Reguläre Ausdrücke
Zuletzt aktualisiert am 2025-04-17 | Diese Seite bearbeiten
Geschätzte Zeit: 50 Minuten
Übersicht
Fragen
- Was?
- Aufbau?
- Wo?
Ziele
- Verständnis was Reguläre Ausdrücke sind
- Wissen um die Elemente von Regulären Ausdrücken
- Anwendung von Regulären Ausdrücken
Reguläre Ausdrücke sind einer der Grundpfeiler für die komplexe Textdatenprozessierung. Mit diesen kann man mit wenig Aufwand
-
nach Vorkommen von Textmustern
suchen, um diese zu
- extrahieren,
- zählen, oder
- ersetzen (mit neuen Texten oder Teilen des alten Textes).
Dabei ist unter “Textmuster” nicht ein exaktes Wort oder dergleichen zu verstehen, sondern eine Suchkodierung, welche Variabilität zulässt.
Als Einsteig ein kleines Beispiel: Wir haben die folgenden Worte
| soll gefunden werden | soll nicht gefunden werden |
|---|---|
| Frida | Fritz |
| Erna | Hugo |
| Lisa | Lino |
Die einfachste (und am wenigsten flexible) Lösung wäre es, die gesuchten Worte alle als Alternativen hintereinander in einem regulärem Ausdruck aufzulisten:
- “
Frida|Erna|Lisa” = wobei “|” für ein “ODER” steht
Wenn man reguläre Ausdrücke baut, muss man genau schauen, was die gesuchten Wörter (oder Textpassagen) gemeinsam haben. In unserem Fall enden alle gesuchten Namen mit “a”, was wir verwenden können. Was davor für Buchstaben kommen (und wieviele), ist erst einmal unerheblich, um die Worte von den nicht gesuchten zu unterscheiden. Daher könnten wir folgendes verwenden:
- “
.*a” = wobei “.” für ein beliebiges Zeichen (Buchstabe, Ziffer, Leer-, Satzzeichen, …) steht und “*” für eine beliebige Anzahl (auch 0) des vorherigen Teils (also hier “.”)
Das funktioniert, liefert aber ggf. zu viel Variabilität, was ein häufiger Fallstrick bei regulären Ausdrücken ist. Sprich sie sind zu unkonkret. In unserem Fall passt der Ausdruck auch auf: “..a”, “lala”, “Hans-Anna”, … Sie sehen das Problem? Um dieses zu umgehen, könnte man folgende Sachen machen:
- “
.+a” = wir fordern mit “+”, dass vor dem “a” mindestens ein (beliebiger) Buchstabe ist - “
[a-zA-Z]+a” = wir geben in “[]” ganz genau an, welche Buchstaben wir erlauben (hier z.B. keine Umlaute)- mit Bindestrich “
-” können wir auch Reihen angeben, z.B. “[a-d]” = a, b, c oder d
- mit Bindestrich “
- “
\w+a” = dazu könnten wir auch eine vordefinierte character class (hier\wfür Wortbuchstabe) nehmen - “
[A-Z][a-z]*a” = mit “[A-Z]” sichern wir, dass der erste Buchstabe grossgeschrieben ist und anschliessend können (da “*”) nur Kleinbuchstaben in der Wortmitte sein - … und so weiter
Das Beispiel zeigt, dass reguläre Ausdrücke ganz allgemein
(“.*a”) oder sehr präzise (“Frida|Erna|Lisa”)
sein können. Die Kunst ist es nun, den für die anstehende Aufgabe
passenden regulären Ausdruck zu erdenken. Dazu hilft einem das
beiliegende Cheatsheet, welches man sicher auch in Zukunft immer wieder
heraus holen muss.
Suche von Textmustern
Reguläre Ausdrücke werden von links nach rechts abgearbeitet und buchstabenweise abgeglichen (gematcht).
Zudem muss man wissen, dass i.d.R. das längste passende Textstück als Treffer gesucht wird. Man spricht hierbei von greedy matching.
Aufgabe
Öffnen sie den Online RegEx-Tester https://regex101.com/.
Kopieren sie die Namen aus obiger Tabelle in das Textfeld und prüfen sie, ob die bisher vorgestellten regulären Ausdrücke wirklich funktionieren.
Wichtig: Kopieren sie die regulären Ausdrücke ohne Anführungszeichen in das Suchfeld.
Ordnen sie die regulären Ausdrücke nach ihrer Spezifität (von allgemein nach spezifisch).
Ausdrücke in steigender Spezifität:
- “
.*a” (sehr allgemein, matched auch nur ein einzelnes “a”) - “
\w+a” (\wmatched auch Zahlen und Unterstriche) - “
[a-zA-Z]+a” (nur Buchstaben, keine Umlaute oder ß) - “
[A-Z][a-z]*a” (erst Grossbuchstabe, dann Kleinbuchstaben) - “
Frida|Erna|Lisa” (nur die drei Namen)
Aufbau
Reguläre Ausdrücke bestehen aus einer Aneinanderreihung von Elementen, die in einer bestimmten Reihenfolge stehen müssen. Das heißt, in den meisten Fällen beschreibt man ein Wort oder eine Wortgruppe, wobei einzelne Positionen unterschiedliche Buchstaben aufweisen können. An diesen Stellen kommen die sogenannten character classes ins Spiel, die Platzhalter für Buchstaben, Zahlen, Leerzeichen, … sind.
Damit nicht nur Wörter gleicher Länge mit einem Suchmuster gefunden werden, gibt es Quantifikatoren, die angeben, wie oft das vorherige Zeichen vorkommen soll (oder kann).
Zuletzt gibt es noch Anker, die eingrenzen, WO ein Suchmuster im Text vorkommen soll (z.B. am Anfang oder Ende eines Wortes oder der Zeile etc.).
Final können mit Gruppierungen auch Teile des gefundenen Textes extrahiert werden, um sie weiter zu verarbeiten oder um z.B. Wiederholungen im Textmuster zu beschreiben.
In normalen regulären Ausdrücken sind alle Buchstaben, die Teil des Suchmusters sind, auch Teil des Treffers/Matches. Mit Lookarounds können aber auch “Randbedingungen” definiert werden, die nicht Teil des Matches sind, aber dennoch erfüllt sein müssen. Zum Beispiel das vor einem Wort ein Leerzeichen oder Satzzeichen sein muss, aber dieses nicht Teil des Matches ist.
RegEx Magic
Die Kunst besteht nun darin, die richtigen Elemente in der richtigen Reihenfolge zu kombinieren, um das gewünschte Suchmuster zu beschreiben.
Hierbei sollte das Muster so allgemein wir nötig und so spezifisch wie möglich sein, um nur die gewünschten Treffer zu erhalten. Dies ist vor allem wichtig, wenn das Muster nur an einem kleinen Beispieldatensatz entwickelt, später aber auch auf andere Datensätze angewandt werden soll.
Elemente
Grundlegend unterscheidet man bei regulären Ausdrücken folgende Elemente:
-
character classes, d.h. Platzhalter die auf mehrere
Buchstaben matchen, z.B.
-
.= jedwedes Zeichen -
[xyz]= explizite Zeichenliste, hier “x”, “y” und “z”- auch Reihen möglich, z.B.
[3-7]= 3,4,5,6,7
- auch Reihen möglich, z.B.
-
\s= whitespaces = Platzhalter für alle unsichtbaren Zeichen, z.B. Leerzeichen, Tabulator, … -
\d= digits = Zahlen = [0-9] -
\w= (english) word = [A-Za-z0-9_] (keine Umlaute etc.!) -
Negation:
- Grossschreibung
\S,\D, .. = alles “ausser” den Zeichen der entsprechenden “kleinen Klasse”\s,\d, … -
[^xyz]= das^negiert die explizite Liste (alles ausser x,y,z)
- Grossschreibung
-
-
Quantifikatoren, d.h. wie häufig soll das
vorangehende Zeichen gematcht werden, z.B.
-
?= ein oder kein mal -
+= mindestens einmal -
*= kann mehrfach vorkommen oder gar nicht -
{..}= explizite Anzahl
-
-
Anker, d.h. wo soll der match verortet sein, z.B.
-
^= Zeilenanfang -
$= Zeilenende -
\b= Wortgrenze, z.B.er\bmatcht nur “er” am Wortende
-
-
Gruppen, d.h. Zusammenfassung von match-Teilen,
z.B.
-
(..)= Klammern werden nicht gematcht, sondern sind Markierungen - z.B. für lokale Alternativdefinition ala
(Hi|Ku)nz= Hinz oder Kunz -
\1Rückreferenzierung auf 1., 2., … vorangehende Gruppe- z.B.
(.).\1matcht aha, oho, ana, d.h. erster und letzter Buchstabe gleich
- z.B.
-
Neben den oben genannten RegEx-spezifischen
\..-Elementen gibt es auch immer noch einige Sonderzeichen
für die auch Escapes notwendig sind, z.B.
-
\tfür einen Tabulator -
\nfür Zeilenumbruch
Ausserdem müssen Zeichen, die in RegEx eine spezielle Bedeutung haben, auch escaped werden z.B.
-
\[für das normale[-Zeichen -
\\für das normale\-Zeichen -
\.für das normale.-Zeichen -
\+für das normale+-Zeichen - …
Tutorials
Wem das jetzt zu schnell oder kompakt war, oder wer noch etwas bei regulären Ausdrücken ins Schwimmen gerät, dem seien folgende Tutorials ans Herz gelegt:
- step-by-step Tutorial zu regulären Ausdrücken von regexone.com
RegEx Kreuzworträtsel
Zudem gibt es auch spielerische Ansätze, um das Lesen und Verstehen von regulären Ausdrücken zu üben.
Besuchen sie dazu die Seite:
Bis zu welchem Level kommen sie? 😎
CheatSheet
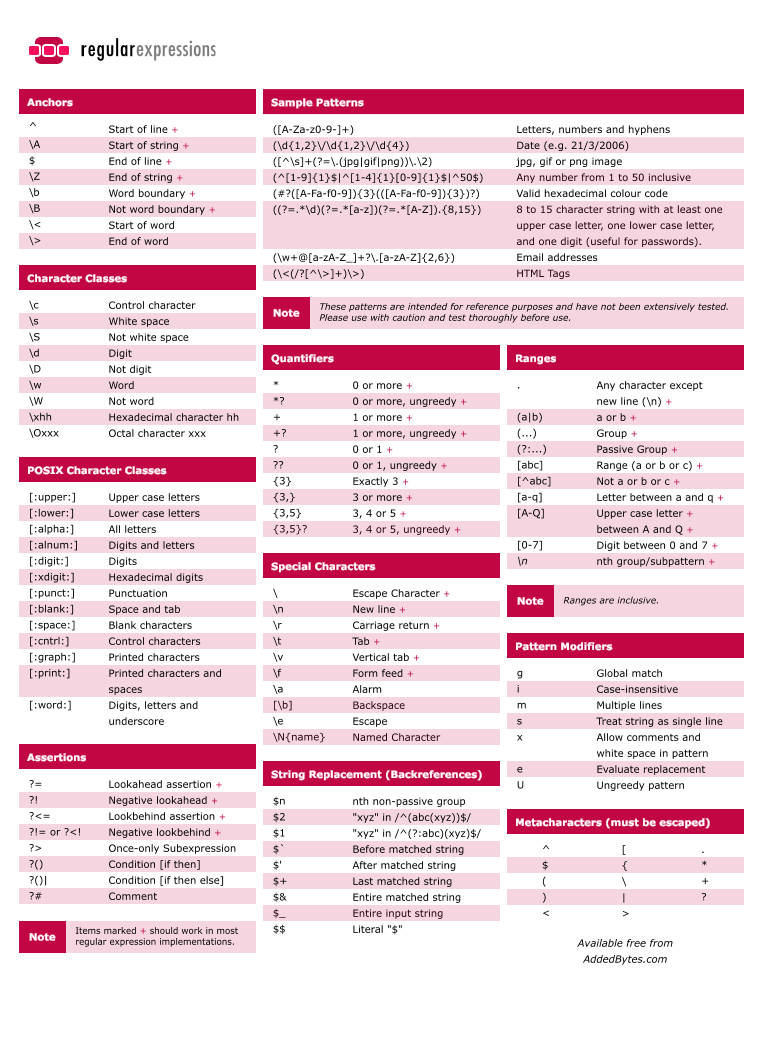 }
}Zusammenfassung
- Reguläre Ausdrucke kodieren Textsuchmuster mit
Variabilität in
- den vorkommenden Zeichen (positionsspezifisch)
- der Häufigkeit der Zeichen (oder Teilmuster)
- der Position des Musters im Text
- den flankierenden Texten
- Abwägung zwischen allgemein und spezifisch ist wichtig, je nach Einsatzzweck
- Cheatsheet der Elemente
Einordnung im Datenlebenszyklus
Reguläre Ausdrücke können immer dann von Nutzen sein, wenn Daten nach bestimmten Mustern oder Informationen durchsucht oder verändert werden sollen. Konkret wären folgende Phasen im Datenlebenszyklus denkbar:
- Planung: Suche nach geeigneten Daten und Dokumentationen
- Erhebung: Überblick und Validierung der Daten
- Analyse: Verarbeitung von Textdaten