötigt werden.
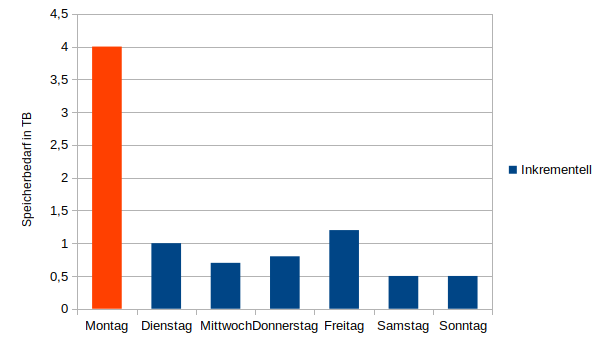
Neben der Art der Sicherung, muss auch überlegt werden, wie die einzelnen Sicherungsversionen aufgehoben werden. Im obigen Beispiel zu einer täglichen inkrementellen Sicherung und einer wöchentlichen Vollsicherung können z.B. die Vollsicherung und die inkrementellen Zwischensicherungen nur solange aufgehoben werden, bis eine neue Vollsicherung erstellt wurde. Möchte man jedoch gewährleisten, auch auf einen Datenstand von vor 6 Monaten zurück gehen zu können, sollten die Sicherungen länger aufgehoben werden. Z.B. könnte dann eine monatliche Vollsicherung in jeweils sechs Versionen aufbewahrt werden. Wird eine siebte Version erstellt, wird die älteste gelöscht.
Ein bekanntes Schema zur Versionierung von Sicherungen ist das Generationenprinzip (auch als Großvater-Vater-Sohn-Prinzip bezeichnet). Bei diesem Prinzip werden täglich Backups erstellt. Diese werden eine Woche lang aufbewahrt. Anschließend werden die täglichen Versionen zu einem Wochenbackup zusammengefasst. Die wöchentlichen Backups werden für einen Monat aufbewahrt und nach einem Monat zu einer Monatssicherung zusammen gefasst. Diese monatlichen Sicherungen werden für 12 Monate aufbewahrt. Dadurch bestehen für die letzten sieben Tage jeweils tägliche Versionen, für den letzten Monat wöchentliche Versionen und für das letzte Jahr noch monatliche Versionen. Graphisch ist dieses Verfahren hier dargestellt.
{kind=link}
Wo muss gesichert werden?
Ist geklärt, was und wie gesichert werden soll, muss noch geklärt werden, wo gespeichert werden soll. Grundlegend sollten Sicherungen nicht auf demselben physischen Datenträger wie die Originaldaten gespeichert werden. Die 3-2-1-Regel gilt als ein guter Richtwert: 3 Kopien auf 2 unterschiedlichen Medien, 1 Offsite-Kopie. Speichert man auf unterschiedlichen Medien, hat man mehr Felxibilität bei der Wiederherstellung. Die Offsite-Kopie an einem anderen Ort wird wichtig, wenn am ursprünglichen Serverstandort ein größerer Schaden Eintritt (z.B. Feuer, Wasser, Kurzschluss oder Einbruch).
Mehr zum Thema Datensicherung findet sich z.B. auch bei Ubuntuusers oder bei Netzwelt.
Der eigene Backupplan
Die zuvor dargestellten Methoden und Standards sind nicht immer einfach umzusetzen. Das ist mit ein Grund dafür, dass in vielen Fällen keine Sicherungen gemacht werden, da der Aufwand für die Implementierung einer Sicherungsstrategie zu groß erscheint. Deshalb ist es insbesondere für Heimanwender und kleinere Organisationen mit wenig zeitkritischen Daten oftmals besser ein mittelmäßiges Backup zu haben als gar keines und dafür nicht alle der zuvor genannten Regeln zu befolgen.
Backup für den Nextcloud-Server
Überlegen Sie sich, wie Sie Ihren Nextcloud-Server sichern können. Was (welche Daten) sollten Sie sichern? Wie sichern Sie (mit welcher Variante)? Suchen Sie im Internet nach Programmen oder Workflows, um eine Nextcloud-Instanz (Bare-Metal, Docker und VM) zu sichern. Wo speichern Sie die Sicherungen?
Das Handbuch
listet die grundlegenden Schritte auf, um den Nextcloud-Server zu
sichern: 1. das Konfigurationsverzeichnis unter
/var/www/nextcloud/config, 2. das Datenverzeichnis, z.B.
unter /mnt/data/ncdata, 3. der Theme-Folder unter
/var/www/nextcloud/themes (nur wichtig wenn eigene Themes
genutzt werden) und 4. die Nextcloud-Datenbank des MariaDB-Servers.
Sinnvollerweise wird man eine inkrementelle Sicherung wählen, um Zeit und Speicherplatz zu sparen. Während das Handbuch zwar die einzelnen manuellen Schritte aufzeigt (Maintanance-Modus aktivieren, Ordner mit rsync sichern, Datenbank mit mysqldump sichern) gibt es viele Tools mit denen Nextcloud gesichert werden kann. Z.B. Borg-Backup, Duplicati oder die Nextcloud-integrierte Backup-App. Eine weitere Möglichkeit besteht im schreiben eines eigenen Skripts (eines Mini-Programms), welches leicht an die eigenen Bedürfnisse angepasst werden kann.
Die Sicherungen können zunächst auf einer zweiten Festplatte, die im Server eingebunden werden kann, gespeichert werden. Mehr Unabhängigkeit vom Hauptsystem erhält man, wenn man die Sicherung über das Netzwerk auf einem zweiten Gerät speichert. Das kann z.B. per Netzlaufwerk im Heimnetz geschehen oder per SSH auf entfernte Rechner (medium.com oder bioslevel.com). In größeren Netzwerken bestehen weitere Möglichkeiten, um Daten auf entfernten Rechnern zu speichern (NFS, iSCSI oder verteilte Dateisysteme wie DFS oder Ceph), die aber für kleine Setups (Heimserver, kleines Büro etc) häufig zu komplex sind. Es besteht aber häufig auch die Möglichkeit Speicherplatz bei einem anderen Cloud-Dienstleister zu mieten und diesen im eigenen Server einzubinden. Dabei muss dann der Datenschutz und die Datensicherheit im Blick behalten werden, z.B. indem die Backup-Daten vor dem Transfer verschlüsselt werden.
Nextcloud AIO Backup-Funktion
In Nextcloud AIO ist bereits eine Backup-Programm enthalten. Dieses muss jedoch zu Beginn konfiguriert werden. Da es auf dem weit verbreiteten Backup-Programm BorgBackup basiert, kann das Backup entweder auf einen lokalen Datenträger (lokales BorgBackup-Repository) erstellt werden. Oder auf einem entfernten Computer wird ein BorgBackup-Repository manuell erstellt und dieses Remote-Repository wird als Backup-Destination gewählt. Für die Grundlagen können die oben verlinkten Hinweise bezüglich Backup in AIO genutzt werden. Wer mehr Informationen zur Nutzung von BorgBackup benötigt (z.B. um ein Remote-Repositiory zu erstellen), kann sich direkt bei BorgBackup informieren. Mit Vorta existiert für Desktop-Betriebssysteme (Linux und MacOS) auch eine graphische Oberfläche.
Externe Speicher
Sinnvolerweise wird das Backup nicht auf demselben Datenträger wie die Nextcloud gespeichert. Um einen weiteren Datenträger im Linux-System einzubinden, müssen ein paar Schritte durchgeführt werden. Diese finden Sie in den Lernmaterialien des Kurses zu Self-Hosted Datamanagemtn beschrieben.
Nach der Installation von Nextcloud AIO erfolgt die Konfiguration
Wichtig: kümmern Sie sich um ein ordentliches Backup
Nextcloud AIO bringt mit BorgBackup eine anpassbare Backup-Lösung mit
Content from Knowledge-und Notizmanagement mit Joplin
Zuletzt aktualisiert am 2026-05-12 | Diese Seite bearbeiten
Übersicht
Fragen
Was kann ich noch mit Docker tun?
Wie kann ich meine Notizen besser verwalten?
Wie installiere ich den Joplin-Server?
Ziele
Möglichkeiten und Grenzen des Self- und OnPremise-Hostings
Einführung in Funktionen und Nutzung von Joplin
Installation von Joplin mit Docker Compose
Möglichkeiten des Self- und OnPremise-Hostings
-
sehr viel, v.a. Open Source Software
Siehe Awsome Selfhosted Github-Repo (Link)
v.a. Client-Server-Anwendungen
-
Beispiele, jeweils mit Links und kurzer Beschreibung
Medienstreaming: Jellyfin
Filetransfer: gokapi
Git: gitea
Smart Home: homeassistant
Hypervizor/Cloud Computing: proxmox
Backup: Bacula/Baculum
Syncthing
Kalender und Kontakt: Radicale
Chat und (Video)Telefonie: Matrix, Jitsi, Bigbluebutton
Grenzen des Self- und OnPremise-Hostings
Lizenzrechtliche Einschränkungen: z.B. Nur beim Anbieter, bestimmte Limits wie Useranzahl oder CPU-Ressourcen
Hardwareeinschränkungen: je höher die Anforderung, desto mehr Hardware nötig, z.B. für KI-Anwendungen Grafikleistung
Bandbreite: Bandbreite im LAN und Bandbreite des Netzanschlusses
Serverraum: Energiebedarf, Kühlung, Platzbedarf
Know-How: was kann man selbst oder ist bereit zu erlernen, was lagert man besser aus
Verfügbarkeit/Verlässlichkeit: kritische Infrastruktur muss immer laufen. Wie gut geschützt vor Ausfällen durch Softwareprobleme, Hardwareausfalls, Stromausfall, Einbruch, Wasserschaden, Blitzschlag
Möglichkeiten des Self- und OnPremise-Hostings
Self-Hosting im Privatbereich oder On-Premise-Hosting im Enterprisebereich bieten eine breite Palette an Möglichkeiten, insbesondere mit Open-Source-Software. Das Awesome Selfhosted GitHub-Repository bietet eine umfassende Liste von Beispielen. Das Self- OnPremisehosting ist v.a. dann Interessant, wenn es um Client-Server-Anwendungen geht. Peer-to-Peer-Anwendungen müssen i.d.R. nicht gehostet werden, sondern laufen nur auf den Endgeräten.
Einige Beispiele für selbst betriebene Software:
Medienstreaming-Server mit Jellyfin: Eine freie Softwaremedienbibliothek, die es Ihnen ermöglicht, Ihre Filme, Fernsehsendungen und Musik auf verschiedenen Geräten zu organisieren und in Ihrem Netzwerk zu streamen. Als Alternative zu Netflix, Amazon Prime oder dem DVD-Player.
Dateiübertragung: gokapi: Eine einfache und sichere Anwendung zur Dateiübertragung, die es Ihnen ermöglicht, Dateien zu teilen, z.B. per E-Mail, ohne auf externe Cloud-Dienste wie z.B. WeTransfer angewiesen zu sein.
Versionskontrolle nach Git-Standard mit gitea: Eine selbst gehostete Git-Plattform, die es Ihnen ermöglicht, Ihre eigenen Git-Repositories zu hosten und zu verwalten. Als Alternative zu github oder gitlab.
Smart Home: homeassistant: Eine Open-Source-Plattform, die es Ihnen ermöglicht, Ihre Smart-Home-Geräte zu integrieren und zu automatisieren, um Ihr Zuhause sicherer, bequemer und energieeffizienter zu machen.
Mit proxmox den eigenen Hypervisor für das eigene Cloud Computing betreiben: Eine Open-Source-Software, die es Ihnen ermöglicht, Ihren eigenen Hypervisor zu betreiben und virtuelle Maschinen und Container zu hosten, um Ihre Infrastruktur zu vereinfachen und zu skalieren.
Zentralisierte Backupverwaltung mit Bacula oder Baculum: Open-Source-Softwarelösungen für die Datensicherung, die es Ihnen ermöglichen, Ihre Daten zu sichern und wiederherzustellen, ohne auf Cloud-basierte Datensicherungsdienste angewiesen zu sein.
Dateisynchronisation mit Syncthing: Eine Open-Source-Software für die kontinuierliche Dateisynchronisation, die es Ihnen ermöglicht, Ihre Dateien zwischen Ihren (Mobil)Geräten zu synchronisieren. Alternative zu den Cloud-Lösungen der Smartphone-Hersteller (Google, Apple, Samsung etc)
Kalender und Kontakte: Radicale: Eine Open-Source-Software für die Verwaltung von Kalendern und Kontakten, die es Ihnen ermöglicht, Ihre Kalender und Kontakte selbst zu hosten und zu verwalten. Alternative zu Google Contacts.
Chat und (Video)Telefonie mit Matrix, Jitsi oder Bigbluebutton: Open-Source-Softwarelösungen für Chat und (Video)Telefonie, die es Ihnen ermöglichen, sicher und privat mit Ihren Freunden und Kollegen zu kommunizieren. Matrix bietet dabei Ende-zu-Ende-Verschlüsselung und zahlreiche Funktionen zur Integration in Unternehmen. Jitsi zielt eher auf den Privatbereichh oder kleinere Firmen. Bigbluebutton ist eine Videokonferenzlösung für den Bildungsbereich (Schule, Hochschulen, Kurse).
Grenzen des Self- und OnPremise-Hostings
Allerdings hat Self-Hosting bzw. On-Premise-Hosting auch Grenzen:
- Rechtliche Einschränkungen: Einige Software kann nur vom Anbieter verwendet werden oder unterliegt bestimmten Einschränkungen wie der Benutzeranzahl oder der maximal verwendbaren CPU-Kerne.
- Hardware-Einschränkungen: Je anspruchsvoller die Anwendung, desto mehr Hardware ist erforderlich. KI-Anwendungen erfordern beispielsweise erhebliche Grafikleistung.
- Bandbreite: Die Bandbreite im lokalen Netzwerk und die Bandbreite der Internetverbindung können limitierende Faktoren sein.
- Serverraum: Der Energieverbrauch, die Anforderungen an die Kühlung und der Platzbedarf können signifikant sein.
- Expertise: Bei der Entscheidung, was selbst gehostet werden soll oder was ausgelagert werden soll, muss auch das eigene Wissen bzw. die Bereitschaft zum Erwerb des Wissens in Betracht gezogen werden.
- Verfügbarkeit/Zuverlässigkeit: Kritische Infrastruktur muss stets verfügbar sein. Deshalb sollten auch Szenarien wie Ausfälle durch Anwenderfehler, Softwareprobleme, Hardwareausfälle, Stromausfälle, Einbruch, Wasserschaden oder Blitzschlag beachtet werden. Ist der Schutz davor lokal nicht möglich aber die Verfügbarkeit der Dienste nötig, sollte die Auslagerung an einen Dienstleister in Betracht gezogen werden.
Joplin: Knowledge-Management mit dem eigenen Server
Joplin ist eine Open-Source-Software für Notizen und Aufgabenverwaltung, die sowohl für Einzelpersonen als auch für Teams geeignet ist. Mit Joplin können Sie Ihre Notizen und ToDo-Listen sicher und privat auf Ihrem eigenen Server hosten, ohne auf Cloud-basierte Dienste angewiesen zu sein. Die Software unterstützt Markdown, bietet eine Vielzahl von Plugins und kann über verschiedene Plattformen synchronisiert werden.
Alternative: Notesnook
Eine alternative Lösung für Self-Hosting von Notizen ist Notesnook. Notesnook bietet ebenfalls eine sichere und private Möglichkeit, Ihre Notizen zu verwalten. Derzeit befindet sich das Self-Hosting via Docker noch in der Beta-Phase, aber es ist eine vielversprechende Option für diejenigen, die eine Alternative zu Joplin suchen.
Lizenz
Die Joplin-Clientanwendungen werden unter einer Open Source Lizenz veröffentlicht (AGPL-3). Der Source-Code ist frei einsehbar. Die Clientanwendungen können die erstellten Notizen entweder bei Kauf eines Abonnements beim Anbieter über dessen Server, über einen selbst betriebenen Joplin-Server oder über andere Dienste wie Nextcloud oder Dropbox synchronisiert werden. Siehe dazu die Kapitel im Handbuch. Die Synchronisation mit einem Joplin Server (Joplin Cloud oder Self Hosted) bietet dabei mehr Perfomance und Funktionalität (z.B. Teilen von Notizen).
Softwarekomponenten
-
Joplin-Server: optional, Server für Synchronistation. Entweder beim Anbieter mieten oder selbst hosten.
- Alternative Synchronsationsserver: Nextcloud, Dropbox, OneDrive u.a.
Joplin-Clients: Client-Awendung zum verfassen von Notizen. Verfügbar für PC, Mac und Mobilgeräte
Funktionen
-
Notizen und ToDo-Listen verfassen
im Markdown-Format
in einer “normalen” Ansicht (WYSIWYG-Editor)
-
Unterstützt u.a.
- ToDo-Listen
- Tabellen
- Abbildungen
- Handzeichnungen
Automatisierte Backups
zahlreiche Erweiterungen
Organisation durch Schlagworte und Sammlungen (“Notizbücher”)
Installation
Im Github-Repository findet sich ein Beispiel für eine compose.yaml-Datei. Diese beinhaltet auch einen Service für den Transcribe-Dienst zur Übersetzung von handschriftlichen Notizen in digitale Texte. Dieser Dienst benötigt sehr viel Ressourcen, weshalb dieser Container (und damit das Transcribe-Feature) im Selfhostingbereich evtl. weg gelassen werden sollte.
Eine auch für kleinere Umgebungen geeignete compose.yaml-Datei kann wie folgt aussehen
Ergänzt wird die Compose Datei durch eine .env-Datei für
die Umgebungsvariablen. Auch dafür gibt es eine Vorlage
die wie folgt vereinfacht werden kann:
APP_BASE_URL=https://example.com/joplin
APP_PORT=22300
DB_CLIENT=pg
POSTGRES_PASSWORD=joplin
POSTGRES_DATABASE=joplin
POSTGRES_USER=joplin
POSTGRES_PORT=5432
POSTGRES_HOST=joplin-db
Wichtig sind dabei die APP_BASE_URL und die POSTGRES_ Parameter. Statt einer Datenbank kann auch das Dateisystem als Speicher genutzt werden (siehe hier). Grundlegend wird aber eine Datenbank als Speicher empfohlen.
Damit der Joplinserver erreicht werden kann, muss eine Domain vorhanden sein und im NGINX-Proxy-Manager hinterlegt sein.
Die Konfiguration des Proxy-Hosts sieht wie folgt aus:
Die Clientanwendung für die Endgeräte kann auf der Homepage von Joplin heruntergeladen und installiert werden.
Konfiguration
- Nach der Installation der Clientanwendgung muss in den Einstellungen
die Verbindung zum eigenen Joplinserver eingetragen werden. Dazu im Menü
unter Werkzeuge den Punkt Optionen öffnen und als Synchronisationsziel
Jopin Server (Beta)auswählen. Anschließend kann die URL zum eigenen Server, der Nutzername und das Passwort eingetragen werden. Anschließend kann die Verbindung getestet werden.
- Um Datenverlust zu vermeiden empfiehlt es sich, die Notizen am Endgerät zu sichern. Dazu kann unter dem Punkt ein Zielverzeichnis gewählt werden und die genaue Ausführung eingerichtet werden. Werden die Notizen auf einem unverschlüsseltem Medium gepspeichert, empfiehtl sich das Setzen eines Passwortes, um zu verhindern, dass die Notizen von Dritten eingesehen werden können.
- Wurden weitere Plugins installiert (z.B. der Web Clipper, oder das KI-Tool Jarvis) können diese ebenfalls in den Optionen eingerichet werden
Ist Docker einmal installiert und ein Reverse Proxy eingerichtet, können schnell weitere Dienste gehostet werden
Mit Joplin können die eigenen Notizen (und ggf. die des Teams) auf dem eigenen Server gespeichert werden
Joplin kann mit dem Joplin Server oder anderen Dateidiensten betrieben werden
Der Joplin Server kann mit Docker Compose installiert werden
Content from Mehr Docker
Zuletzt aktualisiert am 2026-05-12 | Diese Seite bearbeiten
Übersicht
Fragen
Wie kann ein fertiges Dockerimage angepasst werden?
Wie verknüpfte ich ein DOCKERFILE in einem Docker Compose Projekt?
Muss ich Docker immer über die Kommandozeile bedienen?
Welche Alternativen zu Docker gibt es?
Ziele
Dockerimage mit DOCKERFILES anpassen
den
docker compose buildBefehl nutzenPortainer als GUI für Docker
Docker Swarm, Podman und Kubernetes als Alternativen zu Docker
Anpassung von Dockerimages
Im bisherigen Verlauf des Kurses wurden fertige Dockerimages genutzt.
Diese wurden in der Compose-Datei mit dem Key image:
angebene. Es kommt jedoch vor, dass diese fertigen Images nicht ganz den
eigenen Bedürfnissen entsprechen. Häufig fehlen bestimmte Programme oder
Dateien im Image. Um diese zu ergänzen kann ein Image angepasst
werden.
Das DOCKERFILE als Bauanleitung
Ein Dockerimage kann mithilfe eines sog. Dockerfile
erstellt und angepasst werden. Das Dockerfile enthält eine
Reihe von Anweisungen, die Docker befolgt, um das Image zu bauen. Hier
sind einige grundlegende Anweisungen, die in einem
Dockerfile verwendet werden können:
-
FROM: Gibt das Basisimage an, von dem abgeleitet wird. -
RUN: Führt Befehle im Container aus. -
COPY: Kopiert Dateien oder Verzeichnisse vom Host in das Image. -
CMD: Gibt den Befehl an, der ausgeführt wird, wenn der Container startet.
Ein einfaches Beispiel für ein Dockerfile kann wie folgt
aussehen:
DOCKERFILE
FROM ubuntu:latest
RUN apt-get update && apt-get install -y python3
COPY . /app
WORKDIR /app
CMD ["python3", "/app/app.py"]Dieses Dockerfile erstellt ein Image basierend auf dem
neuesten Ubuntu-Image, installiert Python 3, kopiert die Dateien des
aktuellen Arbeitsverzeichnisses in das Verzeichnis /app im
Container und führt die Datei app.py aus, wenn der
Container startet.
Der docker compose build Befehl
Um die erstellte Bauanleitung im Dockerfile zu nutzen,
wird die Compose-Datei abgeändert und statt des fertigen Images mit dem
build-Befehl das Dockerfile genutzt.
In diesem Beispiel wird ein Webservice definiert, der das Dockerimage
basierend auf dem dockerfile mit Namen DOCKERFILE baut und
den Port 5000 des Hosts auf den Port 5000 des Containers weiterleitet.
Ein weiterer Service namens redis wird aus dem
vorgefertigten redis:alpine-Image erstellt (ohne angepasst
zu werden).
Um die Images zu bauen, wird der folgende Befehl verwendet:
Ist der Build-Prozess erfolgreich abgeschlossen (dies kann je nach
DOCKERFILE sehr lange dauern), kann das Compose-Projekt wie
gewohnt gestarte werden: sudo docker compose up -d
Docker Images aktualisieren
Wenn neue Versionen eines Docker-Images veröffentlicht werden, muss das bestehende Image aktualisiert werden. Um ein neues Image zu laden und das alte zu ersetzen, wird wie folgt vorgegangen:
-
Definiton eines neuen Images: Stellen Sie sicher,
dass Ihre
compose.yml-Datei auf das neue Image verweist. Ändern Sie die ggf. die Versionsangabe in derimage-Zeile entsprechend.
Zum Beispiel wird aus Version 10:
Version 11:
Häufig wird auf die latest oder
stable-Version verwiesen. Diese Angabe bewirkt, dass bei
der Aktualisierung immer die dann aktuelle Version geladen wird. Ist
dies nicht gewünscht, muss die Version wie oben im Beispiel gezeigt
explizit angegeben werden.
Herunterladen des neuen Images: Führen Sie den Befehl
docker compose pullaus, um das neue Image herunterzuladen. Dieser Befehl aktualisiert die Images, die in dercompose.yml-Datei definiert sind. Der Download kann in Abhängigkeit der Anzahl und Größe der enthaltenen Images einige Zeit dauern.Starten des neuen Images: Nachdem das neue Image heruntergeladen wurde, können Sie die Container mit dem neuen Image neu starten:
sudo docker compose up -d --remove-orphans-
Löschen des alten Images: Um das alte Image zu löschen und Speicherplatz freizugeben, können Sie den Befehl
docker image rmverwenden. Zuerst müssen Sie jedoch sicherstellen, dass keine Container mehr das alte Image verwenden. Verwenden Sie den Befehldocker image ls, um die Liste der Images anzuzeigen, und danndocker image rm <image_id>, um das alte Image zu löschen.Etwas schneller aber weniger Umsichtig können die alten Images mit dem Befehl
sudo docker image prunegelöscht werden.
Wird in der Compose-Datei der Build-Befehl genutzt, muss vor dem
docker pull-Befehl noch der build-Befehl wie
oben neu ausgeführt
werden.
Weitere Informationen zu diesem Prozess finden sich auch bei Stack Overflow.
Um auch andere Docker-Komponenten zu löschen, empfiehlt es ich, den docker prune-Befehl regelmäßig auszuführen. Siehe dazu die offizielle Anleitung.
Portainer als GUI für Docker
Portainer ist eine benutzerfreundliche grafische Benutzeroberfläche (GUI) für die Verwaltung von Docker-Containern. Mit Portainer können Sie Container starten, stoppen, verwalten und überwachen, ohne die Docker-Befehlszeile verwenden zu müssen.
Portainer wird selbst als Docker Container installiert und gestartet:
SH
sudo docker volume create portainer_data
sudo docker run -d -p 8000:8000 -p 9443:9443 --name portainer --restart=always -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainer-ce:ltsNach der Installation kann Portainer über einen Webbrowser unter
http://<Server-IP-oder-URL>:9000 erreicht werden
(vorausgesetzt der Proxy Host ist eingerichtet).
Mehr Informationen finden sich in der Dokumentation von Portainer.
Docker Swarm, Podman und Kubernetes als Alternativen zu Docker
Neben Docker gibt es mehrere alternative Technologien, die ähnliche Funktionen bieten:
Docker Swarm: Docker Swarm ist eine native Clustering- und Orchestrierungslösung für Docker. Sie ermöglicht es, mehrere Docker-Hosts zu einem Cluster zusammenzufassen und Anwendungen darauf zu verteilen. Docker Swarm ist einfach zu verwenden und in Docker integriert.
Podman: Podman ist eine daemonlose Alternative zu Docker, die kompatibel mit Docker-Images und -Containern ist. Podman bietet eine ähnliche Befehlszeilensyntax wie Docker, arbeitet jedoch ohne einen zentralen Daemon, was die Sicherheit und Isolierung verbessert. So benötigt Podman standardmäßig keine Root-Rechte zum starten der der Container.
Kubernetes: Kubernetes ist eine leistungsstarke Orchestrierungsplattform für Container, die eine umfassende Verwaltung und Skalierung von Containeranwendungen ermöglicht. Kubernetes ist komplexer als Docker Swarm, bietet jedoch mehr Funktionen und Flexibilität für große und komplexe Anwendungen.
Dockerimages könne mit Dockerfiles angepasst werden
ein Dockerfile ist die Bauanleitung für ein Dockerimage
Dockerimages müssen regelmäßig aktualisiert werden
Portainer bietet eine Weboberfläche zur Verwaltung von Docker