Dateiformate
Zuletzt aktualisiert am 2025-08-21 | Diese Seite bearbeiten
Geschätzte Zeit: 40 Minuten
Übersicht
Fragen
- Binär vs. Text?
- Dateiformate?
- Was für was?
Ziele
- Verständnis dafür wie Daten gespeichert werden
- Wissen um gängige Dateiformate zur Datenhaltung
- Überblick welche Formate für welche Daten und Zwecke geeignet sind
Um Daten zu speichern oder weitergeben zu können, müssen sie in einer Datei abgelegt werden. Damit die Daten auch später wieder gelesen und verarbeitet werden können, muss dies in einer festgelegten Art und Weise geschehen, was durch das Dateiformat bestimmt wird. Damit man später noch weiss, welches Dateiformat verwendet wurde, wird dieses durch eine entsprechende Dateiendung (engl. file extension) hinterlegt. Die Dateiendung ist also lediglich ein Hinweis darauf, in welchem Format die Daten abgelegt sind, hat darüber hinaus aber keine weitere Bedeutung.
Binär vs. Text
Dateien können entweder in binärer oder Textform abgelegt werden. Dazu müssen wir uns erinnern, dass jedwede Information in einem Computer als Ganzzahl kodiert und diese in Binärzahlen, also einer Abfolge von Bits (0 und 1), repräsentiert und verwaltet werden.
Nun gibt es zwei Möglichkeiten, wie diese computerinterne Datenrepräsentation in einer Datei abgelegt werden kann.
Am kompaktesten und effizientesten ist es, die interne Binärdatendarstellung direkt als Binärdaten in einer Datei abzulegen, also als eine Abfolge von 0 und 1. Dieses wird als sogenannte binäre Datei bezeichnet. Dies hat den Vorteil, dass die Daten sehr schnell und effizient gelesen und geschrieben werden können, da keine Umwandlung notwendig ist. Allerdings sind binäre Dateien für Menschen nicht lesbar, da sie nur aus einer Abfolge von 0 und 1 bestehen, sodass keine Interpretation oder Inspektion der Daten möglich ist. Zudem sind binäre Dateien nicht oder nur bedingt portabel, da sie von der internen Datenrepräsentation des Computers und des verwendeten Anwendungsprogramms abhängen und daher nicht ohne weiteres auf anderen Systemen oder mit anderer Software gelesen werden können.
Daher werden binäre Dateiformate in der Regel nur für spezielle Anwendungen verwendet, bei denen es auf Geschwindigkeit und Effizienz ankommt, oder wenn die Daten nicht von Menschen gelesen werden müssen. Zudem sind binäre Dateiformate in der Regel spezialisiert und proprietär1, d.h. sie sind nur für bestimmte Anwendungen oder Programme geeignet und können nicht ohne weiteres von anderen Programmen gelesen oder verarbeitet werden.
Aufgrund dessen sind binäre Dateiformate in der Regel nicht für den allgemeinen Datenaustausch oder die Langzeitarchivierung geeignet.
Stattdessen werden Daten, die ausgetauscht oder archiviert werden sollen, in der Regel in Textform abgelegt. Hierbei werden die internen Binärdaten in eine menschlich lesbare Form umgewandelt, z.B. in Buchstaben, Zahlen oder Sonderzeichen, und als Text in einer Datei abgelegt. Dieser muss nicht zwingend in einer menschenlesbaren Form sein, sondern kann auch in einer maschinenlesbaren Form abgelegt werden, z.B. als strukturierte Daten oder in einer speziellen Syntax.
Grundlegend ist aufgrund der Textform jedoch gesichert, dass die Daten in einer Form abgelegt sind, die unabhängig von der computerinternen Datenrepräsentation ist und daher portabel und unabhängig von der verwendeten Software oder dem Betriebssystem ist.
Ist das binär oder textbasiert?
Um zu überprüfen, ob eine Datei binär oder textbasiert ist, können Sie die Datei einfach mit einem Texteditor öffnen. Dies ist mit jeder Datei möglich, unabhhängig von der Dateiendung oder dem Dateiformat!
Wenn die Datei text-basiert ist, können Sie den Inhalt lesen und bearbeiten. Falls nicht, wird der Inhalt der Datei als unleserlicher Text oder als Zeichenfolge von Sonderzeichen angezeigt, wie in folgendem Beispiel.
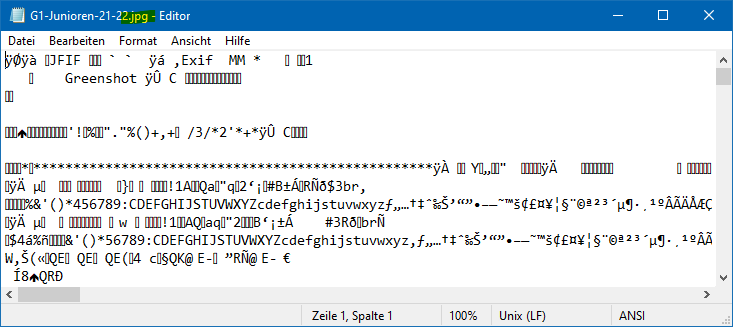
Sie sind dran ..
Öffnen Sie in einem Texteditor ihrer Wahl eine MS Excel Datei und eine PDF Datei.
Was sehen Sie? Sind die Dateiformate binär oder textbasiert?
Die Excel-Datei wird als unleserlicher Text oder als Zeichenfolge von Sonderzeichen angezeigt, da sie im binären XLSX-Format gespeichert ist. Letzteres ist eigentlich ein komprimiertes ZIP-Archiv, das verschiedene Dateien und Ordner enthält, die die Tabellenkalkulation und die Daten enthalten.
Die PDF-Datei wird je nach Inhalt als Mix aus lesbarem Text und Sonderzeichen angezeigt. Das PDF-Format ist ein Hybridformat, in dem bestimmte Inhalte (wie Bilder) in einem binären Format gespeichert sind, während der Text z.T. in einer menschenlesbaren Form abgelegt ist.
Doch dazu später mehr…
Standard vs. Spezialformat
Die Wahl des Dateiformats hängt stark von der Art der Daten und ihrer Verwendung ab. Für den allgemeinen Datenaustausch und die Langzeitarchivierung sind Textformate in der Regel besser geeignet, da sie portabel, unabhhängig und zukunftssicher sind. Für den internen Gebrauch oder spezielle Anwendungen können jedoch auch binäre Formate sinnvoll sein, da sie schneller und effizienter sind und spezielle Funktionen oder Eigenschaften bieten können.
Daher sollten Rohdaten und Metadaten in einem Standardformat abgelegt werden, das von verschiedenen Programmen und Systemen gelesen und verarbeitet werden kann. Zudem sollten am Ende des Forschungsprozesses zur Publikation die finalen, verarbeiteten Daten in Standardformaten abgelegt werden, um die Nachnutzung und Langzeitarchivierung zu erleichtern.
Während des Forschungsprozesses können jedoch auch spezielle oder proprietäre Formate verwendet werden, um die volle Leistungsfähigkeit und Funktionalität der verwendeten Software auszuschöpfen.
Im Folgenden werden wir einige der gängigsten Dateiformate für den Datenaustausch und die Langzeitarchivierung vorstellen und ihre Verwendungszwecke und Eigenschaften erläutern.
Nur Text
Die einfachste Möglichkeit beliebige Information zu speichern ist in Form von unformatierten Textdateien. Diese enthalten nur eine texttuelle Repräsentation der Information in Form von Buchstaben, Zahlen und Sonderzeichen, und haben darüber hinaus keine spezielle Struktur oder Formatierung.
Derartige Dateien werden i.d.R. mit der Dateiendung
.txt versehen und können mit jedem Texteditor
geöffnet und bearbeitet werden. Hierbei ist zu beachten, das MS Word
oder andere Textverarbeitungsprogramme nicht als Texteditor
geeignet sind, da sie zusätzliche Formatierungen und Metadaten in die
Datei schreiben, die den reinen Textinhalt verfälschen.
Geeignete Texteditoren sind z.B.
- Notepad++ (Windows),
- TextEdit (Mac),
- gedit (Linux) oder
- Microsoft Windows Editor.
Wenn die Textdatei in einer strukturierten Form vorliegt, d.h. wenn die Information in Zeilen und Spalten organisiert oder durch spezielle Schlüsselwörter oder Trennzeichen strukturiert ist, dann spricht man von einem textbasiertem Dateiformat.
Formattierter Text
Markdown
Dateiendungen: .md,
.markdown
Markdown ist eine einfache Auszeichnungssprache für Textdateien. Das heisst, einzelne Textabschnitte können mit speziellen Zeichen oder Schlagworten versehen werden, um ihre Formattierung zu bestimmen. Die Formatierung selbst geschieht in einem nachfolgenden Verarbeitungsschritt, bei dem der formatierte Text in einem geeigneten Format, z.B. HTML, PDF, .., abgespeichert wird.
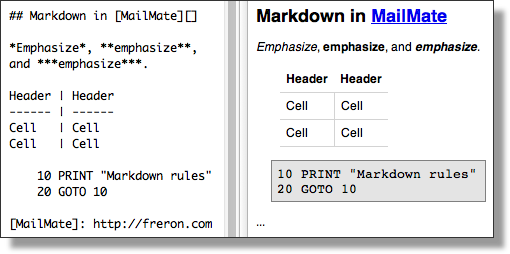
Studieren sie folgende Webseite, in der Markdown und seine Anwendungen erklär werden:
-
Markdown
Guide - Get Started (Englisch)
- oder in Deutsch via google.translate (mit einigen lustigen Übersetzungsartefakten …)
Da die Formatierung von Markdown immer in einem separaten Schritt erfolgt, ist es sinnvoll einen Editor zu verwenden, der die Formatierung in Echtzeit anzeigt. Im Rahmen des Kurses (und ggf. auch darüber hinaus) empfehlen wir daher den Onlineeditor dillinger.io, welcher ohne Registrierung oder Installation genutzt werden kann.
Challenge
Verwenden sie den Onlineeditor dillinger.io um ein einfaches Markdown-Dokument zu erstellen.
Versuchen sie darin einige der kleinen “Best Practice” Tipps, welche auf der Webseite Markdown Guide - Basic Syntax vorgestellt werden.
Markdown wird sehr häufig für Dokumentationen, Readme-Dateien und auch für einfache Webseiten verwendet. (Auch diese Webseite wurde basierend auf Markdown erzeugt!)
In diesem Kurs werden wir daher ab sofort Markdown für (fast) alle Dokumentationen verwenden, um dies zu üben.
Sie können daher dillinger.io schon direkt zu ihren Lesezeichen im Browser hinzufügen.
.md Dateiendung mit Texteditor
verknüpfen
Dateiendungen dienen vorrangig dazu, dass das Betriebsystem
automatisch erkennt, mit welchem Programm eine ausgewählte Datei
geöffnet werden soll. Für Markdowndateien mit der Dateiendung
.md ist in den meisten Betriebssystemen keine solche
Assoziation mit einem “Standardprogramm” direkt vorhanden. Daher sollte
diese eingerichtet werden, wenn man häufiger, wie in diesem Kurs, mit
Markdown Dateien arbeiten möchte.
Aufgabe:
- Exportieren sie ihre Markdown-Spielerei aus der letzten Aufgabe aus
dillinger.io heraus
- dazu oben rechts “Export as” > “Markdown” auswählen
- Speichern sie die Datei auf ihrem Computer an einem Ort ihrer Wahl (den sie wiederfinden…)
- Setzen sie als Standardprogramm zum Öffnen von Markdown-Dateien ihren Texteditor
- Versuchen sie nun die heruntergeladene Datei zu öffnen (z.B. via
Doppelklick)
- Ziel ist es, das nun ihr installierter Texteditor die Markdown-Datei anzeigt
HTML
Dateiendungen: .html,
.htm
Ähnlich wie Markdown ist auch HTML (HyperText Markup Language) eine Auszeichnungssprache, die zur Strukturierung von Texten in Webseiten verwendet wird. Im Gegensatz zu Markdown ist HTML jedoch deutlich komplexer und ermöglicht eine detaillierte Strukturierung und Formatierung von Texten und zusätzlichen Inhalten (z.B. Bilder, Videos, …). HTML-Dateien können mit jedem Texteditor geöffnet und bearbeitet werden, jedoch ist zur Anzeige der Formatierung ein Webbrowser erforderlich. Das heißt, analog wie bei Markdown, muss der HTML-Code erst durch ein Programm (i.d.R. dem Browser) interpretiert und dargestellt werden.

Webseiten bestehen aus einer Kombination von HTML, CSS und Javascript, wobei
- HTML die Struktur und den Inhalt der Seite definiert,
- CSS das Aussehen und die Formatierung steuert und
- Javascript die Interaktivität und Funktionalität hinzufügt.
Webseiten werden häufig zur Präsentation, Publikation oder Dokumentation von Forschung und deren Daten verwendet.
Aufgrund der zugrundeliegenden Struktur von HTML-Dateien, kann man teilweise auch direkt aus Webseiten die präsentierten Daten extrahieren. Dies nennt sich Web Scraping. Allerdings ist eine zusätzliche Bereitstellung der Daten in einem datenfokussierten Dateiformat (z.B. CSV, JSON) meist sinnvoller und empfohlen.
Das Portable Document Format (PDF) ist ein Dateiformat, das entwickelt wurde, um Dokumente unabḧängig von Anwendungen, Betriebssystemen oder Hardwareplattformen anzuzeigen und auszudrucken. Damit ist es möglich, Dokumente so zu speichern, dass sie auf jedem Gerät gleich aussehen, was bei Markdown und HTML nicht der Fall ist.
PDF-Dateien können Text, Bilder, Links, Formulare, Audio- und Videodateien enthalten und sind daher ein weit verbreitetes Format für die Präsentation und den Austausch von Dokumenten. Auch ist es möglich, die Bearbeitung, Druckbarkeit, … von PDF-Dateien zu beschränken, um die Integrität und Authentizität von Dokumenten zu gewährleisten. Allerdings sind diese Sicherheitsfeature nur bedingt wirksam und können durchaus umgangen werden.
PDF Dateien sollten für “Endprodukte” verwendet werden, die nicht mehr verändert werden sollen, z.B. für Berichte, Präsentationen, Publikationen, etc. Sie sind wenig geeignet für die Zusammenarbeit und Weiterverarbeitung von Daten, da sie nicht so einfach zu bearbeiten sind wie Textdateien oder textbasierte Dateiformate.
Fast alle Betriebssysteme beinhalten mittlerweile einen virtuellen “PDF Drucker”. Damit kann jedes Dokument, welches gedruckt werden kann, auch als PDF-Datei gespeichert werden.
Dies ist besonders nützlich, um Dokumente zu archivieren oder zu teilen, da PDF-Dateien auf den meisten Geräten und Betriebssystemen angezeigt werden können, ohne dass spezielle Software erforderlich ist.
Grundlegend kann (fast) jedes PDF-Dokument mit einem entsprechenden Editor (z.B. Adobe Acrobat oder verschiedenen Onlinetools) bearbeitet werden. Allerdings erfolgt die Bearbeitung in der Regel nicht im Quellcode, sondern in einer grafischen Benutzeroberfläche, da das PDF-Format einen Mix aus Text- und Binärinformationen enthalten kann.
PDF editieren
Nehmen sie ein beliebiges PDF-Dokument und versuchen sie es mit einem PDF-Editor zu bearbeiten. Hierfür finden sich auch zahlreiche kostenlose Online-Tools.
DOCX, ODT, …
Um formatierte Texte zu schreiben und zu speichern werden häufig Textverarbeitungsprogramme wie Microsoft Word, Google Docs oder LibreOffice Writer verwendet.
Häufige Dateiendungen für derartige Textverarbeitungsdateien sind:
-
.docx- Microsoft Word (von Microsoft entwickelter Standard) -
.odt- OpenDocument Text (quelloffener freier Standard)
Diese Dateiformate enthalten neben dem reinen Text auch Informationen zur Formatierung, Schriftart, Farben, Autor, … und können daher nicht direkt in einem Texteditor geöffnet und bearbeitet werden. Allerdings können sie in Textdateien (z.B. Markdown) oder PDF-Dateien konvertiert werden, um sie einfacher zu teilen oder zu archivieren.
Da diese Dateiformate proprietär sind, kann es zu Kompatibilitätsproblemen kommen, wenn sie von verschiedenen Programmen oder Versionen geöffnet werden. Das heißt, dass die Formatierung oder der Inhalt der Datei möglicherweise nicht korrekt angezeigt wird, wenn sie in einem anderen Programm geöffnet wird.
Daher wird empfohlen, für Dokumentationen und Texte, die geteilt oder archiviert werden sollen, stattdessen reine Textdateien, textbasierte Dateiformate oder PDF-Dateien zu verwenden.
Dokumentation in .md oder .docx?
Warum ist es besser, Dokumentationen und beschreibende Texte in Markdown-Dateien statt in Word-Dokumenten zu speichern?
- Plattformunabhängigkeit: Markdown-Dateien können auf jedem Betriebssystem und mit jedem Texteditor geöffnet und bearbeitet werden, während Word-Dokumente ein entsprechendes Textverarbeitungsprogramm benötigen.
- Versionierung: Markdown-Dateien können leichter in einem Versionskontrollsystem (z.B. Git) gespeichert und lokale Änderungen dokumentiert werden.
- Flexibilität: Markdown-Dateien können einfacher (automatisiert) in beliebige Formate (z.B. HTML, PDF) oder auch Präsentationsformen (Webseite, Buch, …) konvertiert werden.
Programmierskripte
Neben reiner Textinformation werden auch Programmierskripte in Textdateien abgelegt. Diese enthalten Anweisungen und Befehle, die von einem Computer ausgeführt werden können, um bestimmte Aufgaben zu erledigen. Die Skripte werden in einer Programmiersprache geschrieben, die speziell für die Erstellung von Programmen und Skripten entwickelt wurde. Zur Dokumentation und Weitergabe von (Forschungs)Daten ist es daher häufig wichtig, auch die verwendeten Programmierskripte zu speichern und zu teilen. Daher sollten sie gängige Programmiersprachen und -skripte kennen, um derartige Dateien identifizieren zu können.
Einige wichtige Dateiendungen für Programmierskripte sind:
-
.py- Python -
.R- R -
.js- Javascript -
.sh- Shell - Linux/MacOS Kommandozeile -
.bat- Batchskripte - MS DOS/Windows Kommandozeile -
.ps1- Powershellskripte - erweiterte MS Windows Kommandozeile
Markdown wird auch sehr häufig in Verbindung mit Programmiersprachen verwendet, um Codebeispiele und Dokumentationen zu erstellen. Zudem wurden “Hybridformate” entwickelt, die sowohl Markdown für Beschreibungen als auch direkt auszuführende Programmieranweisungen enthalten. Beispiele hierfür sind:
- Jupyter Notebooks (
.ipynb), - R Markdown (
.Rmd) oder R Notebooks (.Rnb).
Diese Formate ermöglichen es, Code und Dokumentation bzw. Interpretation in einem Dokument zu kombinieren und interaktiv auszuführen, was sie besonders für die Datenanalyse und -visualisierung geeignet macht. Zudem können sie in verschiedene Formate exportiert werden, z.B. als HTML, PDF oder Präsentation, was sie für die Veröffentlichung und den Austausch von Ergebnissen nützlich macht. Auch hier gilt, dass ggf. nicht nur das erzeugte finale Dokument, sondern auch das ursprüngliche Notebook gespeichert und geteilt werden sollte, um die Nachvollziehbarkeit und Reproduzierbarkeit der Analyse zu gewährleisten.
Tabellen
Dateiendungen:
- textbasierte Formate, z.B.
-
.csv- Comma Separated Values -
.tsv- Tab Separated Values
-
- binäre Formate, z.B.
-
.xls,.xlsx- MS Excel -
.ods- OpenDocument Spreadsheet
-
Bei der Datenerhebung, -verarbeitung oder zur -archivierung werden Daten häufig in tabellarischer Form gespeichert. Hierbei werden die Daten in Zeilen und Spalten organisiert, wobei in einzelnen Spalten nur Informationen der gleichen Form (Zahl, Text, ..) gelistet werden.
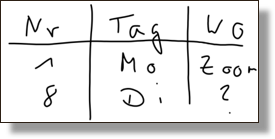
Tabellen können in textbasierten Formaten (z.B. CSV) oder binären Formaten (z.B. XSLX) digital gespeichert werden. Textbasierte Formate sind plattformunabhängig und können in jedem Texteditor geöffnet und bearbeitet werden, während binäre Formate spezifische Programme erfordern und ggf. zu Kompatibilitätsproblemen führen können. Zudem werden zur Verarbeitung von binären Formaten in Programmiersprachen häufig zusätzliche Funktionalitäten (Pakete) benötigt, was die Verwendung und Nachnutzung erschweren kann.
Eine der häufigsten Formen der tabellarischen Daten ist das CSV-Format (Comma Separated Values), bei dem die Daten durch Kommas getrennt in einer Textdatei gespeichert werden. Eine mögliche CSV-Repräsentation der obigen Tabelle ist wie folgt.
Nr,Tag,Wo
1,Mo,Zoom
8,Di,?Problematisch …
Welche Probleme sehen sie mit der obigen CSV-Kodierung der Tabelle? Was kann problematisch werden?
- Spaltentrennzeichen: Da es sich um einen deutschsprachigen Datensatz mit Zahlen handelt, kann es zu Problemen mit dem Spaltentrennzeichen “,” kommen, falls Dezimalzahlen z.B. “2,34” im Datensatz auftreten. In diesem Fall wäre es nicht eindeutig, ob das Komma ein Spalten- oder Dezimaltrennzeichen ist. Das gleiche Problem ergibt sich, wenn komplette Sätze (die potentiell Kommas enthalten) gespeichert werden. Daher hat sich im westeuropäischen Raum das Semikolon “;” als Trennzeichen etabliert (welches auch als CSV2-Format bezeichnet wird). Alternativ kann auch das TSV-Format verwendet werden, das Tabulatoren als Spaltentrenner verwendet.
-
Fehlende Daten: Hier wurden fehlende Daten mit
“
?” vermerkt. Während dies für menschliche Augen ein hilfreicher Hinweis sein kann, ist er für die automatische Datenverarbeitung schlecht geeignet. Wenn einzelne Daten fehlen, sollte in der jeweiligen Spalte einfach keine Information angegeben werden. In diesem Falle also besser “8,Di,”. - Textkodierung: Da der Datensatz Text enthält, können beim Import Probleme mit der Zeichenkodierung auftreten. Aktuell wird empfohlen UTF-8 zu verwenden.
Kommentare und Metadaten
CSV sieht i.d.R. keine Kommentare, Metadaten, etc. vor. Daher sollten
diese Informationen in einer separaten Datei oder in einem anderen
Format gespeichert werden. Falls unbedingt nötig, werden Kommentare in
CSV-Dateien i.d.R. in den ersten Zeilen gelistet und durch spezielle
Zeichen (z.B. #) am Anfang der Kommentarzeilen markiert.
Damit ist es möglich, diese beim Import zu überspringen oder zu
ignorieren
Hierarchische Daten
Dateiendungen:
-
.json- JavaScript Object Notation -
.xml- Extensible Markup Language -
.yaml- YAML Ain’t Markup Language
Eine Alternative zur tabellarischen Datenspeicherung bieten hierarchische Datenformate, die Informationen in einer verschachtelten Struktur speichern. Hierbei können Daten in beliebiger Tiefe und Komplexität organisiert werden, was sie besonders für die Speicherung von Metadaten oder strukturierten Daten geeignet macht. Zudem liefert diese Form der Datenrepräsentation direkt die Möglichkeit, Zusammenhänge und Beziehungen zwischen den Daten zu speichern.
JSON
JSON (JavaScript Object Notation) ist, wie der Name schon sagt, ein auf der Programmiersprache JavaScript basierendes Format, das Daten in einem hierarchischen Format speichert. Einzelne Datensätze werden wie folgt repräsentiert:
Hierbei werden die Daten in Doppelpunkt-getrennten
Schlüssel-Wert-Paaren gespeichert, wobei die Werte
beliebige Datentypen annehmen können (Zahlen, Text, Listen, …).
Datensätze selbst werden durch geschweifte Klammern {}
begrenzt, wobei die einzelnen Schlüssel-Wert-Paare durch Kommas getrennt
werden. Diese Struktur kann beliebig tief verschachtelt werden, um
komplexe Datenstrukturen abzubilden. In unserem Beispiel können wir die
Informationen für mehrere Treffen wie folgt speichern:
JSON
{
"Termine" : [
{
"Nr": 1,
"Tag": "Mo",
"Ort": "Zoom"
},
{
"Nr": 8,
"Tag": "Di",
"Ort": null
}
]
}Hierbei werden die einzelnen Treffen in einer Liste
Termine mit eckigen Klammern []
zusammengefaßt, welche wiederum die einzelnen Treffen als JSON-Objekte
enthält. Wichtig: die Liste selbst ist auch wieder ein JSON-Objekt, das
in geschweiften Klammern {} eingebettet wird (die “äußeren”
Klammern umfassen den Datensatz). Einrückung, Zeilenumbrüche und
Leerzeichen sind rein zur besseren Lesbarkeit erlaubt, können aber
weggelassen werden. Letzteres ist insbesondere bei großen Datenmengen
sinnvoll, um die Dateigröße zu reduzieren.
Beachten sie, dass es hier (im Gegensatz zu CSV) keine Probleme mit
dem Komma als Trennzeichen gibt, da die Daten in einem strukturierten
Format gespeichert sind. Zudem werden fehlende Daten durch
null repräsentiert, was der eindeutigen Information über
fehlende Daten in JavaScript Notation entspricht. Allerdings müssen, wie
in JavaScript, Textinformationen (sowie “Datennamen”) immer in
Anführungszeichen gesetzt werden, was die Lesbarkeit im Vergleich zu CSV
etwas erschwert.
JSON ist ein weit verbreitetes Format, das in vielen Programmiersprachen unterstützt wird und sich gut für den Datenaustausch zwischen verschiedenen Systemen eignet. Allerdings eignet es sich nur bedingt für die manuelle Bearbeitung durch Menschen, da es aufgrund der kompakten Strukturierung und der Anführungszeichen schnell unübersichtlich werden kann. Daher wird es i.d.R. automatisiert erzeugt oder in Kombination mit einem Editor oder einer speziellen Software verwendet, die die Strukturierung und Lesbarkeit der Daten verbessert, was wir im Folgenden ausprobieren werden.
JSON-Beispiel
- Öffnen sie den JSON-Onlineeditor von tutorialspoint
- Kopieren sie den JSON-Code vom obigen Beispiel in das Editorfenster (links)
- Studieren sie die angezeigte Baumhierarchie des Datensatzes (rechts)
- Sie können die einzelnen Knoten aufklappen und schließen, um die Hierarchie zu erkunden
Welche Rückschlüsse können sie aus den GRAUEN Infos an den einzelnen Knoten ziehen?
- in geschweiften Klammern werden die Anzahl der Schlüssel-Wert-Paare angezeigt, also die Anzahl der Einzelinformationen im entsprechenden (Teil)Datensatz
- in eckigen Klammern wird die Anzahl der Elemente in einer Liste angezeigt
XML
Die Extensible Markup Language (XML) ist ein weiteres hierarchisches Datenformat, das für die Repräsentation von strukturieren, hierarchischen Daten geeignet ist. Ähnlich wie in HTML werden Informationen in sogenannten Tags gespeichert, wobei in XML die Schlagwörter frei festgelegt werden können. So könnten wir unseren JSON Datensatz wie folgt in XML ablegen.
XML
<?xml version="1.0"?>
<termine>
<termin>
<Nr>1</Nr>
<Tag>Mo</Tag>
<Ort>Zoom</Ort>
</termin>
<termin>
<Nr>8</Nr>
<Tag>Di</Tag>
<Ort></Ort>
</termin>
</termine>Im Gegensatz zu JSON gibt es somit keine “unbenannten” Daten, da alle
Information in Tags eingeschlossen werden muss, die durch spitze
Klammern <> gekennzeichnet sind. Die führende Zeile
<?xml version="1.0"?> gibt die Version des
XML-Formats an, die in diesem Fall 1.0 ist, und zeigt beispielhaft, wie
in XML Metadaten etc. eingebettet werden können.
Da jede Information auch wieder mit einem schließenden Tag beendet werden muss, sind XML Kodierungen meist umfangreicher als JSON, was die Lesbarkeit und die Dateigröße beeinflußt. Allerdings erlaubt XML auch die Definition von Attributen, die zusätzliche Informationen zu den Tags enthalten können. Dies kann insbesondere bei der Speicherung von Metadaten oder anderen Informationen hilfreich sein, die nicht direkt in den Tags gespeichert werden sollen.
Vordefinierte Schemata wie DTD (Document Type Definition) oder XSD (XML Schema Definition) können verwendet werden, um die Struktur der XML-Datei festzulegen, die Validierung zu erleichtern und einheitliche Standards zum Datenaustausch zu ermöglichen. Ein Beispiel hierfür ist der TEI (Text Encoding Initiative) Standard für Textrepräsentation.
Versuchs mal …
Es gibt auch einen XML-Onlineeditor von tutorialspoint. Öffnen sie diesen und kopieren sie das obige XML in die linke Editormaske.
Was unterscheidet das XML Rendering (rechts) vom JSON Rendering aus der letzten Aufgabe oben?
- es gibt keine explizite Unterscheidung in Datensätze und Listen
- alle Informationen werden gleich (als Text) behandelt und angezeigt (bei JSON gab es unterschiedliche Darstellungen)
- Textinformation (zwischen einschließenden Tags) wird nicht
“gequotet”, d.h. es sind keine Anführungszeichen nötig!
Ausnahme sind “Attribute” der Tags, wie die Versionsinformation im
Beispiel. Tauschen sie mal
<termine>durch<termine info="meine Liste">aus…
Auch für XML gilt, dass dieses i.d.R. automatisiert als Datenformat erzeugt wird und nur in seltenen Fällen komplett manuell erfaßt wird. Allerdings ist es, im Vergleich zu JSON, einfacher menschenlesbar, da alle Elemente eindeutig mit Tags benannt und begrenzt sind.
YAML
YAML (YAML Ain’t Markup Language) ist ein weiteres hierarchisches Datenformat, das für die Repräsentation von strukturierten Daten geeignet ist. Es ist eine menschenlesbare Auszeichnungssprache, die sich durch ihre einfache Syntax und Lesbarkeit auszeichnet. YAML wird häufig für Konfigurationsdateien oder Metadaten verwendet. Für die Datenrepräsentation ist es jedoch nur bedingt geeignet, da es keine Unterstützung für komplexe Datenstrukturen bietet und keine Validierung der Datenstruktur ermöglicht.
Ein Beispiel für die YAML-Repräsentation unseres JSON-Datensatzes könnte wie folgt aussehen:
YAML verwendet Einrückungen, um die Hierarchie der Daten
darzustellen, und verwendet Bindestriche -, um Listen zu
kennzeichnen. Für eine weiterführende, kompakte Einführung empfehlen wir
die Webseite
Bilder und Grafiken
Neben Text- und Tabellendaten sind auch Bilder und Grafiken wichtige Bestandteile von Forschungsdaten. Hierbei wird grundlegend in zwei Arten von Bildinformationen unterschieden, die sich in ihrer Darstellung und Verwendung wesentlich unterscheiden.
- Rastergrafiken bestehen aus einer “Tabelle” von Pixeln, d.h. Farbinformationen pro Bildposition, und sind insbesondere für Fotos und Bilder geeignet, die eher eine diffuse Farbgebung oder Detailgestaltung haben.
- Vektorgrafiken hingegen sind eher “Malanleitungen”, die beschreiben wo welche Bildelemente mit welcher Farbe, Form, etc. gezeichnet werden soll. Dies ist insbesondere für technische Zeichnungen, Diagramme und Schaubilder geeignet, da diese Form der Bildkodierung verlustfrei skaliert (“gezoomt”) werden kann.
Rastergrafiken
Dateiendungen:
-
.jpgoder.jpeg: JPEG (Joint Photographic Experts Group) - weit verbreitetes Format für Fotos und Bilder. ACHTUNG: verlustbehaftet, d.h. Abwägung zwischen Datenverlust und Dateigröße! -
.png: Portable Network Graphics - verlustfreies Format für Bilder, Diagramme und Grafiken -
.tifoder.tiff: Tagged Image File Format - verlustfreies Format für hochauflösende Bilder und Scans (vor allem für hochqualitativen Druck) -
.gif: Graphics Interchange Format - verlustfreies Format für Animationen und einfache Grafiken
Der zentralen Unterschied zwischen diesen Formaten ist die Art der Kompression und die damit verbundene Qualität der Bilder. Während JPEG-Dateien eine verlustbehaftete Kompression verwenden, die die Dateigröße reduziert, aber auch die Bildqualität beeinträchtigen kann, sind PNG- und TIFF-Dateien verlustfrei und eignen sich daher besser für die Speicherung von Bildern, bei denen die Qualität erhalten bleiben soll.
Daher sollte die Wahl des Dateiformats von der Art des Bildes und der beabsichtigten Verwendung abhängen. Für Fotos und Bilder, die auf Webseiten oder in Präsentationen verwendet werden, ist JPEG oft ausreichend, während PNG oder TIFF für hochwertige Drucke oder Grafiken bevorzugt werden sollten.

Vektorgrafiken
Dateiendungen:
-
.svg: Scalable Vector Graphics - XML Format für Grafiken und Diagramme (z.B. für Webseiten) -
.pdf: Portable Document Format - für Dokumente, kann aber auch Vektorgrafiken enthalten (z.B. für wissenschaftliche Publikationen) -
.eps: Encapsulated PostScript - für Druckgrafiken und technische Zeichnungen (eher veraltet) -
.ai: Adobe Illustrator (proprietär) -
.cdr: Corel Draw (proprietär)
Im Gegensatz zu Rastergrafiken wird in Vektorgrafiken nicht das finale Bild gespeichert, sondern eine Anleitung, wie das Bild zu zeichnen ist. Daher eigenen sich Vektorgrafiken besonders für technische Zeichnungen, Diagramme und Schaubilder, die klar definierte Formen und Linien haben und i.d.R. einheitliche Farbflächen verwenden. Jedem Bildelement (z.B. Linie, Kreis, Text) wird eine mathematische Formel zugewiesen, die die Position, Form des Elements beschreibt. Zudem kann für jedes einzelne Element die Farbe, Linienstärke, Füllung, etc. definiert werden, was eine hohe Flexibilität bei der Darstellung ermöglicht.
Da Vektorgrafiken nicht aus Pixeln bestehen, sondern aus mathematischen Formeln, können sie verlustfrei skaliert werden, d.h. sie können ohne Qualitätsverlust vergrößert oder verkleinert werden. Auch ermöglichen Vektorgrafiken häufig eine bessere Komprimierung, da die mathematischen Formeln weniger Speicherplatz benötigen als die Pixelinformationen von Rastergrafiken, sodass die Dateigröße von (einfachen) Vektorgrafiken i.d.R. kleiner ist. Auch ist es möglich, nur Ausschnitte von Vektorgrafiken zu verwenden, ohne dass die Qualität leidet.
Da Vektorgrafiken in der Regel in speziellen Programmen erstellt werden, sind die Dateiformate häufig proprietär und können nicht ohne weiteres von anderen Programmen geöffnet oder bearbeitet werden. Eine Ausnahme bildet das SVG-Format, das auf XML basiert und daher auch von anderen Programmen gelesen und bearbeitet werden kann. Das SVG-Format wurde speziell für das Web entwickelt und ist daher besonders für Webseiten geeignet. Hierbei können Vektorgrafiken direkt in den HTML-Code eingebunden werden und sind daher besonders für interaktive Grafiken und Diagramme geeignet, die mit Hilfe von JavaScript dynamisch verändert werden können (inhaltlich wie auch optisch). Aufgrund seiner Verbreitung und Flexibilität ist das SVG-Format sehr gut für den Datenaustausch und die Archivierung von Grafiken geeignet.
Für die Publikation von wissenschaftlichen Ergebnissen ist das PDF-Format besonders geeignet, da es sowohl Text als auch Vektorgrafiken und Rasterbilder enthalten kann, auf nahezu jedem Gerät geöffnet werden kann und für die einheitliche Darstellung auf allen Geräten entwickelt wurde. Zudem können PDF-Dateien mit Metadaten versehen werden, die Informationen über den Autor, das Erstellungsdatum, die Lizenz, etc. enthalten. Dies ist besonders wichtig für die Nachvollziehbarkeit und Zitierbarkeit von wissenschaftlichen Ergebnissen.
Schwierigkeiten mit digitalen Bildern
Rastergrafiken haben den Nachteil, dass sie bei der Vergrößerung an Qualität verlieren, da die Pixelinformationen interpoliert werden müssen, d.h. die Software muss die fehlenden Pixel “erraten” oder Zwischenwerte berechnen. Dies führt zu Unschärfe und Verzerrungen, insbesondere bei starken Vergrößerungen. Auch die Farbtiefe und Auflösung der Bilder beeinflussen die Qualität und Dateigröße, sodass eine Abwägung zwischen Qualität und Speicherplatzbedarf getroffen werden muss.

Vektorgrafiken sind hingegen nicht für alle Arten von Bildern geeignet, insbesondere für Fotos und Bilder mit komplexen Farbverläufen und Texturen. Hier sind Rastergrafiken besser geeignet, da sie die feinen Details und Farbnuancen besser darstellen können. Zudem werden Vektorgrafiken bei der Konvertierung in Rastergrafiken (z.B. für den Druck) in der Regel gerastert, d.h. in Pixel umgewandelt, was zu Qualitätsverlusten führen kann. Bei sehr komplexen Vektorgrafiken mit sehr vielen (überlappenden) Elementen kann die Dateigröße auch größer sein als bei vergleichbaren Rastergrafiken, da die mathematischen Formeln und die Vielzahl der Einzelelemente mehr Speicherplatz benötigen.
Zusammenfassung
- Standardisierte Dateiformate erleichtern den Datenaustausch und die
Archivierung von Daten.
- für Rohdaten und Publikation
- für Austausch mit Kollegen und der Öffentlichkeit
- i.d.R. textbasierte Formate (z.B. CSV, JSON, XML)
- Achtung: Kodierung von Zeichen und Zeilenumbrüchen beachten!
- meist “offen” und plattformunabhängig
- Proprietäre Dateiformate für internen Gebrauch und spezielle
Anwendungen/Software
- ermöglichen i.d.R. umfangreichere Informationsspeicherung und -darstellung
- können (für Austausch) in offene Formate konvertiert werden
- Wahl des Dateiformats u.a. abhängig von
- Art der Daten (z.B. Text, Bild, Video, Audio, ..)
- Verwendungszweck (z.B. Analyse, Publikation, Archivierung)
- Kompatibilität mit Software und Plattformen
- Dateiendungen
- sind nur ein Teil des Namens ohne weitere Auswirkungen
- ermöglichen dem Betriebssystem das richtige Programm zum Öffnen
auszuwählen
- Programmassoziation kann geändert werden!
Einordnung im Datenlebenszyklus
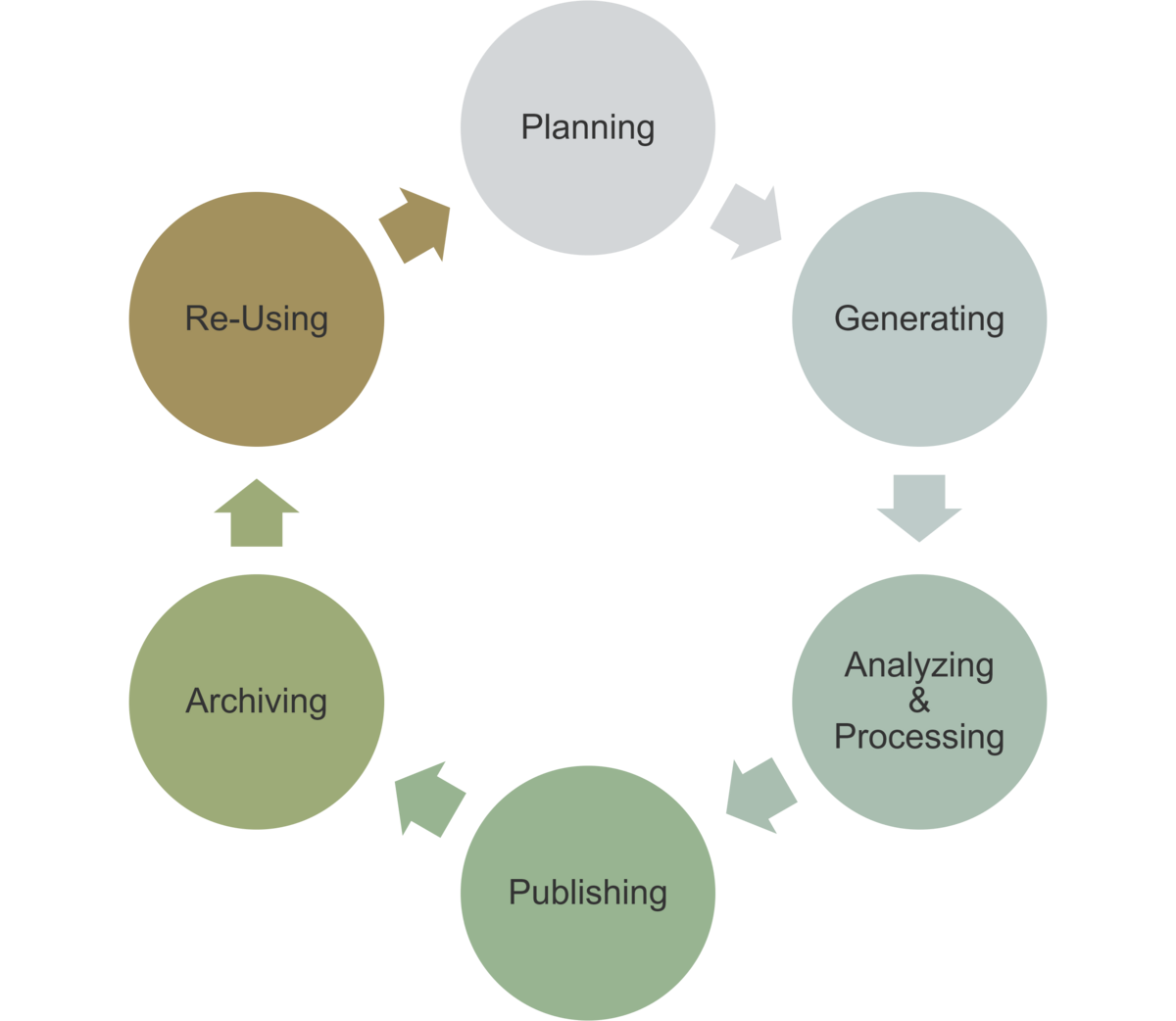
Die richtige Wahl des Dateiformats ist in allen Phasen des Datenlebenszyklus wichtig:
- Planung: Auswahl geeigneter Formate für die Datenerhebung, -analyse und -publikation
- Erhebung: Speicherung und Dokumentation der Daten
- Analyse: Verwendung von geeigneten Formaten für die Analyse (Skripte) und von Zwischenergebnissen (ggf. proprietäre Formate)
- Publikation: Bereitstellung der Daten in geeigneten Formaten
- Archivierung: Langzeitarchivierung in geeigneten Standardformaten
- Nachnutzung: Dokumentation; Auswahl von Formaten, die die eigene Nachnutzung erleichtern
Anwendungsaufgaben
- Sitzungsaufgabe “Strukturcheck von Dateien”
- Sitzungsaufgabe “Was für was?”
- Sitzungsaufgabe “Einheitliche Dokumentation”
ggf. noch Aufgaben zu
- PDF editing
- Dateikonvertierung
Proprietär bedeutet, dass das Dateiformat von einem bestimmten Hersteller oder für dessen Programm entwickelt wurde und daher nur von diesem Programm oder von Programmen, die das Format kennen und unterstützen, gelesen oder verarbeitet werden können.↩︎
Quelle - B.K. Nielsen - Freron - 07.08.2024↩︎
Quelle - Chris Spann - Lumar - 07.08.2024↩︎
Quelle - F. Graf - wikipedia.de - 09.08.2024↩︎
Quelle - selfhtml.org - 12.09.2024↩︎
{kind=link}