Alles auf einen Blick
Content from Digitale Daten
Zuletzt aktualisiert am 2025-08-21 | Diese Seite bearbeiten
Geschätzte Zeit: 60 Minuten
Übersicht
Fragen
- Wie wird … gespeichert?
- Was gibt es für Probleme?
- Worauf muss man achten?
Ziele
- Verständnis wie verschiedene Informationstypen digital repräsentiert sind
- Wissen um die Grenzen und Schwierigkeiten von Informationsspeicherung
- Lösungsstrategien für häufige Daten(import)probleme
Grundlegende Formen von Information sind Texte, Zahlen, Zeiten, Farben (für Bild und Video) und Audio. Wenn wir an diese denken, haben wir meistens eine Vorstellung von einem physischen Medium wie einem Blatt Papier etc., auf dem diese gespeichert sind. Eine solche Form der Informationsspeicherung wird als analoge Speicherung bezeichnet.
In Computern wird Information in Form von digitalen Daten gespeichert. Digital bedeuted, vereinfacht gesagt, dass die Information in Form von Zahlen gespeichert wird, die wiederum in Form von elektrischen Signalen (z.B. “Strom an oder aus”) repräsentiert werden. Letzteres ist die Grundlage für die Funktionsweise von Computern.
Das bedeutet, dass alle Informationen, die wir in Computern speichern, in Form von Zahlen repräsentiert werden muss. Eine weitere wichtige Eigenschaft von digitalen Daten ist, dass sie in diskreten Einheiten gespeichert werden, also i.d.R. in Form von ganzen Zahlen.
Im Folgenden werden wir uns mit den verschiedenen Arten von Information und deren digitaler Repräsentation beschäftigen.
Text
Text ist die einfachste Form von digitalen Daten. Text wird in Computern in Form von Zeichenketten gespeichert, das heißt einer Abfolge von Zeichen. Jedes Zeichen wird dabei durch eine Zahl repräsentiert, wobei die Zuordnung von Zeichen zu Zahlen durch eine Zeichenkodierung festgelegt wird. Letztere ist eine Tabelle, die jedem Zeichen eine Zahl zuordnet.
Die bekannteste und eine der ersten ist die ASCII-Kodierung (American Standard Code for Information Interchange), welche 128 Zeichen umfasst und im Folgenden dargestellt ist.

Wenn wir die Tabelle betrachten, fällt uns auf, dass nicht nur Buchstaben oder Ziffern, sondern auch Sonderzeichen und Steuerzeichen (z.B. Zeilenumbruch) enthalten sind. Zudem fehlen Umlaute und Sonderzeichen, die in anderen Sprachen verwendet werden.
Daher wurden im Laufe der Zeit weitere Zeichenkodierungen entwickelt, die mehr Zeichen umfassen. Hier ein paar Beispiele:
- latin1 (ISO-8859-1): 256 Zeichen, enthält Umlaute und Sonderzeichen für westeuropäische Sprachen
- latin2 (ISO-8859-2): 256 Zeichen, enthält Umlaute und Sonderzeichen für osteuropäische Sprachen
- GB2312: 6.763 Zeichen, enthält chinesische Schriftzeichen
- UTF-8: 1.112.064 Zeichen, enthält fast alle Schriftzeichen der Welt
Hierbei ist zu beachten, dass die erweiterten Zeichenkodierungen rückwärtskompatibel sind, d.h. die Zahlen-Buchstaben-Kodierungen der ersten 128 Zahlen entsprechen i.d.R. der “alten” ASCII-Kodierungen.
Aktuell ist UTF-8 die am weitesten verbreitete Zeichenkodierung, da sie fast alle Schriftzeichen der Welt umfasst und daher für die meisten Anwendungsfälle geeignet ist. Diese Kodierung wird auch von den meisten neueren Betriebssystemen und Anwendungen standardmäßig verwendet.
Kodierungsprobleme
Was kann passieren, wenn ein Text mit latin1-Kodierung abgespeichert wird (also in Zahlen umgewandelt wird) und anschliessend mit latin2-Kodierung gelesen wird (also die Zahlen wieder mit Buchstaben ersetzt werden)?
Es werden falsche Zeichen angezeigt, da die Zahlen-Buchstaben-Zuordnung nicht übereinstimmt.
Das Problem mit den verschiedenen Zeichencodierungen ist, dass beim Öffnen einer Datei mit einer anderen Codierung als der, in der sie gespeichert wurde, die Zeichen falsch dargestellt werden. Daher ist es wichtig, die Codierung einer Datei zu kennen, um sie korrekt lesen zu können. Ein deutliches Zeichen, dass die falsche Codierung verwendet wird, ist, wenn anstelle von Umlauten oder Sonderzeichen nur Fragezeichen oder andere Zeichen angezeigt werden, wie in folgendem Bild.
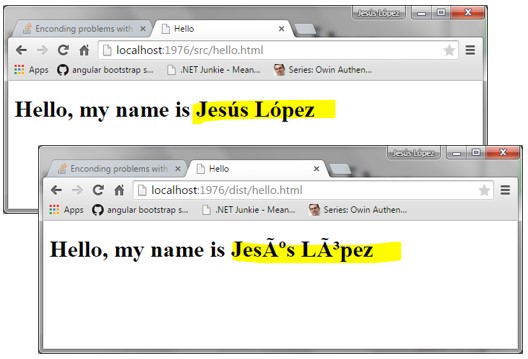
Dies tritt häufig auf, wenn man mit älteren Dateien arbeitet, was gerade im wissenschaftlichen Bereich in der Datennachnutzung von Daten immer wieder vorkommt.
Hinweis
In diesem Fall, muss man händisch die Codierung ändern, um den Text korrekt darzustellen. Hier bleibt häufig nichts weiter übrig, als die Codierung auszuprobieren, bis der Text korrekt dargestellt wird. Dabei ist es hilfreich, über den Ursprung der Datei Bescheid zu wissen.
Hier kommt wieder die Dokumentation von Daten ins Spiel!
Zeilenumbruch im Text
Ein weiteres Problem, das beim Lesen und Verarbeiten von Textdateien auftreten kann, ist der Zeilenumbruch, also das Zeichen, das angibt, dass eine neue Zeile beginnt. In aktuellen Betriebssystemen wird der Zeilenumbruch unterschiedlich abgespeichert:
-
Windows:
\r\n(zwei Zeichen: Carriage Return und Line Feed) -
Linux:
\n(ein Zeichen: Line Feed) -
MacOS:
\roder\n, je nach Alter des Betriebssystems (Carriage Return oder Line Feed)
Dies kann dazu führen, dass Textdateien auf einem Betriebssystem, auf dem sie nicht erstellt wurden, nicht korrekt dargestellt oder verarbeitet werden können.
Hinweis
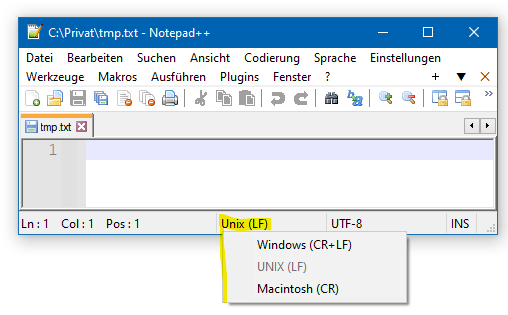
Texteditoren wie Notepad++ oder Visual Studio Code können automatisch die Zeilenumbrüche in Textdateien erkennen und korrekt darstellen. Auch ist es dort möglich, die Zeilenumbrüche in einem Textdokument zu konvertieren, d.h. von einem Format in ein anderes zu ändern.
Zahlen
Bei der Darstellung von Zahlen werden zwei Formen unterschieden: Ganzzahlen und Fließkommazahlen.
Ganzzahlen
Ganzzahlen, also 1, 13, 42, oder 987654321, werden in Computern durch ihre Zerlegung in 2er-Potenzen gespeichert. Zum Beispiel zerlegt sich 13 in 8+4+1, also 2^3 + 2^2 + 2^0. Im Computer selbst, können nur binäre Zustände, wie Strom an oder aus etc., gespeichert werden. Daher wird kodiert, ob eine 2er-Potenz in der Zahl enthalten ist oder nicht. Hieraus ergibt sich eine Binärdarstellung der Zahl. Im Beispiel der 13 also 1101, wobei die 1en die enthaltenen 2er-Potenzen repräsentieren und die Zahl wird (wie bei Dezimalzahlen auch) von rechts nach links gelesen, wobei die rechte Stelle 2^0 repräsentiert. Somit entspricht die Binärdarstellung 1101 der Dezimalzahl 13, da 2^3 + 2^2 + 2^0 = 8 + 4 + 1 = 13. Dies erlaubt die Speicherung beliebiger Ganzzahlen, solange genügend 2er-Potenzen zur Verfügung stehen, welche durch die maximale Länge der Binärdarstellung begrenzt ist.
Text => Ganzzahl => Binär
Da jedem Buchstaben über die Zeichenkodierung eine Zahl zugewiesen wird, und Ganzzahlen in Binärzahlen umgewandelt werden können, kann auch ein Text in Binärzahlen umgewandelt und gespeichert werden.
Binärzahlen
Normalerweise werden Zahlen in Dezimaldarstellung verwendet, also mit den Ziffern 0-9. Zahlen werden von rechts nach links gelesen, wobei jede Stelle eine 10er-Potenz repräsentiert und die Ziffer der jeweiligen Stelle der Faktor der entsprechenden 10er-Potenz ist. Hier ein Beispiel zur Illustration:
312 = 300 + 10 + 2= 3*100 + 1*10 + 2*1 = 3*10^2 + 1*10^1 + 2*10^0 = 312Binärzahlen hingegen verwenden nur die Ziffern 0 und 1, folgen ansonsten aber den gleichen Regeln wie Dezimalzahlen. Sie werden also auch von recht nach links gelesen, wobei jede Stelle eine 2er-Potenz repräsentiert und die Ziffer der jeweiligen Stelle der Faktor der entsprechenden 2er-Potenz ist. Hier ein Beispiel zur Illustration:
1101 = 1*2^3 + 1*2^2 + 0*2^1 + 1*2^0 = 8 + 4 + 0 + 1 = 13Wie auch bei Dezimalzahlen werden führende 0en meistens weggelassen, da sie keinen Einfluss auf den Wert der Zahl haben. Zudem können auch Binärzahlen addiert, subtrahiert, multipliziert und dividiert werden.
Die Binärdarstellung von Zahlen ist in der Informatik von großer Bedeutung, da sie die Grundlage für die digitale Speicherung und Verarbeitung von Zahlen in Computern bildet.
Frage
Welche Dezimalzahl repräsentiert die Binärzahl 1010?
Die 2er-Potenzen sind
- 2^0 = 1
- 2^1 = 2
- 2^2 = 4
- 2^3 = 8
Die Binärzahl 1011 entspricht der Dezimalzahl 10, da
1*2^3 + 0*2^2 + 1*2^1 + 0*2^0 = 8 + 0 + 2 + 0 = 10.Bits und Bytes
Einzelne “01 Ziffern” einer Binärzahl werden bit genannt, was für “binary digit” steht.
Kolonnen von 8 Bits werden Byte genannt, was für “by eight” steht.
Ein Byte kann also 256 verschiedene Werte annehmen, da 2^8 = 256 verschiedene 01 Kombinationen mit 8 Stellen möglich sind.
Um Daten im Computer speichern, verwalten und abrufen zu können, ist es unumgänglich schon im Vorfeld zu wissen, wie viele Bits und Bytes für die jeweilige Information verwendt wurde. Andernfalls könnten zu wenige oder zuviele Bits gelesen werden, was zu einem falschen Ergebnis führen würde. Oder noch schlimmer: Datenoperationen überlappen, das heisst das Speichern einer Information überschreibt (ggf. auch nur teilweise) eine andere Information.
Um dies zu vermeiden und die Datenintegrität zu gewährleisten, wurden Standards festgelegt, welche die Anzahl der Bits und Bytes für verschiedene Datentypen festlegen. Hier ein paar Beispiele:
- int (Integer): 4 Bytes (32 Bit)
- long (Long Integer): 8 Bytes (64 Bit)
- char (Character): 1 Byte (8 Bit)
- float: 4 Bytes (32 Bit) - für Gleitkommazahlen
- double: 8 Bytes (64 Bit) - für Gleitkommazahlen
Um negative Zahlen darstellen zu können, wird in der Regel das erste Bit als Vorzeichenbit verwendet. Dieses schränkt die Anzahl der darstellbaren Zahlen ein, da nur noch 7 Bit (bzw. 1 Bit weniger) für die eigentliche Zahlenrepräsentation zur Verfügung stehen.
Überlaufproblem
Da die Anzahl der Bits, die zur Speicherung einer Zahl zur Verfügung stehen, begrenzt ist, kann es zu einem Überlauf kommen. Ein Überlauf tritt auf, wenn das Ergebnis einer Berechnung mehr Stellen benötigt als die maximale Anzahl an Bits, die zur Speicherung zur Verfügung stehen. Hierbei werden die führenden Stellen einfach abgeschnitten, was zu einem falschen Ergebnis führt.
Beispiel unter der Annahme von 3 Bit Zahlendarstellung:
7 + 3 = 111 + 011 = (1)010 (Dezimalzahl 10, aber 4 Bit nötig und nur 3 vorhanden > Überlauf)
= 010 (auf letzte 3 Bit reduzierte Speicherdarstellung)
= 2 (entsprechende Dezimalzahl, falsches Ergebnis)Diese Problem ist heutzutage jedoch durch die Verwendung von 32 oder 64 Bit Zahlen in modernen Computern nur noch selten relevant.
Fließ- oder Gleitkommazahlen
Kommazahlen wie 0,0012 können auf verschiedene Arten geschrieben werden, z.B.
- als Bruch 12/10000
- als Dezimalzahl 0,0012
- als wissenschaftliche Notation 1.2e-3 oder 1.2E-3
Die wissenschaftliche Notation kann auf zwei Arten interpretiert werden. Zum einen als mathematische Formel “1,2 * 10^-3 = 1,2 * 0,001 = 0,0012”. Alternativ kann auch herauslesen, dass das Komma in der Zahl 1.2 um 3 Stellen nach links verschoben werden muss, um die eigentliche Zahl 0,0012 zu erhalten.
Letztere Interpretation ist die, die in Computern verwendet und als Gleit- oder Fließkommazahl bezeichnet wird. Hierbei wird die Zahl in zwei Teile zerlegt: die Mantisse und den Exponenten. Die Mantisse enthält die eigentliche Zahl, also 1.5, 3.14159, oder 42.0, und der Exponent gibt (vereinfacht gesagt) an, um wie viele Stellen das Komma nach links oder rechts verschoben werden muss, um die eigentliche Zahl zu erhalten. Der Trick ist nun, dass sowohl Mantisse als auch Exponent als Ganzzahlen gespeichert werden können, für die wir schon eine Umrechnung in Binärzahlen kennen.
Dies funktioniert sehr gut für Zahlen, die sich als Potenzen von 10 darstellen lassen, wie 0,0012 = 1.2 * 10^-3. Für Zahlen, die sich nicht als Potenzen von 10 darstellen lassen, wie 1/3 = 0.3333333333333333…, kann es zu Rundungsfehlern kommen, da der Computer nur eine begrenzte Anzahl von Stellen für die Mantisse und den Exponenten speichern kann, da beide als Ganzzahl mit festen Bit-Anzahlen gespeichert werden. Dadurch ergeben sich Rundungsfehler, da nicht jede Zahl exakt als Gleitkommazahl darstellbar ist. Diese anfängs ggf. sehr kleinen Fehler können sich in nachfolgenden Rechenschritten stark bemerkbar machen, sodass man diese kennen sollte.
Für weitere Details empfehlen wir die Seite Gleitkommadarstellung / Gleitkommazahlen aus dem Elektronik Kompendium.
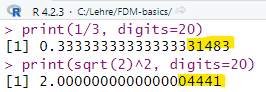
Rundungsfehler beim Rechnen mit Fließkommazahlen
Da der Computer nur eine begrenzte Anzahl von Stellen für die Mantisse und den Exponenten speichern kann, kann es zu Rundungsfehlern kommen, wenn mit Fließkommazahlen gerechnet wird. Hier ein Beispiel unter Verwendung der Programmiersprache R.
Frage
Überlegen sie, wo derartige Rundungsprobleme zu Problemen führen könnten, sodass in diesen Bereichen mit anderen Datentypen gearbeitet werden sollte.
Ein Beispiel für ein Problem, bei dem Rundungsfehler zu Problemen führen können, ist die Berechnung von Zinsen.
Auch z.B. zur Berechnung von Marsmissionen oder anderen wissenschaftlichen Berechnungen, bei denen sehr genaue Ergebnisse erforderlich sind, werden andere Datentypen bzw. mathematische Tricks verwendet.
Sprachabhängige Zahlendarstellung
Ein häufiges Problem bei der Verarbeitung von Zahlen ist die sprachabhängige Darstellung von Zahlen. In Deutschland (und vielen Ländern Westeuropas) wird die Zahl 1000 als 1.000,00 geschrieben, während in den USA die gleiche Zahl als 1,000.00 geschrieben wird.
Das heisst das verwendete Trennzeichen für die “Nachkommastellen” und die Tausenderstellen ist unterschiedlich bzw. umgekehrt.
Solange Zahlen direkt in Binärform gespeichert und eingelesen werden, ist dies kein Problem, da nur die Darstellung der Zahl, nicht aber die Zahl selbst, von der eingestellten Benutzersprache abhängt.
Sobald jedoch Zahlen in Textform eingelesen oder ausgegeben werden, kann es zu Problemen kommen, wenn die Zahlen in einem anderen Format gespeichert sind, als das, in dem sie eingelesen werden sollen.
Wenn sie z.B. eine Datei mit der amerikanischen Notation 1,000 mit einer “deutschen” Software einlesen, wird die Zahl als 1 gelesen, da die deutsche Software das Komma als Dezimaltrennzeichen interpretiert.
Hinweis
Wenn sie fremde textbasierte Daten einlesen, sollten sie diese immer auf das verwendete Zahlenformat überprüfen, um sicherzustellen, dass die Zahlen korrekt eingelesen werden.
Alle Textdatenimportfunktionen in Programmiersprachen (wie Python oder R) und Datenverarbeitungssystemen (wie MS Excel) bieten die Möglichkeit, das zu importierende Zahlenformat anzugeben, um solche Probleme zu vermeiden.
Aber sie selbst müssen daran denken!
Allgemeine Empfehlungen zur Rundung in wissenschaftlichen Arbeiten
Messgenauigkeit beachten
Runden sie nicht auf mehr Stellen, als die Messinstrumente oder Datenquellen hergeben.
Beispiel: Wenn ein Messgerät nur auf 0,1 genau ist, sollte man nicht auf 0,01 runden.-
Typische Rundungen nach Kontext
- Statistische Kennzahlen (Mittelwert, Standardabweichung): meist 2 Dezimalstellen
- Prozentwerte: oft 1 oder 2 Dezimalstellen
- Währungsangaben: 2 Dezimalstellen
- Physikalische Größen: abhängig von der Einheit und Genauigkeit, oft 2–3 Dezimalstellen
- Wissenschaftliche Notation: z. B. \(3.14 × 10^5\), oft 3 signifikante Stellen
-
Signifikante Stellen statt feste Dezimalstellen
In vielen naturwissenschaftlichen Bereichen wird nach signifikanten Stellen gerundet, nicht nach Dezimalstellen.
Beispiel:-
12345→ wenn 1 signifikante Stelle: \(1 × 10^4\)
-
12345→ wenn 3 signifikante Stellen: \(1.23 × 10^4\) - Signifikanz ergibt sich hierbei aus
- der Messgenauigkeit der Datenquelle
- der Relevanz für die Analyse
- der Konvention im jeweiligen Fachgebiet
- der Vergleichbarkeit mit anderen Daten, z.B. bei Daten aus verschiedenen Quellen die gleiche Anzahl an signifikanten Stellen verwenden
-
Konsistenz ist wichtig
In Tabellen oder Diagrammen sollten alle Werte gleich gerundet sein, um die Lesbarkeit zu verbessern.
Zeit
Die Zeit wird in Computern als Anzahl von (Milli)Sekunden seit einem festgelegten Zeitpunkt gespeichert.
Dieser Zeitpunkt ist in der Regel der 1. Januar 1970 um 00:00:00 Uhr (UTC), auch als Unix-Zeit bekannt. Diese Darstellung hat den Vorteil, dass die Zeit als Ganzzahl gespeichert werden kann, was die Speicherung und Verarbeitung vereinfacht und Rundungsfehler vermeidet.
Jahr-2038-Problem
Ein Problem bei der Speicherung von Zeit als Ganzzahl ist das Jahr-2038-Problem. Lesen sie diesen Wikipedia-Artikel und erklären sie, warum es auftritt und welche Auswirkungen es haben könnte.
Das Jahr-2038-Problem tritt auf, weil die Unix-Zeit als vorzeichenbehaftete 32-Bit-Ganzzahl gespeichert wird.
Das heisst nicht alle 32 Bit sind für die Zahl selbst reserviert, sondern das erste Bit gibt das Vorzeichen an. Da die Unix-Zeit den 1. Januar 1970 als Nullpunkt hat, wird die Zeit in Sekunden seit diesem Zeitpunkt gespeichert. Da eine 32-Bit-Ganzzahl nur 2^32 = 4.294.967.296 verschiedene Werte speichern kann, wird die Unix-Zeit am 19. Januar 2038 um 03:14:07 Uhr UTC den Wert 2.147.483.647 erreichen. Da die Unix-Zeit als vorzeichenbehaftete Ganzzahl gespeichert wird, wird der Wert am 19. Januar 2038 um 03:14:07 Uhr UTC auf -2.147.483.648 springen, was zu einem Überlauf führt. Dieser Überlauf führt dazu, dass die Zeit wieder bei -2.147.483.648 beginnt, was dem 13. Dezember 1901 um 20:45:52 Uhr UTC entspricht.
Farben
Farben werden in Computern z.B. als RGB-Werte gespeichert, also als Kombination von Rot-, Grün- und Blauanteilen des jeweiligen Lichtes. Jeder dieser Anteile wird als Zahl zwischen 0 und 255 gespeichert, wobei 0 für keinen und 255 für den maximalen Anteil des jeweiligen Farbtons steht. Das es sich um “Lichtfarben” handelt, wird somit die Farbe Weiß als (255, 255, 255) und die Farbe Schwarz als (0, 0, 0) gespeichert.
Da es sich um Ganzzahlen handelt, können diese auch in Binärform gespeichert werden, wobei die 8 Bit für jeden Farbton die Binärdarstellung der Zahl zwischen 0 und 255 darstellen. Aufgrund der diskreten Werte für die Farbanteile sind Farbverläufe nicht stufenlos sondern nur in diskreten Schritten möglich.
Neben RGB gibt es auch andere Farbmodelle, wie z.B. CMYK (Cyan, Magenta, Yellow, Key) für den Druck oder HSV (Hue, Saturation, Value) für die Farbdefinition. Auch hier werden die Farben als Zahlen gespeichert, wobei die Umrechnung zwischen den verschiedenen Farbmodellen durch mathematische Formeln erfolgt.
Farbkodierung liefert die Grundlage für Bild- und Videodaten, die selbst wieder in verschiedensten Formaten gespeichert werden können.
Frage
Wenn sie im Farbkasten Rot, Grün und Blau mischen, entsteht i.d.R. nicht weiß, sondern ein Braunton. Warum ist das so?
Die Farben im Farbkasten sind Pigmente, die das Licht absorbieren und nur bestimmte Farben reflektieren. Wenn sie Rot, Grün und Blau mischen, absorbieren sie fast alles Licht, sodass die Mischung dunkel erscheint.
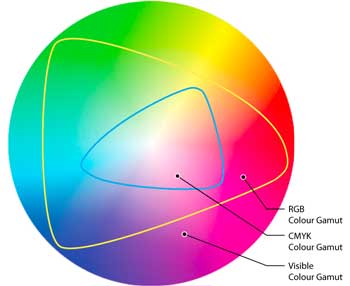
In folgendem Bild sehen sie, dass die unterschiedlichen Farbmodelle nur Teile des vom Menschen sichtbaren Farbraums abdecken.
Hinweis
Die Diskretisierung der Farbwerte kann zu Farbverlust führen, wenn die Farben in einem anderen Farbmodell gespeichert und wieder in RGB umgewandelt werden.
Daher sollte die Umwandlung zwischen den Farbmodellen nur dann erfolgen, wenn es unbedingt notwendig ist, am besten nach der Bildbearbeitung.
Für weiterführende Informationen rund um die Farbmodelle RGB und CMYK, ihrer Unterschiede und Umwandlung empfehlen wir folgende Seite.
Audio
Auch Audiodaten werden als Zahlen gespeichert, wobei die Amplitude des Schallsignals als Zahl gespeichert wird. Die Amplitude wird in der Regel als Zahl zwischen -1 und 1 gespeichert, wobei -1 für den minimalen und 1 für den maximalen Schalldruck steht. Da es sich um eine kontinuierliche Größe handelt, wird die Amplitude in der Regel als Gleitkommazahl gespeichert, um eine möglichst genaue Repräsentation des Schallsignals zu erhalten.
Zusammenfassung
- Jedwede Information wird i.d.R. durch Ganzzahlen repräsentiert
- Text via Zeichenencodingstabellen
- Gleitkommazahlen z.B. durch Mantisse und Exponent
- Zeit z.B. als Anzahl von Sekunden seit einem festgelegten Zeitpunkt
- Farben z.B. durch RGB-Werte
- Ganzzahlen können in Binärform gespeichert und verarbeitet werden
- dabei in 2er-Potenzen zerlegt
- Interpretation analog zu Dezimalzahlen (rechts nach links, …)
- Bit = eine “Ziffer” einer Binärzahl (0 oder 1)
- 8 Bit = 1 Byte
- Anzahl der Bits bestimmt die maximal darstellbare Zahl (Überlaufproblem)
- Probleme digitaler Informationsrepräsentation
- Überlaufproblem bei zu großen Zahlen
- Diskretisierung von kontinuierlichen Größen
- Rundungsfehler bei Gleitkommazahlen
- Verlust von Genauigkeit bei zu kleinen/großen Zahlen
- Kodierungsprobleme bei Textimport
- Sprachabhängige Darstellung von Zahlen
- Unterschiedliche Zeichenencodings
- Zeilenumbrüche in Textdateien abh. vom Betriebssystem
- Farbmodelle decken nicht den gesamten Farbraum ab
Einordnung im Datenlebenszyklus
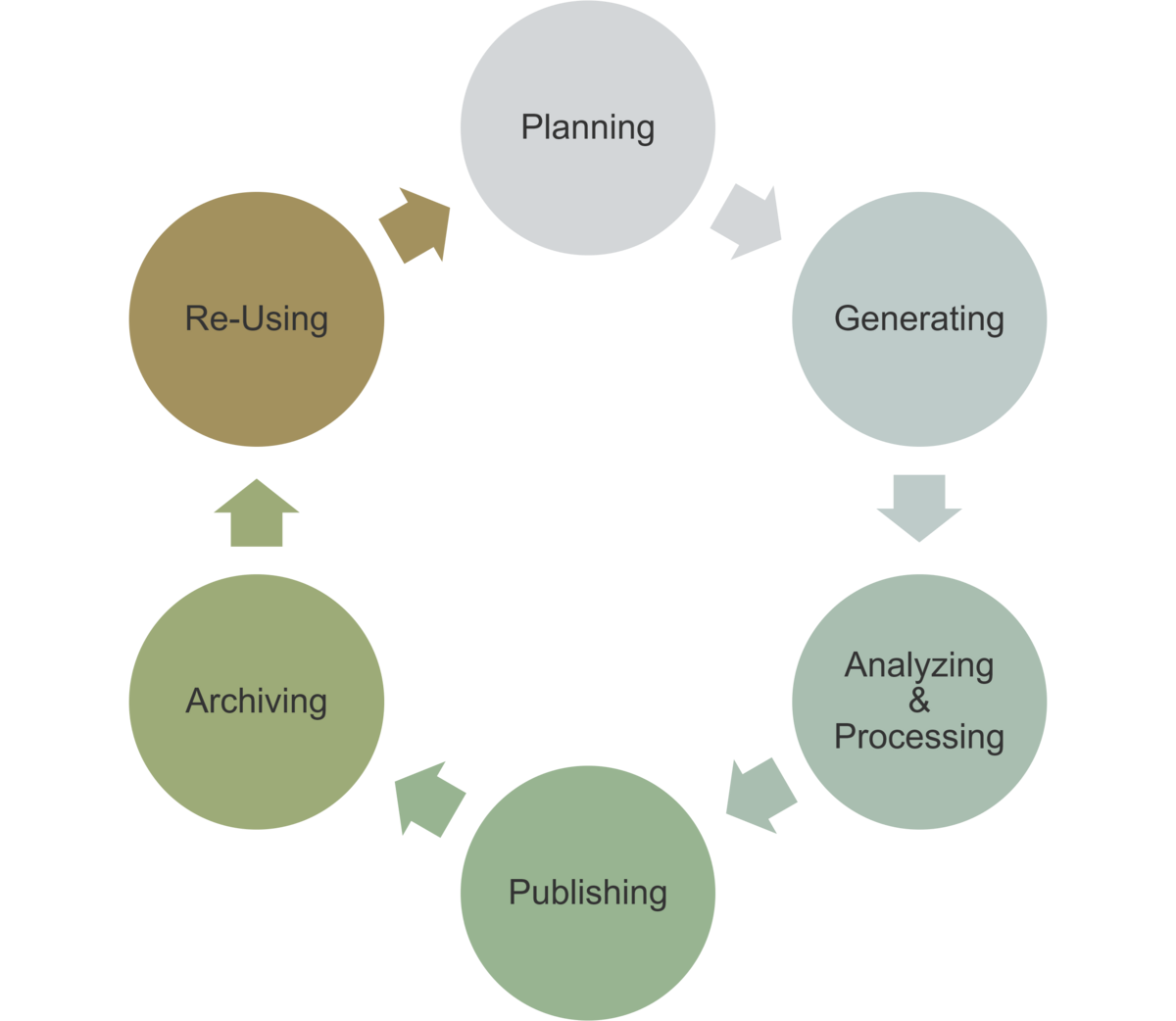
Das Wissen um die digitale Repräsentation von Informationen ist immer dann zentral, wenn Daten importiert oder exportiert werden, um sicherzustellen, dass die Daten korrekt übertragen und gespeichert werden.
- Planung: Festlegung von Datenformaten und -strukturen
- Erhebung: Korrekte Interpretation von Daten
- Archivierung: Export von Daten in geeigneten Formaten
- Nachnutzung: korrekter Datenimport und -export
Quelle - Wikimedia Commons - 07.08.2024↩︎
Quelle - aufkleberdrucker24.de - 12.09.2024↩︎
Content from Dateiformate
Zuletzt aktualisiert am 2025-08-21 | Diese Seite bearbeiten
Geschätzte Zeit: 40 Minuten
Übersicht
Fragen
- Binär vs. Text?
- Dateiformate?
- Was für was?
Ziele
- Verständnis dafür wie Daten gespeichert werden
- Wissen um gängige Dateiformate zur Datenhaltung
- Überblick welche Formate für welche Daten und Zwecke geeignet sind
Um Daten zu speichern oder weitergeben zu können, müssen sie in einer Datei abgelegt werden. Damit die Daten auch später wieder gelesen und verarbeitet werden können, muss dies in einer festgelegten Art und Weise geschehen, was durch das Dateiformat bestimmt wird. Damit man später noch weiss, welches Dateiformat verwendet wurde, wird dieses durch eine entsprechende Dateiendung (engl. file extension) hinterlegt. Die Dateiendung ist also lediglich ein Hinweis darauf, in welchem Format die Daten abgelegt sind, hat darüber hinaus aber keine weitere Bedeutung.
Binär vs. Text
Dateien können entweder in binärer oder Textform abgelegt werden. Dazu müssen wir uns erinnern, dass jedwede Information in einem Computer als Ganzzahl kodiert und diese in Binärzahlen, also einer Abfolge von Bits (0 und 1), repräsentiert und verwaltet werden.
Nun gibt es zwei Möglichkeiten, wie diese computerinterne Datenrepräsentation in einer Datei abgelegt werden kann.
Am kompaktesten und effizientesten ist es, die interne Binärdatendarstellung direkt als Binärdaten in einer Datei abzulegen, also als eine Abfolge von 0 und 1. Dieses wird als sogenannte binäre Datei bezeichnet. Dies hat den Vorteil, dass die Daten sehr schnell und effizient gelesen und geschrieben werden können, da keine Umwandlung notwendig ist. Allerdings sind binäre Dateien für Menschen nicht lesbar, da sie nur aus einer Abfolge von 0 und 1 bestehen, sodass keine Interpretation oder Inspektion der Daten möglich ist. Zudem sind binäre Dateien nicht oder nur bedingt portabel, da sie von der internen Datenrepräsentation des Computers und des verwendeten Anwendungsprogramms abhängen und daher nicht ohne weiteres auf anderen Systemen oder mit anderer Software gelesen werden können.
Daher werden binäre Dateiformate in der Regel nur für spezielle Anwendungen verwendet, bei denen es auf Geschwindigkeit und Effizienz ankommt, oder wenn die Daten nicht von Menschen gelesen werden müssen. Zudem sind binäre Dateiformate in der Regel spezialisiert und proprietär1, d.h. sie sind nur für bestimmte Anwendungen oder Programme geeignet und können nicht ohne weiteres von anderen Programmen gelesen oder verarbeitet werden.
Aufgrund dessen sind binäre Dateiformate in der Regel nicht für den allgemeinen Datenaustausch oder die Langzeitarchivierung geeignet.
Stattdessen werden Daten, die ausgetauscht oder archiviert werden sollen, in der Regel in Textform abgelegt. Hierbei werden die internen Binärdaten in eine menschlich lesbare Form umgewandelt, z.B. in Buchstaben, Zahlen oder Sonderzeichen, und als Text in einer Datei abgelegt. Dieser muss nicht zwingend in einer menschenlesbaren Form sein, sondern kann auch in einer maschinenlesbaren Form abgelegt werden, z.B. als strukturierte Daten oder in einer speziellen Syntax.
Grundlegend ist aufgrund der Textform jedoch gesichert, dass die Daten in einer Form abgelegt sind, die unabhängig von der computerinternen Datenrepräsentation ist und daher portabel und unabhängig von der verwendeten Software oder dem Betriebssystem ist.
Ist das binär oder textbasiert?
Um zu überprüfen, ob eine Datei binär oder textbasiert ist, können Sie die Datei einfach mit einem Texteditor öffnen. Dies ist mit jeder Datei möglich, unabhhängig von der Dateiendung oder dem Dateiformat!
Wenn die Datei text-basiert ist, können Sie den Inhalt lesen und bearbeiten. Falls nicht, wird der Inhalt der Datei als unleserlicher Text oder als Zeichenfolge von Sonderzeichen angezeigt, wie in folgendem Beispiel.
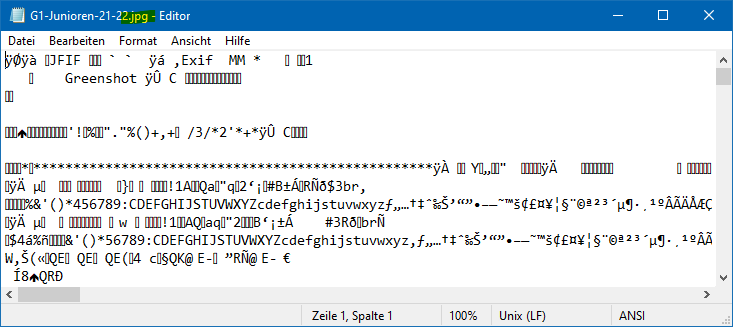
Sie sind dran ..
Öffnen Sie in einem Texteditor ihrer Wahl eine MS Excel Datei und eine PDF Datei.
Was sehen Sie? Sind die Dateiformate binär oder textbasiert?
Die Excel-Datei wird als unleserlicher Text oder als Zeichenfolge von Sonderzeichen angezeigt, da sie im binären XLSX-Format gespeichert ist. Letzteres ist eigentlich ein komprimiertes ZIP-Archiv, das verschiedene Dateien und Ordner enthält, die die Tabellenkalkulation und die Daten enthalten.
Die PDF-Datei wird je nach Inhalt als Mix aus lesbarem Text und Sonderzeichen angezeigt. Das PDF-Format ist ein Hybridformat, in dem bestimmte Inhalte (wie Bilder) in einem binären Format gespeichert sind, während der Text z.T. in einer menschenlesbaren Form abgelegt ist.
Doch dazu später mehr…
Standard vs. Spezialformat
Die Wahl des Dateiformats hängt stark von der Art der Daten und ihrer Verwendung ab. Für den allgemeinen Datenaustausch und die Langzeitarchivierung sind Textformate in der Regel besser geeignet, da sie portabel, unabhhängig und zukunftssicher sind. Für den internen Gebrauch oder spezielle Anwendungen können jedoch auch binäre Formate sinnvoll sein, da sie schneller und effizienter sind und spezielle Funktionen oder Eigenschaften bieten können.
Daher sollten Rohdaten und Metadaten in einem Standardformat abgelegt werden, das von verschiedenen Programmen und Systemen gelesen und verarbeitet werden kann. Zudem sollten am Ende des Forschungsprozesses zur Publikation die finalen, verarbeiteten Daten in Standardformaten abgelegt werden, um die Nachnutzung und Langzeitarchivierung zu erleichtern.
Während des Forschungsprozesses können jedoch auch spezielle oder proprietäre Formate verwendet werden, um die volle Leistungsfähigkeit und Funktionalität der verwendeten Software auszuschöpfen.
Im Folgenden werden wir einige der gängigsten Dateiformate für den Datenaustausch und die Langzeitarchivierung vorstellen und ihre Verwendungszwecke und Eigenschaften erläutern.
Nur Text
Die einfachste Möglichkeit beliebige Information zu speichern ist in Form von unformatierten Textdateien. Diese enthalten nur eine texttuelle Repräsentation der Information in Form von Buchstaben, Zahlen und Sonderzeichen, und haben darüber hinaus keine spezielle Struktur oder Formatierung.
Derartige Dateien werden i.d.R. mit der Dateiendung
.txt versehen und können mit jedem Texteditor
geöffnet und bearbeitet werden. Hierbei ist zu beachten, das MS Word
oder andere Textverarbeitungsprogramme nicht als Texteditor
geeignet sind, da sie zusätzliche Formatierungen und Metadaten in die
Datei schreiben, die den reinen Textinhalt verfälschen.
Geeignete Texteditoren sind z.B.
- Notepad++ (Windows),
- TextEdit (Mac),
- gedit (Linux) oder
- Microsoft Windows Editor.
Wenn die Textdatei in einer strukturierten Form vorliegt, d.h. wenn die Information in Zeilen und Spalten organisiert oder durch spezielle Schlüsselwörter oder Trennzeichen strukturiert ist, dann spricht man von einem textbasiertem Dateiformat.
Formattierter Text
Markdown
Dateiendungen: .md,
.markdown
Markdown ist eine einfache Auszeichnungssprache für Textdateien. Das heisst, einzelne Textabschnitte können mit speziellen Zeichen oder Schlagworten versehen werden, um ihre Formattierung zu bestimmen. Die Formatierung selbst geschieht in einem nachfolgenden Verarbeitungsschritt, bei dem der formatierte Text in einem geeigneten Format, z.B. HTML, PDF, .., abgespeichert wird.
Studieren sie folgende Webseite, in der Markdown und seine Anwendungen erklär werden:
-
Markdown
Guide - Get Started (Englisch)
- oder in Deutsch via google.translate (mit einigen lustigen Übersetzungsartefakten …)
Da die Formatierung von Markdown immer in einem separaten Schritt erfolgt, ist es sinnvoll einen Editor zu verwenden, der die Formatierung in Echtzeit anzeigt. Im Rahmen des Kurses (und ggf. auch darüber hinaus) empfehlen wir daher den Onlineeditor dillinger.io, welcher ohne Registrierung oder Installation genutzt werden kann.
Challenge
Verwenden sie den Onlineeditor dillinger.io um ein einfaches Markdown-Dokument zu erstellen.
Versuchen sie darin einige der kleinen “Best Practice” Tipps, welche auf der Webseite Markdown Guide - Basic Syntax vorgestellt werden.
Markdown wird sehr häufig für Dokumentationen, Readme-Dateien und auch für einfache Webseiten verwendet. (Auch diese Webseite wurde basierend auf Markdown erzeugt!)
In diesem Kurs werden wir daher ab sofort Markdown für (fast) alle Dokumentationen verwenden, um dies zu üben.
Sie können daher dillinger.io schon direkt zu ihren Lesezeichen im Browser hinzufügen.
.md Dateiendung mit Texteditor
verknüpfen
Dateiendungen dienen vorrangig dazu, dass das Betriebsystem
automatisch erkennt, mit welchem Programm eine ausgewählte Datei
geöffnet werden soll. Für Markdowndateien mit der Dateiendung
.md ist in den meisten Betriebssystemen keine solche
Assoziation mit einem “Standardprogramm” direkt vorhanden. Daher sollte
diese eingerichtet werden, wenn man häufiger, wie in diesem Kurs, mit
Markdown Dateien arbeiten möchte.
Aufgabe:
- Exportieren sie ihre Markdown-Spielerei aus der letzten Aufgabe aus
dillinger.io heraus
- dazu oben rechts “Export as” > “Markdown” auswählen
- Speichern sie die Datei auf ihrem Computer an einem Ort ihrer Wahl (den sie wiederfinden…)
- Setzen sie als Standardprogramm zum Öffnen von Markdown-Dateien ihren Texteditor
- Versuchen sie nun die heruntergeladene Datei zu öffnen (z.B. via
Doppelklick)
- Ziel ist es, das nun ihr installierter Texteditor die Markdown-Datei anzeigt
HTML
Dateiendungen: .html,
.htm
Ähnlich wie Markdown ist auch HTML (HyperText Markup Language) eine Auszeichnungssprache, die zur Strukturierung von Texten in Webseiten verwendet wird. Im Gegensatz zu Markdown ist HTML jedoch deutlich komplexer und ermöglicht eine detaillierte Strukturierung und Formatierung von Texten und zusätzlichen Inhalten (z.B. Bilder, Videos, …). HTML-Dateien können mit jedem Texteditor geöffnet und bearbeitet werden, jedoch ist zur Anzeige der Formatierung ein Webbrowser erforderlich. Das heißt, analog wie bei Markdown, muss der HTML-Code erst durch ein Programm (i.d.R. dem Browser) interpretiert und dargestellt werden.

Webseiten bestehen aus einer Kombination von HTML, CSS und Javascript, wobei
- HTML die Struktur und den Inhalt der Seite definiert,
- CSS das Aussehen und die Formatierung steuert und
- Javascript die Interaktivität und Funktionalität hinzufügt.
Webseiten werden häufig zur Präsentation, Publikation oder Dokumentation von Forschung und deren Daten verwendet.
Aufgrund der zugrundeliegenden Struktur von HTML-Dateien, kann man teilweise auch direkt aus Webseiten die präsentierten Daten extrahieren. Dies nennt sich Web Scraping. Allerdings ist eine zusätzliche Bereitstellung der Daten in einem datenfokussierten Dateiformat (z.B. CSV, JSON) meist sinnvoller und empfohlen.
Das Portable Document Format (PDF) ist ein Dateiformat, das entwickelt wurde, um Dokumente unabḧängig von Anwendungen, Betriebssystemen oder Hardwareplattformen anzuzeigen und auszudrucken. Damit ist es möglich, Dokumente so zu speichern, dass sie auf jedem Gerät gleich aussehen, was bei Markdown und HTML nicht der Fall ist.
PDF-Dateien können Text, Bilder, Links, Formulare, Audio- und Videodateien enthalten und sind daher ein weit verbreitetes Format für die Präsentation und den Austausch von Dokumenten. Auch ist es möglich, die Bearbeitung, Druckbarkeit, … von PDF-Dateien zu beschränken, um die Integrität und Authentizität von Dokumenten zu gewährleisten. Allerdings sind diese Sicherheitsfeature nur bedingt wirksam und können durchaus umgangen werden.
PDF Dateien sollten für “Endprodukte” verwendet werden, die nicht mehr verändert werden sollen, z.B. für Berichte, Präsentationen, Publikationen, etc. Sie sind wenig geeignet für die Zusammenarbeit und Weiterverarbeitung von Daten, da sie nicht so einfach zu bearbeiten sind wie Textdateien oder textbasierte Dateiformate.
Fast alle Betriebssysteme beinhalten mittlerweile einen virtuellen “PDF Drucker”. Damit kann jedes Dokument, welches gedruckt werden kann, auch als PDF-Datei gespeichert werden.
Dies ist besonders nützlich, um Dokumente zu archivieren oder zu teilen, da PDF-Dateien auf den meisten Geräten und Betriebssystemen angezeigt werden können, ohne dass spezielle Software erforderlich ist.
Grundlegend kann (fast) jedes PDF-Dokument mit einem entsprechenden Editor (z.B. Adobe Acrobat oder verschiedenen Onlinetools) bearbeitet werden. Allerdings erfolgt die Bearbeitung in der Regel nicht im Quellcode, sondern in einer grafischen Benutzeroberfläche, da das PDF-Format einen Mix aus Text- und Binärinformationen enthalten kann.
PDF editieren
Nehmen sie ein beliebiges PDF-Dokument und versuchen sie es mit einem PDF-Editor zu bearbeiten. Hierfür finden sich auch zahlreiche kostenlose Online-Tools.
DOCX, ODT, …
Um formatierte Texte zu schreiben und zu speichern werden häufig Textverarbeitungsprogramme wie Microsoft Word, Google Docs oder LibreOffice Writer verwendet.
Häufige Dateiendungen für derartige Textverarbeitungsdateien sind:
-
.docx- Microsoft Word (von Microsoft entwickelter Standard) -
.odt- OpenDocument Text (quelloffener freier Standard)
Diese Dateiformate enthalten neben dem reinen Text auch Informationen zur Formatierung, Schriftart, Farben, Autor, … und können daher nicht direkt in einem Texteditor geöffnet und bearbeitet werden. Allerdings können sie in Textdateien (z.B. Markdown) oder PDF-Dateien konvertiert werden, um sie einfacher zu teilen oder zu archivieren.
Da diese Dateiformate proprietär sind, kann es zu Kompatibilitätsproblemen kommen, wenn sie von verschiedenen Programmen oder Versionen geöffnet werden. Das heißt, dass die Formatierung oder der Inhalt der Datei möglicherweise nicht korrekt angezeigt wird, wenn sie in einem anderen Programm geöffnet wird.
Daher wird empfohlen, für Dokumentationen und Texte, die geteilt oder archiviert werden sollen, stattdessen reine Textdateien, textbasierte Dateiformate oder PDF-Dateien zu verwenden.
Dokumentation in .md oder .docx?
Warum ist es besser, Dokumentationen und beschreibende Texte in Markdown-Dateien statt in Word-Dokumenten zu speichern?
- Plattformunabhängigkeit: Markdown-Dateien können auf jedem Betriebssystem und mit jedem Texteditor geöffnet und bearbeitet werden, während Word-Dokumente ein entsprechendes Textverarbeitungsprogramm benötigen.
- Versionierung: Markdown-Dateien können leichter in einem Versionskontrollsystem (z.B. Git) gespeichert und lokale Änderungen dokumentiert werden.
- Flexibilität: Markdown-Dateien können einfacher (automatisiert) in beliebige Formate (z.B. HTML, PDF) oder auch Präsentationsformen (Webseite, Buch, …) konvertiert werden.
Programmierskripte
Neben reiner Textinformation werden auch Programmierskripte in Textdateien abgelegt. Diese enthalten Anweisungen und Befehle, die von einem Computer ausgeführt werden können, um bestimmte Aufgaben zu erledigen. Die Skripte werden in einer Programmiersprache geschrieben, die speziell für die Erstellung von Programmen und Skripten entwickelt wurde. Zur Dokumentation und Weitergabe von (Forschungs)Daten ist es daher häufig wichtig, auch die verwendeten Programmierskripte zu speichern und zu teilen. Daher sollten sie gängige Programmiersprachen und -skripte kennen, um derartige Dateien identifizieren zu können.
Einige wichtige Dateiendungen für Programmierskripte sind:
-
.py- Python -
.R- R -
.js- Javascript -
.sh- Shell - Linux/MacOS Kommandozeile -
.bat- Batchskripte - MS DOS/Windows Kommandozeile -
.ps1- Powershellskripte - erweiterte MS Windows Kommandozeile
Markdown wird auch sehr häufig in Verbindung mit Programmiersprachen verwendet, um Codebeispiele und Dokumentationen zu erstellen. Zudem wurden “Hybridformate” entwickelt, die sowohl Markdown für Beschreibungen als auch direkt auszuführende Programmieranweisungen enthalten. Beispiele hierfür sind:
- Jupyter Notebooks (
.ipynb), - R Markdown (
.Rmd) oder R Notebooks (.Rnb).
Diese Formate ermöglichen es, Code und Dokumentation bzw. Interpretation in einem Dokument zu kombinieren und interaktiv auszuführen, was sie besonders für die Datenanalyse und -visualisierung geeignet macht. Zudem können sie in verschiedene Formate exportiert werden, z.B. als HTML, PDF oder Präsentation, was sie für die Veröffentlichung und den Austausch von Ergebnissen nützlich macht. Auch hier gilt, dass ggf. nicht nur das erzeugte finale Dokument, sondern auch das ursprüngliche Notebook gespeichert und geteilt werden sollte, um die Nachvollziehbarkeit und Reproduzierbarkeit der Analyse zu gewährleisten.
Tabellen
Dateiendungen:
- textbasierte Formate, z.B.
-
.csv- Comma Separated Values -
.tsv- Tab Separated Values
-
- binäre Formate, z.B.
-
.xls,.xlsx- MS Excel -
.ods- OpenDocument Spreadsheet
-
Bei der Datenerhebung, -verarbeitung oder zur -archivierung werden Daten häufig in tabellarischer Form gespeichert. Hierbei werden die Daten in Zeilen und Spalten organisiert, wobei in einzelnen Spalten nur Informationen der gleichen Form (Zahl, Text, ..) gelistet werden.
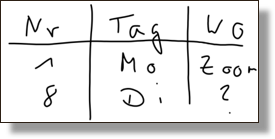
Tabellen können in textbasierten Formaten (z.B. CSV) oder binären Formaten (z.B. XSLX) digital gespeichert werden. Textbasierte Formate sind plattformunabhängig und können in jedem Texteditor geöffnet und bearbeitet werden, während binäre Formate spezifische Programme erfordern und ggf. zu Kompatibilitätsproblemen führen können. Zudem werden zur Verarbeitung von binären Formaten in Programmiersprachen häufig zusätzliche Funktionalitäten (Pakete) benötigt, was die Verwendung und Nachnutzung erschweren kann.
Eine der häufigsten Formen der tabellarischen Daten ist das CSV-Format (Comma Separated Values), bei dem die Daten durch Kommas getrennt in einer Textdatei gespeichert werden. Eine mögliche CSV-Repräsentation der obigen Tabelle ist wie folgt.
Nr,Tag,Wo
1,Mo,Zoom
8,Di,?Problematisch …
Welche Probleme sehen sie mit der obigen CSV-Kodierung der Tabelle? Was kann problematisch werden?
- Spaltentrennzeichen: Da es sich um einen deutschsprachigen Datensatz mit Zahlen handelt, kann es zu Problemen mit dem Spaltentrennzeichen “,” kommen, falls Dezimalzahlen z.B. “2,34” im Datensatz auftreten. In diesem Fall wäre es nicht eindeutig, ob das Komma ein Spalten- oder Dezimaltrennzeichen ist. Das gleiche Problem ergibt sich, wenn komplette Sätze (die potentiell Kommas enthalten) gespeichert werden. Daher hat sich im westeuropäischen Raum das Semikolon “;” als Trennzeichen etabliert (welches auch als CSV2-Format bezeichnet wird). Alternativ kann auch das TSV-Format verwendet werden, das Tabulatoren als Spaltentrenner verwendet.
-
Fehlende Daten: Hier wurden fehlende Daten mit
“
?” vermerkt. Während dies für menschliche Augen ein hilfreicher Hinweis sein kann, ist er für die automatische Datenverarbeitung schlecht geeignet. Wenn einzelne Daten fehlen, sollte in der jeweiligen Spalte einfach keine Information angegeben werden. In diesem Falle also besser “8,Di,”. - Textkodierung: Da der Datensatz Text enthält, können beim Import Probleme mit der Zeichenkodierung auftreten. Aktuell wird empfohlen UTF-8 zu verwenden.
Kommentare und Metadaten
CSV sieht i.d.R. keine Kommentare, Metadaten, etc. vor. Daher sollten
diese Informationen in einer separaten Datei oder in einem anderen
Format gespeichert werden. Falls unbedingt nötig, werden Kommentare in
CSV-Dateien i.d.R. in den ersten Zeilen gelistet und durch spezielle
Zeichen (z.B. #) am Anfang der Kommentarzeilen markiert.
Damit ist es möglich, diese beim Import zu überspringen oder zu
ignorieren
Hierarchische Daten
Dateiendungen:
-
.json- JavaScript Object Notation -
.xml- Extensible Markup Language -
.yaml- YAML Ain’t Markup Language
Eine Alternative zur tabellarischen Datenspeicherung bieten hierarchische Datenformate, die Informationen in einer verschachtelten Struktur speichern. Hierbei können Daten in beliebiger Tiefe und Komplexität organisiert werden, was sie besonders für die Speicherung von Metadaten oder strukturierten Daten geeignet macht. Zudem liefert diese Form der Datenrepräsentation direkt die Möglichkeit, Zusammenhänge und Beziehungen zwischen den Daten zu speichern.
JSON
JSON (JavaScript Object Notation) ist, wie der Name schon sagt, ein auf der Programmiersprache JavaScript basierendes Format, das Daten in einem hierarchischen Format speichert. Einzelne Datensätze werden wie folgt repräsentiert:
Hierbei werden die Daten in Doppelpunkt-getrennten
Schlüssel-Wert-Paaren gespeichert, wobei die Werte
beliebige Datentypen annehmen können (Zahlen, Text, Listen, …).
Datensätze selbst werden durch geschweifte Klammern {}
begrenzt, wobei die einzelnen Schlüssel-Wert-Paare durch Kommas getrennt
werden. Diese Struktur kann beliebig tief verschachtelt werden, um
komplexe Datenstrukturen abzubilden. In unserem Beispiel können wir die
Informationen für mehrere Treffen wie folgt speichern:
JSON
{
"Termine" : [
{
"Nr": 1,
"Tag": "Mo",
"Ort": "Zoom"
},
{
"Nr": 8,
"Tag": "Di",
"Ort": null
}
]
}Hierbei werden die einzelnen Treffen in einer Liste
Termine mit eckigen Klammern []
zusammengefaßt, welche wiederum die einzelnen Treffen als JSON-Objekte
enthält. Wichtig: die Liste selbst ist auch wieder ein JSON-Objekt, das
in geschweiften Klammern {} eingebettet wird (die “äußeren”
Klammern umfassen den Datensatz). Einrückung, Zeilenumbrüche und
Leerzeichen sind rein zur besseren Lesbarkeit erlaubt, können aber
weggelassen werden. Letzteres ist insbesondere bei großen Datenmengen
sinnvoll, um die Dateigröße zu reduzieren.
Beachten sie, dass es hier (im Gegensatz zu CSV) keine Probleme mit
dem Komma als Trennzeichen gibt, da die Daten in einem strukturierten
Format gespeichert sind. Zudem werden fehlende Daten durch
null repräsentiert, was der eindeutigen Information über
fehlende Daten in JavaScript Notation entspricht. Allerdings müssen, wie
in JavaScript, Textinformationen (sowie “Datennamen”) immer in
Anführungszeichen gesetzt werden, was die Lesbarkeit im Vergleich zu CSV
etwas erschwert.
JSON ist ein weit verbreitetes Format, das in vielen Programmiersprachen unterstützt wird und sich gut für den Datenaustausch zwischen verschiedenen Systemen eignet. Allerdings eignet es sich nur bedingt für die manuelle Bearbeitung durch Menschen, da es aufgrund der kompakten Strukturierung und der Anführungszeichen schnell unübersichtlich werden kann. Daher wird es i.d.R. automatisiert erzeugt oder in Kombination mit einem Editor oder einer speziellen Software verwendet, die die Strukturierung und Lesbarkeit der Daten verbessert, was wir im Folgenden ausprobieren werden.
JSON-Beispiel
- Öffnen sie den JSON-Onlineeditor von tutorialspoint
- Kopieren sie den JSON-Code vom obigen Beispiel in das Editorfenster (links)
- Studieren sie die angezeigte Baumhierarchie des Datensatzes (rechts)
- Sie können die einzelnen Knoten aufklappen und schließen, um die Hierarchie zu erkunden
Welche Rückschlüsse können sie aus den GRAUEN Infos an den einzelnen Knoten ziehen?
- in geschweiften Klammern werden die Anzahl der Schlüssel-Wert-Paare angezeigt, also die Anzahl der Einzelinformationen im entsprechenden (Teil)Datensatz
- in eckigen Klammern wird die Anzahl der Elemente in einer Liste angezeigt
XML
Die Extensible Markup Language (XML) ist ein weiteres hierarchisches Datenformat, das für die Repräsentation von strukturieren, hierarchischen Daten geeignet ist. Ähnlich wie in HTML werden Informationen in sogenannten Tags gespeichert, wobei in XML die Schlagwörter frei festgelegt werden können. So könnten wir unseren JSON Datensatz wie folgt in XML ablegen.
XML
<?xml version="1.0"?>
<termine>
<termin>
<Nr>1</Nr>
<Tag>Mo</Tag>
<Ort>Zoom</Ort>
</termin>
<termin>
<Nr>8</Nr>
<Tag>Di</Tag>
<Ort></Ort>
</termin>
</termine>Im Gegensatz zu JSON gibt es somit keine “unbenannten” Daten, da alle
Information in Tags eingeschlossen werden muss, die durch spitze
Klammern <> gekennzeichnet sind. Die führende Zeile
<?xml version="1.0"?> gibt die Version des
XML-Formats an, die in diesem Fall 1.0 ist, und zeigt beispielhaft, wie
in XML Metadaten etc. eingebettet werden können.
Da jede Information auch wieder mit einem schließenden Tag beendet werden muss, sind XML Kodierungen meist umfangreicher als JSON, was die Lesbarkeit und die Dateigröße beeinflußt. Allerdings erlaubt XML auch die Definition von Attributen, die zusätzliche Informationen zu den Tags enthalten können. Dies kann insbesondere bei der Speicherung von Metadaten oder anderen Informationen hilfreich sein, die nicht direkt in den Tags gespeichert werden sollen.
Vordefinierte Schemata wie DTD (Document Type Definition) oder XSD (XML Schema Definition) können verwendet werden, um die Struktur der XML-Datei festzulegen, die Validierung zu erleichtern und einheitliche Standards zum Datenaustausch zu ermöglichen. Ein Beispiel hierfür ist der TEI (Text Encoding Initiative) Standard für Textrepräsentation.
Versuchs mal …
Es gibt auch einen XML-Onlineeditor von tutorialspoint. Öffnen sie diesen und kopieren sie das obige XML in die linke Editormaske.
Was unterscheidet das XML Rendering (rechts) vom JSON Rendering aus der letzten Aufgabe oben?
- es gibt keine explizite Unterscheidung in Datensätze und Listen
- alle Informationen werden gleich (als Text) behandelt und angezeigt (bei JSON gab es unterschiedliche Darstellungen)
- Textinformation (zwischen einschließenden Tags) wird nicht
“gequotet”, d.h. es sind keine Anführungszeichen nötig!
Ausnahme sind “Attribute” der Tags, wie die Versionsinformation im
Beispiel. Tauschen sie mal
<termine>durch<termine info="meine Liste">aus…
Auch für XML gilt, dass dieses i.d.R. automatisiert als Datenformat erzeugt wird und nur in seltenen Fällen komplett manuell erfaßt wird. Allerdings ist es, im Vergleich zu JSON, einfacher menschenlesbar, da alle Elemente eindeutig mit Tags benannt und begrenzt sind.
YAML
YAML (YAML Ain’t Markup Language) ist ein weiteres hierarchisches Datenformat, das für die Repräsentation von strukturierten Daten geeignet ist. Es ist eine menschenlesbare Auszeichnungssprache, die sich durch ihre einfache Syntax und Lesbarkeit auszeichnet. YAML wird häufig für Konfigurationsdateien oder Metadaten verwendet. Für die Datenrepräsentation ist es jedoch nur bedingt geeignet, da es keine Unterstützung für komplexe Datenstrukturen bietet und keine Validierung der Datenstruktur ermöglicht.
Ein Beispiel für die YAML-Repräsentation unseres JSON-Datensatzes könnte wie folgt aussehen:
YAML verwendet Einrückungen, um die Hierarchie der Daten
darzustellen, und verwendet Bindestriche -, um Listen zu
kennzeichnen. Für eine weiterführende, kompakte Einführung empfehlen wir
die Webseite
Bilder und Grafiken
Neben Text- und Tabellendaten sind auch Bilder und Grafiken wichtige Bestandteile von Forschungsdaten. Hierbei wird grundlegend in zwei Arten von Bildinformationen unterschieden, die sich in ihrer Darstellung und Verwendung wesentlich unterscheiden.
- Rastergrafiken bestehen aus einer “Tabelle” von Pixeln, d.h. Farbinformationen pro Bildposition, und sind insbesondere für Fotos und Bilder geeignet, die eher eine diffuse Farbgebung oder Detailgestaltung haben.
- Vektorgrafiken hingegen sind eher “Malanleitungen”, die beschreiben wo welche Bildelemente mit welcher Farbe, Form, etc. gezeichnet werden soll. Dies ist insbesondere für technische Zeichnungen, Diagramme und Schaubilder geeignet, da diese Form der Bildkodierung verlustfrei skaliert (“gezoomt”) werden kann.
Rastergrafiken
Dateiendungen:
-
.jpgoder.jpeg: JPEG (Joint Photographic Experts Group) - weit verbreitetes Format für Fotos und Bilder. ACHTUNG: verlustbehaftet, d.h. Abwägung zwischen Datenverlust und Dateigröße! -
.png: Portable Network Graphics - verlustfreies Format für Bilder, Diagramme und Grafiken -
.tifoder.tiff: Tagged Image File Format - verlustfreies Format für hochauflösende Bilder und Scans (vor allem für hochqualitativen Druck) -
.gif: Graphics Interchange Format - verlustfreies Format für Animationen und einfache Grafiken
Der zentralen Unterschied zwischen diesen Formaten ist die Art der Kompression und die damit verbundene Qualität der Bilder. Während JPEG-Dateien eine verlustbehaftete Kompression verwenden, die die Dateigröße reduziert, aber auch die Bildqualität beeinträchtigen kann, sind PNG- und TIFF-Dateien verlustfrei und eignen sich daher besser für die Speicherung von Bildern, bei denen die Qualität erhalten bleiben soll.
Daher sollte die Wahl des Dateiformats von der Art des Bildes und der beabsichtigten Verwendung abhängen. Für Fotos und Bilder, die auf Webseiten oder in Präsentationen verwendet werden, ist JPEG oft ausreichend, während PNG oder TIFF für hochwertige Drucke oder Grafiken bevorzugt werden sollten.

Vektorgrafiken
Dateiendungen:
-
.svg: Scalable Vector Graphics - XML Format für Grafiken und Diagramme (z.B. für Webseiten) -
.pdf: Portable Document Format - für Dokumente, kann aber auch Vektorgrafiken enthalten (z.B. für wissenschaftliche Publikationen) -
.eps: Encapsulated PostScript - für Druckgrafiken und technische Zeichnungen (eher veraltet) -
.ai: Adobe Illustrator (proprietär) -
.cdr: Corel Draw (proprietär)
Im Gegensatz zu Rastergrafiken wird in Vektorgrafiken nicht das finale Bild gespeichert, sondern eine Anleitung, wie das Bild zu zeichnen ist. Daher eigenen sich Vektorgrafiken besonders für technische Zeichnungen, Diagramme und Schaubilder, die klar definierte Formen und Linien haben und i.d.R. einheitliche Farbflächen verwenden. Jedem Bildelement (z.B. Linie, Kreis, Text) wird eine mathematische Formel zugewiesen, die die Position, Form des Elements beschreibt. Zudem kann für jedes einzelne Element die Farbe, Linienstärke, Füllung, etc. definiert werden, was eine hohe Flexibilität bei der Darstellung ermöglicht.
Da Vektorgrafiken nicht aus Pixeln bestehen, sondern aus mathematischen Formeln, können sie verlustfrei skaliert werden, d.h. sie können ohne Qualitätsverlust vergrößert oder verkleinert werden. Auch ermöglichen Vektorgrafiken häufig eine bessere Komprimierung, da die mathematischen Formeln weniger Speicherplatz benötigen als die Pixelinformationen von Rastergrafiken, sodass die Dateigröße von (einfachen) Vektorgrafiken i.d.R. kleiner ist. Auch ist es möglich, nur Ausschnitte von Vektorgrafiken zu verwenden, ohne dass die Qualität leidet.
Da Vektorgrafiken in der Regel in speziellen Programmen erstellt werden, sind die Dateiformate häufig proprietär und können nicht ohne weiteres von anderen Programmen geöffnet oder bearbeitet werden. Eine Ausnahme bildet das SVG-Format, das auf XML basiert und daher auch von anderen Programmen gelesen und bearbeitet werden kann. Das SVG-Format wurde speziell für das Web entwickelt und ist daher besonders für Webseiten geeignet. Hierbei können Vektorgrafiken direkt in den HTML-Code eingebunden werden und sind daher besonders für interaktive Grafiken und Diagramme geeignet, die mit Hilfe von JavaScript dynamisch verändert werden können (inhaltlich wie auch optisch). Aufgrund seiner Verbreitung und Flexibilität ist das SVG-Format sehr gut für den Datenaustausch und die Archivierung von Grafiken geeignet.
Für die Publikation von wissenschaftlichen Ergebnissen ist das PDF-Format besonders geeignet, da es sowohl Text als auch Vektorgrafiken und Rasterbilder enthalten kann, auf nahezu jedem Gerät geöffnet werden kann und für die einheitliche Darstellung auf allen Geräten entwickelt wurde. Zudem können PDF-Dateien mit Metadaten versehen werden, die Informationen über den Autor, das Erstellungsdatum, die Lizenz, etc. enthalten. Dies ist besonders wichtig für die Nachvollziehbarkeit und Zitierbarkeit von wissenschaftlichen Ergebnissen.
Schwierigkeiten mit digitalen Bildern
Rastergrafiken haben den Nachteil, dass sie bei der Vergrößerung an Qualität verlieren, da die Pixelinformationen interpoliert werden müssen, d.h. die Software muss die fehlenden Pixel “erraten” oder Zwischenwerte berechnen. Dies führt zu Unschärfe und Verzerrungen, insbesondere bei starken Vergrößerungen. Auch die Farbtiefe und Auflösung der Bilder beeinflussen die Qualität und Dateigröße, sodass eine Abwägung zwischen Qualität und Speicherplatzbedarf getroffen werden muss.

Vektorgrafiken sind hingegen nicht für alle Arten von Bildern geeignet, insbesondere für Fotos und Bilder mit komplexen Farbverläufen und Texturen. Hier sind Rastergrafiken besser geeignet, da sie die feinen Details und Farbnuancen besser darstellen können. Zudem werden Vektorgrafiken bei der Konvertierung in Rastergrafiken (z.B. für den Druck) in der Regel gerastert, d.h. in Pixel umgewandelt, was zu Qualitätsverlusten führen kann. Bei sehr komplexen Vektorgrafiken mit sehr vielen (überlappenden) Elementen kann die Dateigröße auch größer sein als bei vergleichbaren Rastergrafiken, da die mathematischen Formeln und die Vielzahl der Einzelelemente mehr Speicherplatz benötigen.
Zusammenfassung
- Standardisierte Dateiformate erleichtern den Datenaustausch und die
Archivierung von Daten.
- für Rohdaten und Publikation
- für Austausch mit Kollegen und der Öffentlichkeit
- i.d.R. textbasierte Formate (z.B. CSV, JSON, XML)
- Achtung: Kodierung von Zeichen und Zeilenumbrüchen beachten!
- meist “offen” und plattformunabhängig
- Proprietäre Dateiformate für internen Gebrauch und spezielle
Anwendungen/Software
- ermöglichen i.d.R. umfangreichere Informationsspeicherung und -darstellung
- können (für Austausch) in offene Formate konvertiert werden
- Wahl des Dateiformats u.a. abhängig von
- Art der Daten (z.B. Text, Bild, Video, Audio, ..)
- Verwendungszweck (z.B. Analyse, Publikation, Archivierung)
- Kompatibilität mit Software und Plattformen
- Dateiendungen
- sind nur ein Teil des Namens ohne weitere Auswirkungen
- ermöglichen dem Betriebssystem das richtige Programm zum Öffnen
auszuwählen
- Programmassoziation kann geändert werden!
Einordnung im Datenlebenszyklus
Die richtige Wahl des Dateiformats ist in allen Phasen des Datenlebenszyklus wichtig:
- Planung: Auswahl geeigneter Formate für die Datenerhebung, -analyse und -publikation
- Erhebung: Speicherung und Dokumentation der Daten
- Analyse: Verwendung von geeigneten Formaten für die Analyse (Skripte) und von Zwischenergebnissen (ggf. proprietäre Formate)
- Publikation: Bereitstellung der Daten in geeigneten Formaten
- Archivierung: Langzeitarchivierung in geeigneten Standardformaten
- Nachnutzung: Dokumentation; Auswahl von Formaten, die die eigene Nachnutzung erleichtern
Anwendungsaufgaben
- Sitzungsaufgabe “Strukturcheck von Dateien”
- Sitzungsaufgabe “Was für was?”
- Sitzungsaufgabe “Einheitliche Dokumentation”
ggf. noch Aufgaben zu
- PDF editing
- Dateikonvertierung
Proprietär bedeutet, dass das Dateiformat von einem bestimmten Hersteller oder für dessen Programm entwickelt wurde und daher nur von diesem Programm oder von Programmen, die das Format kennen und unterstützen, gelesen oder verarbeitet werden können.↩︎
Quelle - B.K. Nielsen - Freron - 07.08.2024↩︎
Quelle - Chris Spann - Lumar - 07.08.2024↩︎
Quelle - F. Graf - wikipedia.de - 09.08.2024↩︎
Quelle - selfhtml.org - 12.09.2024↩︎
Content from Dateiverwaltung
Zuletzt aktualisiert am 2025-08-21 | Diese Seite bearbeiten
Geschätzte Zeit: 25 Minuten
Übersicht
Fragen
- USB Stick nicht lesbar?
- Zugeschickte Datei nicht lesbar?
- Was wenn ganz viele Dateien?
Ziele
- Unterschiede der Dateisysteme gängiger Betriebssysteme
- Best Practices für Dateinamen und Pfade
- Automatisierung von Dateiverarbeitungsabläufen
In den meisten Fällen arbeitet man heutzutage in einem sehr heterogenen Computerumfeld, d.h. es kommen verschiedene Betriebssysteme zum Einsatz, die jeweils ihre eigenen Dateisysteme verwenden. Zum Beispiel arbeitet ein Mitarbeiter auf einem Windows-Rechner, ein anderer auf einem Mac und wieder ein anderer auf einem Linux-Rechner oder Daten werden auf einem Linux-basierten Server gespeichert. Daher sollte man einen Überblick über die Unterschiede und Eigenheiten der Dateisysteme haben, um die Datenübertragung und -verarbeitung über Systemgrenzen hinweg zu erleichtern.
Datei- vs. Betriebssystem
Was ist ein Dateisystem?
Ein Dateisystem organisiert Daten auf Speichermedien wie Festplatten, SSDs oder USB-Sticks. Es legt fest:
- wie Dateien gespeichert und gelesen werden,
- wie Zugriffsrechte verwaltet werden,
- wie Daten strukturiert sind (z.B. Laufwerke, Ordner, Pfade, ..).
Gängige Dateisysteme sind im Folgenden aufgelistet und verglichen.
| Dateisystem | Betriebssystem(e) | Max. Dateigröße | Kompatibilität |
|---|---|---|---|
| FAT32 | Windows, Linux, macOS | 4 GB | Hoch (aber veraltet) |
| NTFS | Windows | >16 TB | Eingeschränkt auf macOS/Linux |
| exFAT | Windows, macOS, Linux | >16 EB | Sehr hoch |
| HFS+ | macOS | >8 EB | Nur macOS |
| APFS | macOS | >8 EB | Nur macOS |
| ext4 | Linux | >1 EB | Eingeschränkt auf Windows/macOS |
| Btrfs/XFS | Linux | >16 EB | Nur Linux |
Man sieht hier deutlich, dass sich Dateisystem u.a. in der maximalen Dateigröße und der Kompatibilität unterscheiden. Ein weiteres Unterscheidungsmerkmal ist ihre Unterstützung durch verbreitete Betriebssysteme.
Was ist ein EB?
GB steht für “Gigabyte” und somit für \(10^9\) Bytes.
Was ist dann ein EB und für welche 10-Potenz steht es?
- kB = Kilobyte = \(10^3\) Bytes
- MB = Megabyte = \(10^6\) Bytes
- GB = Gigabyte = \(10^9\) Bytes
- TB = Terabyte = \(10^{12}\) Bytes
- PB = Petabyte = \(10^{15}\) Bytes
- EB = Exabyte = \(10^{18}\) Bytes … ganz schön viel! (derzeit…)
Was ist ein Betriebssystem?
Ein Betriebssystem (OS) ist die Software, die die Hardware eines Computers verwaltet und eine Schnittstelle für Anwendungen bereitstellt. Ein wichtiger Bestandteil eines Betriebssystems ist somit das Dateisystem, das die Organisation und Verwaltung von Dateien auf Speichermedien ermöglicht. Dabei ist es möglich, das ein Betriebssystem mehrere Dateisysteme unterstützt, aber in der Regel wird ein primäres Dateisystem für Festplatten und neue Datenträger verwendet.
Im Folgenden sind die gängigsten Betriebssysteme und ihre bevorzugten Dateisysteme aufgeführt:
- Windows nutzt hauptsächlich NTFS, unterstützt aber auch FAT32 und exFAT.
- macOS verwendet APFS (modern) und HFS+ (älter).
- Linux setzt auf ext4, Btrfs oder XFS, je nach Distribution und Einsatzzweck.
Kompatibilitätsaspekte
Um Daten zwischen verschiedenen Betriebssystemen auszutauschen, ist es wichtig, ein kompatibles Dateisystem zu wählen. Hier einige Hinweise:
- exFAT ist ideal für den Datenaustausch zwischen Windows, macOS und Linux.
- NTFS kann unter macOS und Linux oft nur gelesen werden, nicht geschrieben (außer mit Zusatzsoftware).
- ext4 ist unter Windows nur mit Zusatztools nutzbar.
Falls ein (externer) Datenträger ein Dateisystem verwendet, welches vom genutzten Betriebssystem nicht unterstützt wird, dann kann man in den meisten Fällen auf die enthaltenen Daten nicht zugreifen.
Welche Dateisysteme nutze ich?
Versuchen sie herauszufinden, welches Dateisystem auf folgenden Medien (je nach Verfügbarkeit) installiert ist.
- ihrer eingebauten (Haupt)festplatte
- einem USB-Stick
- einer externen Festplatte
Falls sie in ihrem Betriebssystem nicht wissen, wie das geht, recherchieren sie kurz. Das ist wirklich wichtig! 💪
Das Betriebssystem der Hauptfestplatte eines Computers ist i.d.R. mit einem der oben gelisteten Betriebssysteme ausgestattet, wobei die konkrete Auswahl häufig vom Alter oder der Version des Betriebssystems abhängt.
Je nach Alter und Größe des USB Sticks, sind diese zumeist mit FAT32 oder exFAT formatiert.
Dateinamen und Pfade
Beim Arbeiten mit Dateien in unterschiedlichen Betriebssystemen ist es wichtig, die Unterschiede in der Benennung und Pfadangabe zu kennen. Fehlerhafte Dateinamen oder falsche Pfadangaben können zu Problemen beim Zugriff, der Verarbeitung oder dem Austausch von Dateien führen.
Pfadnotationen im Vergleich
Die Art und Weise, wie Pfade zu Dateien angegeben werden, variiert zwischen Betriebssystemen. Hier sind die wichtigsten Unterschiede:
| Betriebssystem | Beispielpfad innerhalb des Systems | Besonderheiten |
|---|---|---|
| Windows | C:\Benutzer\Max\Dokumente |
Backslashes \ als Trenner |
| macOS/Linux | /home/max/Dokumente |
Slashes / als Trenner |
Windows verwendet Laufwerksbuchstaben für einzelne
Datenträger oder (Teil)festplatten (z.B. C:), während
Linux/macOS ein einheitliches Wurzelverzeichnis
(/) nutzen. Das heißt in letzterem sind alle Dateien und
Ordner Teil eines einzigen “Zugriffsbaumes”, während in Windows jeder
Datenträger ein eigenes “Laufwerk” mit eigener Orderhierarchie
darstellt. Dies ist im Folgenden dargestellt.
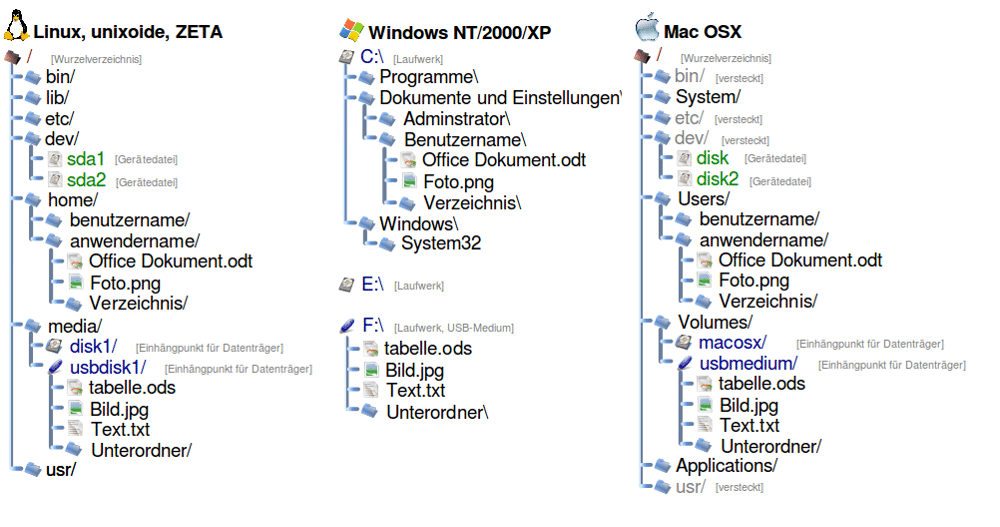
Zudem sind Pfade unter Linux/macOS case-sensitive,
d.h. Datei.txt ≠ datei.txt. Unter
Windows ist dies meist nicht der Fall.
Laufwerksbuchstaben
Welches Problem könnte sich aus der Verwendung von Buchstaben zur Bezeichnung von Laufwerken in Windows ergeben?
Da das Alphabet nur 26 Buchstaben umfasst, können “nur” 26 Laufwerke eingebunden werden.
Allerdings sind die Laufwerksbuchstaben in neueren Windowsversionen nur noch in der Darstellungsebene für die Benutzer relevant; intern werden die Laufwerke anders verwaltet.
Regeln für Dateinamen
Auch unterscheiden sich die Betriebssysteme in ihren Dateinamenskonventionen.
| Merkmal | Windows | macOS/Linux |
|---|---|---|
| Sonderzeichen | Verboten: \ / : * ? " < > |
|
Meist erlaubt, aber mit Vorsicht |
| Groß-/Kleinschreibung | Nicht relevant | Relevant (case-sensitive) |
| Erweiterungen | Wichtig (z.B. .docx) |
Optional, aber üblich |
Diese haben häufig direkte Auswirkung auf den Dateiaustausch, auch wenn die Dateien über Cloudservices oder Dateitransfer ausgetauscht werden.
Typische Probleme beim Dateiaustausch
-
Ungültige Zeichen: Eine Datei namens
Projekt:2025.docxfunktioniert unter Windows nicht. -
Groß-/Kleinschreibung:
Bericht.pdfundbericht.pdfsind unter Linux zwei verschiedene Dateien. - Pfadlängen: Windows hat Einschränkungen bei sehr langen Pfaden (>260 Zeichen).
Automatisierte Dateiverarbeitung
Wenn man mit einigen wenigen Dateien arbeitet, führt man die nötigen Dateiverwaltungsschritte wie Umbenennen, Verschieben, Vergleichen, Löschen, etc. zumeist manuell aus. Dies stößt schnell an seine Grenzen, wenn die Dateianzahl steigt. Daher ist es sinnvoll, diese Schritte zu automatisieren, um Zeit zu sparen und Fehler zu vermeiden.
Alle Betriebssysteme bieten Möglichkeiten, Dateiverwaltungsschritte zu automatisieren, z.B. durch:
- Shell Scripting: Mit Shell-Skripten (z.B. Bash unter Linux/macOS oder PowerShell/Cmd unter Windows) können wiederkehrende Aufgaben automatisiert werden.
- Programmiersprachen: vor allem Skriptsprachen wie Python bieten umfangreiche Bibliotheken zur Dateiverwaltung.
- Dateimanager: Viele Dateimanager bieten Funktionen zum Batch-Umbenennen, Verschieben oder Löschen von Dateien.
Automatisierung
Recherchieren sie eine Lösung für jeden der oben genannten Wege, um
alle *.txt Textdateien in einem gewählten Verzeichnis umzubenennen,
indem den Dateinamen ein backup_ Präfix vorangestellt
wird.
Finden sie Lösungen basierend auf
- einem Shellskript (Bash oder Powershell)
- einem Python-Skript
- einem Dateimanager (Windows Explorer oder Finder)
Ein mögliches Bash Shellskript unter Linux oder macOS:
PowerShell unter Windows:
Ein einfaches Python-Skript:
PYTHON
import os
for file in os.listdir('.'):
if file.endswith('.txt'):
os.rename(file, f'backup_{file}')Im Windows Explorer lassen sich alle .txt Dateien
auswählen, dann Rechtsklick -> “Umbenennen” und den neuen Namen
backup_ eingeben. Windows wird dann automatisch die
Nummerierung hinzufügen (z.B. backup_1.txt,
backup_2.txt, …).
Analog ist dies im macOS Finder möglich: Alle .txt
Dateien auswählen, dann Rechtsklick -> “Umbenennen” und den neuen
Namen backup_ eingeben. macOS wird ebenfalls die
Nummerierung hinzufügen.
Unbedingt beachten: In den beiden letzten Fällen gehen jedoch die Ursprungsnamen verloren!
Skript- und Programmiersprachen bieten hier den Vorteil, dass sie komplexere Logik implementieren können, z.B. um nur bestimmte Dateien umzubenennen oder zusätzliche Bedingungen zu prüfen.
Zudem sichern Skripte und Programme die Reproduzierbarkeit der Dateiverwaltungsschritte, da sie jederzeit wiederholt werden können, ohne dass manuelle Eingriffe nötig sind. Dies ist vor allem ein wichtiger Punkt bei der Prozessierung von Rohdaten. Die verwendeten Skripte können (und sollten!) dokumentiert, versioniert und zusammen mit den Rohdaten archiviert werden, was die Nachvollziehbarkeit und Wartbarkeit erhöht.
Skriptsprachen sind hierbei häufig die erste Wahl, da sie eine einfache Syntax bieten und direkt auf das Dateisystem zugreifen können. Zudem sind diese direkt in den meisten Betriebssystemen verfügbar und benötigen keine zusätzliche Installation.
Zusammenfassung
- Dateisysteme unterscheiden sich in ihrer Struktur, Kompatibilität und maximalen Dateigröße.
- Betriebssysteme nutzen/unterstützen unterschiedliche Dateisysteme und Pfadnotationen.
- Dateinamen und Pfade müssen betriebssystemkonform sein, um Probleme zu vermeiden.
- Automatisierung von Dateiverwaltungsschritten spart Zeit und reduziert Fehler.
- Skriptsprachen sind ideal für die Automatisierung von Dateiverwaltungsschritten.
Einordnung im Datenlebenszyklus
Das Wissen um die Dateiverwaltung ist immer dann zentral, wenn Dateien erzeugt, verarbeitet oder gespeichert werden.
- Planung: Festlegung von Dateisystemen und Dateinamenkonventionen
- Erhebung: Korrekte Dateinamen und Pfade, Automatisierung von Bearbeitungsabläufen
- Analyse: Automatisierung von Verwaltungsschritten
- Publikation: Dateiaustausch zwischen Projektpartnern
- Archivierung: Sicherung der Dateistruktur und -inhalte, Versionierung von Skripten
- Nachnutzung: Bereitstellung von Daten in kompatiblen Formaten, Namen, Organisationen
Sitzungsfragen
- Wie sollte ich Dateien besser nicht benennen und warum?
- Worin unterscheiden sich die Dateiverwaltungen von Windows, Linux und macOS?
- Welche Dateisysteme sind für den Datenaustausch zwischen Betriebssystemen geeignet?
- Wie kann ich viele Dateien auf einmal verarbeiten?
Quelle - Franz Fiala - 15.08.2025↩︎
Content from Forschungsdaten
Zuletzt aktualisiert am 2025-08-25 | Diese Seite bearbeiten
Geschätzte Zeit: 35 Minuten
Übersicht
Fragen
- Forschungsdaten?
- Teilen?
- F.A.I.R.?
Ziele
- Eingrenzen was Forschungsdaten sind
- Reflektieren warum Forschungsdaten geteilt werden sollten
- Einführung in die F.A.I.R.-Prinzipien
Was ist das?
Forschungsdaten sind die Grundlage wissenschaftlicher Erkenntnisse und können in unterschiedlichen Formen vorliegen.
Im Folgenden werden wir auf einige externe Seiten verweisen, die Ihnen einen Überblick über Forschungsdaten und deren Management geben.
Was zählt zu Forschungsdaten?
Studieren sie folgende Seite von Forschungsdaten.info und machen sie sich Notizen.
Sind das schon Forschungsdaten?
Reflektieren sie kurz über die folgende Frage:
Was macht eine Datei zu Forschungsdaten?
Üblicherweise handelt es sich bei Forschungsdaten um Rohdaten, denn das Filtern, Verarbeiten und Interpretieren der Daten im Rahmen einer Forschungsfrage beeinflusst die Daten und macht sie zu Ergebnisdaten. Zudem sollten die Daten strukturiert und dokumentiert sein, um sie für (sich selbst und) andere Forschende nachvollziehbar zu machen. Eine lose Textdatei mit Notizen oder eine Präsentation sind daher i.d.R. keine Forschungsdaten, sondern eher Ergebnisse oder Dokumentationen. Ob die Daten in einem nachnutzbaren Format vorliegen, ist zentral für die Wiederverwendbarkeit und wird durch die F.A.I.R.-Prinzipien adressiert, die wir bald kennenlernen werden.
Das heißt, Forschungsdaten sind nicht nur die Rohdaten, sondern auch die Metadaten, die Dokumentation und die Software, die zur Erhebung und Analyse der Daten verwendet wurde.
Warum teilen?
In der Vergangenheit wurden Forschungsdaten i.d.R. nicht publiziert, sondern nur die Ergebnisse der Forschung. Das hat sich in den letzten Jahren geändert, und es wird immer wichtiger, auch die Daten zu publizieren, um die Nachvollziehbarkeit und Wiederverwendbarkeit der Forschung zu gewährleisten.
Warum sollten Forschungsdaten geteilt werden?
Die folgende Seite von Forschungsdaten.info diskutiert
- Vorteile einer Datenpublikation (nur erster Teil der Seite!!!)
Und was hab ich davon?
Überlegen sie sich 3-4 Punkte, die für sie persönlich aus der Publikation von Forschungsdaten resultieren (könnten).
Die folgenden Punkte betreffen sowohl ihre eigene Forschung als auch die Forschung/Daten anderer.
- Nachvollziehbarkeit: Forschungsergebnisse können überprüft werden
- Wiederverwendbarkeit: Neue Forschung kann auf bestehenden Daten aufbauen
- Vergleichbarkeit: Daten können mit anderen Daten verglichen werden
- Nachhaltigkeit: Daten werden ggf. nicht doppelt erhoben
- Sichtbarkeit: Forschung wird bekannter und Erhebungsaufwand wertschätzbar
- Kollaboration: Kontakt zu anderen Forschenden, die an ähnlichen Themen arbeiten
- Reputation: Wissenschaftliche Zitierbarkeit und Anerkennung von Datenerhebung
- Förderung: Einige Fördergeber*innen verlangen die Publikation von Daten
- Lehre: Daten können in der Lehre verwendet werden
- Open Science: Beitrag zur offenen Wissenschaft und Wissenschaftskommunikation
- …
F.A.I.R.-Prinzipien
Das Teilen von Daten wird durch die F.A.I.R.-Prinzipien unterstützt, die die Auffindbarkeit, Zugänglichkeit, Interoperabilität und Wiederverwendbarkeit von Daten fördern. Dies betrifft sowohl den eigenen Zugriff auf schon geteilte Daten als auch die Veröffentlichung eigener Daten.
Und was sind FAIRe Daten?
Auch dazu gibt es von Forschungsdaten.info eine schöne Seite.
Dokumentation, Dokumentation, Dokumentation
Warum nimmt Dokumentation bei Daten eine so große Rolle ein?
Formulieren sie 3-4 Fragen, die sie sich stellen würden, wenn sie Daten von jemand anderem erhalten und die ohne Dokumentation nicht zu beantworten wären!
Ohne oder bei eingeschränkter Dokumentation können folgende Fragen nicht beantwortet werden.
- Welche Bedeutung haben die Daten/Werte/…?
- Wurden die Daten verändert, gefiltert, nachbearbeitet?
- Welche Rahmenbedingungen gab es bei der Datenerhebung?
- Welche Software wurde zur Analyse verwendet?
- Darf ich die Daten weiterverwenden?
- Wie kann ich die Daten zitieren?
- Wen kann ich bei Fragen kontaktieren?
- …
Zusammenfassung
- Forschungsdaten sind nicht nur Rohdaten, sondern auch Metadaten, Dokumentation und Software.
- Forschungsdaten sollten geteilt werden.
- Die F.A.I.R.-Prinzipien unterstützen das Teilen von Daten. (Findable, Accessible, Interoperable, Reusable)
- Dokumentation ist zentral für die Nachvollziehbarkeit und Wiederverwendbarkeit von Daten.
Einordnung im Datenlebenszyklus
Eigentlich in allen Phasen, da eine gute Dokumentation und Strukturierung der Daten die Nachvollziehbarkeit und Wiederverwendbarkeit in allen Phasen des Lebenszyklus unterstützt.
- Planung: Dokumentation der Forschungsfrage und der zu verwendenden Daten/Quellen
- Erhebung: Dokumentation der Rahmenbedingungen und der Datenerhebung
- Analyse: Dokumentation der Analyse und der Software
- Publikation: Teilen der Daten und Dokumentation
- Archivierung: Langfristige Sicherung und Zugänglichkeit der Daten
- Nachnutzung: Nachvollziehbarkeit und Wiederverwendbarkeit der Daten
Content from Finden und Zitieren
Zuletzt aktualisiert am 2025-04-24 | Diese Seite bearbeiten
Geschätzte Zeit: 50 Minuten
Übersicht
Fragen
- Wo?
- Wie?
- Wer?
Ziele
- Öffentliche Repositorien für Forschungsdaten
- Gezielte Suche nach Forschungsdaten
- Zitieren von Forschungsdaten
Um Forschungsdaten findbar und zugänglich zu machen, werden diese in speziellen Repositorien und Datenbanken abgelegt. Hierbei wird unterschieden in fachspezifische und allgemeine Repositorien. Die Datenbanken und Repositorien sind in der Regel öffentlich zugänglich und bieten die Möglichkeit, Daten zu suchen, zu finden und herunterzuladen.
Das Suchen und Finden von Forschungsdaten ist jedoch nicht immer so einfach, wie es klingt. Daher gibt es einige Tipps und Tricks, die die Suche erleichtern können.
Zudem muss geprüft werden, ob die Daten in einer Form vorliegen, die eine Wiederverwendung ermöglicht. Auch Lizenzfragen sind zu klären.
Final ist es wichtig, die gefundenen Daten korrekt zu zitieren, um die Quelle zu kennzeichnen und Wiederverwendung sichtbar zu machen.
All diese Punkte werden in einem Lernmodul der Friedrich-Alexander-Universität Erlangen-Nürnberg näher beleuchtet, welches im Folgenden durchgearbeitet werden soll
Lernmodul “Forschungsdaten suchen & nachnutzen”
Arbeiten sie sich durch das Lernmodul der Friedrich-Alexander-Universität Erlangen-Nürnberg.
- Organisation und Lerninhalte
- Repositorien und Suchmaschinen
- Recherchestrategien
- Technische Nachnutzbarkeit
- Qualität der Datendokumentation
- Rechtliche Rahmenbedingungen
- Prinzipien der Datenzitierung
Bitte auch die dortigen Wissenstests an den Seitenenden durchführen!
Zusammenfassung
- Forschungsdaten sind in speziellen Repositorien und Datenbanken abgelegt, i.d.R. öffentlich zugänglich.
- Es gibt fachspezifische und allgemeine Repositorien.
- Aufgrund der Vielzahl an Repositorien und Datenbanken ist die Suche nach Forschungsdaten nicht immer einfach und verlangt eine ausdauernde Recherche.
- Vorliegende Datenformate und vorhandene Software(kenntnisse) müssen geprüft werden, um eine Wiederverwendung zu ermöglichen.
- Lizenzen müssen die Wiederverwendung erlauben.
- Korrekte Zitation ist zentral in wissenschaftlicher Praxis.
Einordnung im Datenlebenszyklus
Datenrecherche und Zitation sind vorrangig zu Beginn und am Ende des Datenlebenszyklus wichtig.
- Planung: Schlagworte etc. für spätere Suche festlegen
- Erhebung: Wiederverwendung von Daten
- Publikation: Zitation von verwendeten Daten
- Archivierung: Festlegung von Metadaten, Identifiern und Lizenzen, um Wiederverwendung zu ermöglichen
- Nachnutzung: Daten/Quellen identifizieren, bewerten und einordnen
Content from Netzwerke
Zuletzt aktualisiert am 2025-08-21 | Diese Seite bearbeiten
Geschätzte Zeit: 40 Minuten
Übersicht
Fragen
- Router?
- Ports?
- Firewall?
- Logging?
Ziele
- Wie funktioniert das Internet?
- Wie finden die Daten ihr Ziel?
- Wie kann ich mich schützen?
- Wer sieht was ich im Internet mache?
Die Verwendung des Internets ist heute allgegenwärtig. Doch wie funktioniert das Internet eigentlich? Wie finden die Daten ihren Weg? Und wie kann ich mich schützen? Auf diese und ähnliche Fragen wollen wir im Folgenden eingehen.
Computernetzwerke und das Internet
Ein Computernetzwerk ist eine Ansammlung von Rechnern, die miteinander verbunden sind und Informationen austauschen können. Hierbei ist die Art der Verbindung entscheidend und diese kann sowohl kabelgebunden (z.B. via elektrischem oder Glasfaserleiter) als auch drahtlos (z.B. via Funk, Satelit, Infrarot, …) erfolgen. Kabelgebundene Verbindungen sind in der Regel schneller und sicherer, während drahtlose Verbindungen flexibler sind und keine physische Verbindung benötigen. Daher sind drahtlose Verbindungen insbesondere für mobile Geräte wie Smartphones und Tablets von Bedeutung wohingegen kabelgebundene Verbindungen in Büroumgebungen oder Rechenzentren vorherrschen bzw. Knotenpunkte im Internet miteinander verbinden.
Das Internet selbst ist ein weltweites Netzwerk von Computernetzwerken, das auf dem Internetprotokoll (IP) basiert. Das Internetprotokoll ist ein Regelwerk, das den Datenaustausch zwischen Rechnern regelt und dabei die Daten in Pakete aufteilt, die über das Netzwerk verschickt werden. Die Pakete enthalten neben den eigentlichen Daten auch Informationen über den Absender und Empfänger, sodass die Pakete ihren Weg durch das Netzwerk finden können. Die Pakete werden dabei von Routern weitergeleitet, die die Pakete anhand der Empfängeradresse an den nächsten Knotenpunkt im Netzwerk weiterleiten. Die Knotenpunkte sind dabei die Verbindungen zwischen den einzelnen Netzwerken und können sowohl kabelgebunden als auch drahtlos sein. Da Satelit, Funk und andere drahtlose Verbindungen eine (relativ) geringere Bandbreite und “Transportgeschwindigkeit” haben, werden diese in der Regel nur für die letzte Meile verwendet, also die Verbindung zwischen dem Endgerät und dem nächsten Knotenpunkt. Zwischen den Knotenpunkten werden in der Regel Glasfaserleitungen verwendet, die eine hohe Bandbreite und Geschwindigkeit haben. Um die Kommunikation zwischen Kontinenten und Ländern zu ermöglichen, werden unterseeische Kabel verwendet, welche im Folgenden visualisiert sind.
Lebensadern des Internets
Unterseeische Kabel sind die Lebensadern des Internets. Das diese dennoch anfällig sind, zeigt der Schiffsankerschaden 2019 und der Vulkansausbruch 2022 in Tonga, welche die Kommunikation des Inselstaates mit der Außenwelt unterbrachen.
Die folgenden beiden Artikel geben exemplarisch einen kurzen Einblick in die Bedeutung und Funktionsweise von Unterseekabeln:
Damit die Datenpakete ihren Weg durch das Netzwerk finden, benötigen
sie eine Adresse, die den Weg durch das Netzwerk beschreibt. Diese
Adresse ist die IP-Adresse, die aus einer Kombination von Zahlen und
Punkten besteht. Zum Beispiel hat der Server (Computer), der die
Webseite der Universität Tübingen bereitstellt, die IP-Adresse
134.2.5.1. Allerdings gibt es mehr Geräte im Internet als
es IP-Adressen gibt, sodass die IP-Adressen in der Regel dynamisch
vergeben werden (sich also immer wieder ändern) bzw. innerhalb eines
Netzwerkes lokal sind.
Um sich den Kommunikationsprozess und die IP-Lokalität vorzustellen, hier eine kleine Analogie:
- Sie machen Urlaub in einem Hotel im Zimmer Nummer 5.
- Wenn Sie eine Postkarte verschicken möchten, schreiben Sie die Zieladresse auf die Postkarte.
- Diese geben sie beim Portier in Zimmer Nummer 1 ab, der die Postkarte an den Empfänger weiterleitet.
- Hierzu verlässt der Portier das Hotel und gibt die Postkarte an den Briefträger, der diese ins Briefzentrum bringt.
- Im Briefzentrum wird die Postkarte an ein Verteilzentrum weitergeleitet, welches die Postkarte an ein Verteilzentrum in der Nähe des Empfängers weiterleitet.
- Von dort gehts ins entsprechende Briefzentrum und von dort zum Empfänger.
Das bedeutet, dass für die Weiterleitung der Postkarte mehrere Personen und Einrichtungen beteiligt sind, die die Postkarte anhand der Adresse weiterleiten, obwohl die meisten von ihnen den Zielort bzw. dessen Lokalisierung gar nicht kennen (Sie selbst, der Portier, der lokale Briefträger, …).
Wenn sie nun Post empfangen möchten, sehen sie an obiger Analogie, dass es nicht reicht, dass die Antwort an sie an Zimmer Nummer 5 adressiert wird. Ohne die Hoteladresse wird sie die Antwort nicht erreichen. Je nach Distanz bedarf es auch noch der Information über die Stadt oder sogar das Land, in dem das Hotel liegt. Zudem bedarf es des lokalen Portiers, der die Postkarte in Zimmer 1 entgegennimmt und an sie ins Zimmer 5 weiterleitet.
Ähnliches gilt auch für das Internet:
- Ihr Computer, an dem sie eine Nachricht verschicken, hat eine IP-Adresse (Zimmernummer) innerhalb ihres lokalen Netzwerkes (Hotel).
- Um eine Nachricht ins Internet zu senden, benötigen sie einen Router (Portier), der die Nachricht an den nächsten Knotenpunkt weiterleitet.
- Hierzu muss der Router sich mit dem Internet verbinden (Hotel verlassen). Diese Verbindung wird durch einen Internet Service Provider (ISP) bereitgestellt, der ihrem Router eine IP-Adresse zuweist (Hoteladresse).
- Diese ist eine andere als die IP-Adresse des Routers innerhalb ihres lokalen Netzwerkes! Der Portier lebt also in zwei Welten und hat zwei Adressen: eine innerhalb des Hotels, um für Gäste erreichbar zu sein (Zimmer 1), und eine außerhalb des Hotels (Hoteladresse), um die Post des Hotels zentral entgegen nehmen zu können.
Wie funktioniert das Internet?
Die Idee ist in folgender Grafik dargestellt, die in Blogbeitrag Wie funktioniert das Internet? näher beschrieben wird.
Allerdings bleibt eine Frage offen:
- Wie findet der Portier (Router) heraus, wohin die Postkarte (Datenpaket) geschickt werden soll?
Hierzu ist es nötig, dass die Postkarte auf eine bestimmte Art und Weise ausgefüllt wird, d.h. es gibt einen klaren Bereich in dem die Adresse steht. Derartige Festlegungen, wie Dinge ausgefüllt oder ausgeführt werden sollen, nennt man Protokoll. Im Falle des Internets ist ein wichtiges Protokoll das Transmission Control Protocol (TCP), welches die Kommunikation zwischen Computern regelt. Das TCP-Protokoll legt fest, wie die Datenpakete aufgebaut sind, d.h. welche Information wo steht und wieviel Platz benötigt. Das ist wichtig, weil ein Datenpaket ja eigentlich nur eine Sequenz von Binärinformation (Nullen und Einsen) ist, die von den Computern wieder zu Zahlen und Buchstaben interpretiert werden müssen. Das ist ein bischen wie beim Morsen: die Nachricht wird in eine Abfolge von kurzen und langen Signalen übersetzt, die dann wieder in Buchstaben und Zahlen zurück übersetzt werden müssen. Beim Letzteren ist entscheidend, das bekannt sein muss, wieviele Signale ein Zeichen kodieren!
Eine weitere wichtige Aufgabe des TCP ist die Segmentierung von Daten. Wenn ihre Nachricht nicht auf eine Postkarte passt, wird diese automatisch in mehrere Postkarten aufgeteilt, die dann einzeln verschickt werden. Das TCP-Protokoll sorgt dafür, dass die Postkarten (Datenpakete) in der richtigen Reihenfolge ankommen und wieder zusammengesetzt werden. Das ist wichtig, weil die Postkarten ja nicht unbedingt in der Reihenfolge ankommen, in der sie verschickt wurden.
Was sie an der obigen Analogie von Urlaubspostkarte und Webkommunikation aber auch erkennen können:
- Jeder der Beteiligten könnte die Postkarten lesen, wenn er wollte!
Das gleiche trifft auch auf das Internet zu: die Datenpakete werden von verschiedenen Knotenpunkten weitergeleitet, die die Pakete anhand der IP-Adresse an den nächsten Knotenpunkt weiterleiten. Wenn die Datenpakete unverschlüsselt sind, können die Knotenpunkte die Datenpakete lesen und ggf. manipulieren. Daher ist es i.d.R. wichtig, die Datenpakete zu verschlüsseln, um die Daten vor unbefugtem Zugriff zu schützen.
HTTPS-Verschlüsselung
Die meisten Webseiten verwenden das HTTPS-Protokoll, um die Datenpakete zu verschlüsseln. Das heisst, bevor irgendwelche Informationen/Daten zwischen ihrem Computer und dem Zielcomputer (Webserver) ausgetauscht werden, tauschen beide Computer “Schlüssel” aus, mit denen der nachfolgende Datenaustausch verschlüsselt werden.
Um das “Henne-Ei-Problem” zu lösen, da die Schlüssel ja auch übertragen werden müssen, wird ein sogenanntes Public-Key-Verfahren verwendet. Hierbei gibt ein Rechner einen öffentlichen Schlüssel aus, mit dem jeder Nachrichten an diesen verschlüsseln kann. Allerdings hat nur der Rechner selbst den geheimen privaten Schlüssel, mit dem die Nachricht auch wieder entschlüsselt werden kann. Auf diese Weise kann man ein Geheimnis an jemanden übermitteln, mit dem dann nur dieser etwas anfangen kann.
Im Falle des HTTPS-Protokolls wird der öffentliche Schlüssel des Webservers genutzt, um die Daten zu verschlüsseln, die dann nur der Webserver entschlüsseln kann.
Der Ablauf ist in folgender Grafik illustriert.
ABER …
Aber wie stellen wir sicher, dass wir überhaupt mit dem richtigen Webserver kommunizieren? Hierzu gibt es sogenannte Zertifikate, die von Zertifizierungsstellen (Certification Authorities, CAs) ausgestellt werden. Diese Zertifikate enthalten den öffentlichen Schlüssel des Webservers und sind von der Zertifizierungsstelle signiert. Das bedeutet, dass die Zertifizierungsstelle bestätigt, dass der öffentliche Schlüssel tatsächlich zum Webserver gehört. Die Zertifikate werden von den Webbrowsern genutzt, um die Identität des Webservers zu überprüfen. Da die Zertifikate zeitlich begrenzt sind, müssen sie regelmäßig erneuert werden.
Wer sieht was?
Trotz Verschlüsselung können alle beteiligten Computer die Metadaten der Datenpakete lesen. Diese Metadaten enthalten Informationen über den Absender, den Empfänger, die Größe des Datenpakets, den Zeitpunkt des Versands, … Dies umfasst u.a. auch die Adresse (URL/IP) der Zielwebseite.
Somit kann z.B. der lokale Router (Portier) sehen, welche Webseiten besucht wurden. Jeder der Zugriff auf diesen (also z.B. ihre lokale FritzBox oder dergleichen) hat (entweder von aussen oder direkt von innerhalb ihres lokalen Netzwerkes), kann diese Metadaten einsehen.
Metadaten Kommunikation
Denken sie kurz über die folgende Frage nach:
Was könnte man aus der Historie ihrer besuchten Webseiten etc. ablesen?
- Was ist ihre Bank?
- Wo kaufen sie ein?
- Welche Nachrichtenseiten lesen sie?
- …
Diese Informationen werden z.T. auch in Logfiles im Router gespeichert.
Auch der Internet Service Provider (ISP) kann sehen, welche Webseiten besucht wurden, welche Apps genutzt wurden, … Dieser ist sogar, aufgrund der Vorratsdatenspeicherung, verpflichtet, diese Daten für eine bestimmte Zeit zu speichern, um diese ggf. zur Aufklärung von Straftaten zur Verfügung zu stellen. Wenn also jemand Zugriff auf diese Daten erhält, kann er ein ziemlich genaues Bild über ihre Aktivitäten im Internet erstellen.
Das gleiche gilt auch für frei verfügbare WLAN-Anbieter (Cafe, Bahnhof, …), die die Datenpakete ihrer Nutzer mitlesen können.
Auch der Webserver, mit dem sie kommunizieren, kann die Metadaten der Datenpakete sehen und auswerten. Und wenn sie sich auf einer Webseite registrieren und eingeloggt sind, dann kann der Webseitenbetreiber auch noch weitere Informationen über sie sammeln.
VPN
Eine VPN-Verbindung (Virtual Private Network) kann helfen, ihre Daten vor neugierigen Blicken zu schützen. Hierbei wird eine verschlüsselte Verbindung zu einem VPN-Server aufgebaut, der dann die Datenpakete weiterleitet.
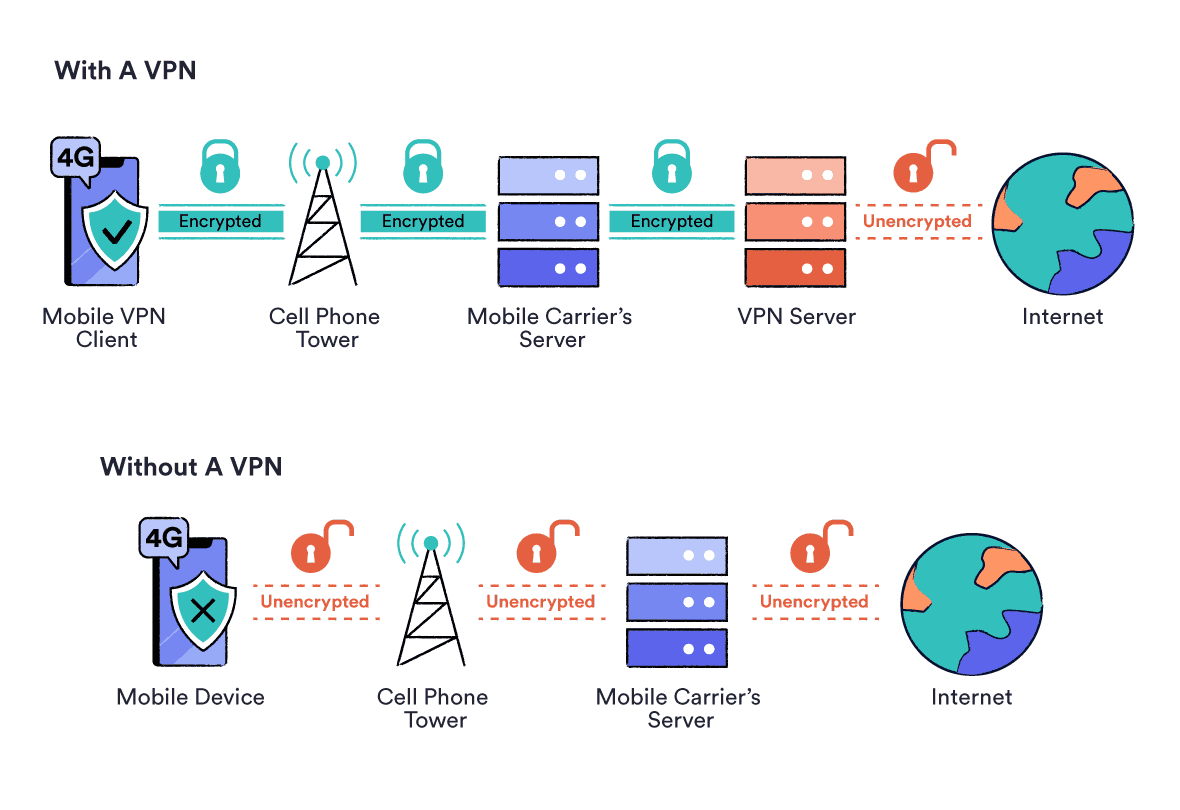
Der Datenverkehr zwischen ihrem Computer und dem VPN-Server ist verschlüsselt, so dass niemand die Datenpakete lesen kann. Erst der VPN-Server entschlüsselt die Datenpakete und stellt die Verbindung zum Zielserver her. Dadurch kann der Zielserver nur die IP-Adresse des VPN-Servers sehen, nicht aber ihre eigene IP-Adresse. Der VPN-Server kann zwar die Metadaten der Datenpakete sehen, aber er kennt nicht den Inhalt der Datenpakete, wenn diese (z.B. via HTTPS) verschlüsselt sind.
Somit können lokale Router, ISPs, WLAN-Anbieter, … nicht mehr sehen, welche Webseiten besucht werden.
ABER …
Aber der VPN-Anbieter kann die Metadaten der Datenpakete sehen und auswertenm, da er diese ja für sie weiterleitet und entgegennimmt. Auch der Internetprovider des VPN-Anbieters kann die Metadaten der Datenpakete sehen und auswerten, auch wenn diesem die Zuordnung zu ihnen nicht bekannt ist.
VPN schützt also vor lokalen Schnüfflern, aber nicht vor dem VPN-Anbieter und dessen Internetprovider. Somit sollten sie sich gut überlegen, welchem VPN-Anbieter sie vertrauen.
Ein weiterer Nachteil von VPN ist, dass die Datenpakete über den VPN-Server geleitet werden, was zu einer Verlangsamung der Verbindung führen kann. Allerdings bieten VPN-Anbieter auch Server in verschiedenen Ländern an, so dass sie z.B. über eine IP-Adresse aus einem anderen Land (die des VPN Servers) mit dem Internet kommunizieren, um z.B. Geoblocking oder lokalisierte Werbung zu umgehen.
DNS
Soweit haben wir uns nur mit der Kommunikation zwischen ihrem
Computer und dem Webserver beschäftigt, welche auf der Adressierung über
IP-Adressen basiert. Allerdings werden IP-Adressen i.d.R. nur bei
automatisierten Prozessen verwendet und direkt eingegeben. Wenn sie eine
Webseite besuchen, dann geben sie zumeist den Namen einer Webseite ein
(z.B. www.uni-tuebingen.de) und nicht die IP-Adresse des
dazu gehörigen Webservers.
Die Übersetzung von Namen in IP-Adressen wird über das Domain Name System (DNS) realisiert. Hierfür gibt es spezielle DNS-Server, die die Namen in IP-Adressen übersetzen. Sprich bevor ihr Computer eine Anfrage an den Webserver sendet, fragt er zuerst einen DNS-Server nach der IP-Adresse des Webservers.
In den meisten Fällen wird der DNS-Server von ihrem Internetprovider genutzt. Hier eine mögliche Liste von deutschen DNS Servern. Falls sie eine VPN-Verbindung nutzen, dann erfolgt die DNS-Anfrage über den VPN-Server (bzw. wird von diesem zu dessen DNS-Server weitergeleitet). In beiden Fällen kann der DNS-Server sehen, welche Webseiten besucht werden, da er ja die Anfragen nach den IP-Adressen der Webserver erhält.
Zudem kann auch eine Zensur durch DNS-Server erfolgen, indem der DNS-Server die Anfrage nach bestimmten Webseiten verweigert und ihnen keine oder eine andere IP-Adresse zurückliefert.. Allerdings können sie auch manuell einen anderen DNS-Server einstellen, um z.B. derartige Einschränkungen zu umgehen. Allerdings sollten sie sich auch hier gut überlegen, welchem DNS-Server (Anbieter) sie vertrauen.
URL
Der “Name” einer Webseite wird in mittels einer URL (Uniform Resource Locator) angegeben. Die URL besteht aus mehreren Teilen, die die Adresse des Webservers und den Pfad zur gewünschten Ressource (Webseite, Bild, …) beschreiben. Hier als Beispiel die URL der Login-Seite für den ILIAS Server der Universität Tübingen:
TXT
Markierung
Protokollende Serverende Zielende Argumenttrenner
||| | | |
https://ovidius.uni-tuebingen.de/ilias3/login.php?lang=en&cmd=force_login
| | | | |
| | | | +--- Argumente (&-getrennte key-value Paare)
| | | | hier: Sprache der Webseite & erzwungener Login
| | | +--- Name der Ressource (i.d.R. Datei auf dem Webserver)
| | | hier: dynamische Webseite
| | +--- Pfad zur Ressource
| | = virtuelle Ordnerstruktur
| +--- Name des Webservers (oder IP-Adresse)
| hierfür muss IP-Adresse über DNS aufgelöst werden
+--- Übertragungsprotokoll
hier: "verschlüsselte Webseite"
Die URL wird in der Regel in der Adresszeile des Browsers angezeigt und kann auch manuell eingegeben werden. So kann man bereits durch einen kurzen Blick auf die URL einiges erkennen, z.B.
- ob die Verbindung verschlüsselt ist (hier durch das
https://). - ob die Webseite überhaupt auf einem Server der gewünschten
Organisation liegt (hier
uni-tuebingen.de). Der Name des Webservers ist i.d.R. rückwärts zu lesen, d.h. von der allgemeinen Domain (hieruni-tuebingen.de) zum spezifischen Server (hierovidius). Das heißt, dass der Webserverovidiuszu den Servern der Domäneuni-tuebingen.degehört. Hierdurch lassen sich auch Subdomains (z.B.www.uni-tuebingen.deist der Webserver) und spezielle Dienste (z.B.ovidius.uni-tuebingen.deals Name für den ILIAS Server) unterscheiden. Es sollte darauf geachtet werden, dass die URL auch wirklich zur gewünschten Organisation gehört, da es z.B. Phishing-Seiten gibt, die im Link zwar den Namen einer bekannten Organisation verwenden, um Nutzer zu täuschen, aber auf einen anderen Server verweisen (Beispiel kommt gleich). - Durch Argumente in der URL können z.B. Parameter an die Webseite übergeben werden, die dann in der Darstellung oder Funktionalität der Webseite berücksichtigt werden. In obigem Beispiel wird die Sprache der Webseite auf Englisch gesetzt und ein erzwungener Login durchgeführt. Online-Shops, wie z.B. Amazon, verwenden die Argumente in der URL, um unabhängig von Cookies etc. die Session des Benutzers zu identifizieren und den Warenkorb zu speichern.
Der Name der Resource (hier login.php) sowie die
Webseitenargumente (hier lang=en&cmd=force_login) sind
bei vielen Webanfragen optional und werden i.d.R. vom Webserver
interpretiert. Das heisst der Webserver entschiedet, welche
(Standard)Ressource zurückgegeben wird und wie die Argumente verarbeitet
werden. So führt z.B. die Teil-URL
https://ovidius.uni-tuebingen.de/ilias3/ zur gleichen
Resource wie das obige Beispiel.
Link-Check vor jedem Klick
Bevor sie auf URLs klicken (in Webseiten, Suchmaschinen, Emails,
Messenger, PDF, ..), sollten sie sich immer kurz die URL ansehen und
überlegen, ob sie wirklich auf die gewünschte Webseite führt. Hierbei
ist vor allem der hintere Teil des Servernames (z.B.
uni-tuebingen.de) wichtig, da dieser den Server
identifiziert. Der vordere Teil kann vom Serveradministrator beliebig
gesetzt werden und wird oft für Phishing-Attacken missbraucht. Ein
mögliches Phishing-Beispiel wäre z.B.
TXT
| beliebig setzbar! | | Servername |
https://ovidius.uni-tuebingen.de.phishing-server.com/ilias3/wobei hier der Servername phishing-server.com ist und
nicht uni-tuebingen.de.
So ein Check geht schnell und verhindert schon einen Großteil möglicher Phishing-Attacken.
Das ist wie am Fussgängerüberweg: Auch wenn sie Vorrang haben, schauen sie kurz nach links und rechts, ob wirklich alle anhalten.
Zusammenfassung
- Jeder Computer ist über seine IP-Adresse (im Internet) identifizierbar.
- Zertifikate bestätigen die Identität von Webservern.
- Zu versendende Daten werden in Pakete aufgeteilt (z.B. via TCP) und über das Internetprotokoll (IP) verschickt.
- Datenpakete zwischen Computern werden “von Knoten zu Knoten” weitergeleitet.
- Datenpakete können von lokalen Routern, ISPs, WLAN-Anbietern, … eingesehen werden.
- HTTPS verschlüsselt den gesendeten Inhalt der Datenpakete (Metadaten wie Ziel-IP etc. nicht).
- VPN schützt vor lokalen Schnüfflern, aber nicht vor dem VPN-Anbieter.
- URLs beschreiben das Zieldokument inklusive des Namens des Webservers etc.
- Webservernamen werden durch DNS-Server in IP-Adressen aufgelöst
Einordnung im Datenlebenszyklus
Das Wissen um Netzwerkkommunikation und Verschlüsselung ist in allen Phasen des Datenlebenszyklus wichtig. Kenntnisse darum erleichtern uns, Probleme und Ursachen zu erkennen und zu lösen, die im Zusammenhang mit der Kommunikation von Daten auftreten können.
Immer dann, wenn wir auf fremde Rechner zugreifen oder mit diesen interagieren, sollte uns bewusst sein, dass wir dabei Spuren hinterlassen und dass diese Spuren auch von anderen eingesehen werden können.
Content from Browser
Zuletzt aktualisiert am 2025-01-03 | Diese Seite bearbeiten
Geschätzte Zeit: 40 Minuten
Übersicht
Fragen
- Browser?
- Cookies?
- JavaScript?
- Suchmaschinen?
Ziele
- Aufgaben und Funktionsweise von Browsern
- Einsatz und Ziele von Cookies
- Möglichkeiten und Grenzen von JavaScript
- Gedanken zu Suchmaschinen und GPTs/LLMs
Browser sind Programme, die es ermöglichen, Webseiten oder Dokumente anzuzeigen und mit diesen zu interagieren. Sie sind die Schnittstelle zwischen dem Nutzer und dem World Wide Web. Beispiele sind Google Chrome, Mozilla Firefox, Microsoft Edge und Safari (Apple).
Historie
Die ersten Browser waren textbasiert und konnten nur einfache
HTML-Dokumente (Webseiten) darstellen. Derartige Browser sind heute noch
im Einsatz, z.B. lynx oder w3m, und werden oft
in der Kommandozeile verwendet. Diese Browser sind sehr schnell und
ressourcenschonend, da sie keine Grafiken oder JavaScript ausführen
können, und können daher auch bei sehr langsamen Internetverbindungen
eingesetzt werden. Im Folgenden ist das Darstellen der Google-Startseite
in w3m dargestellt:
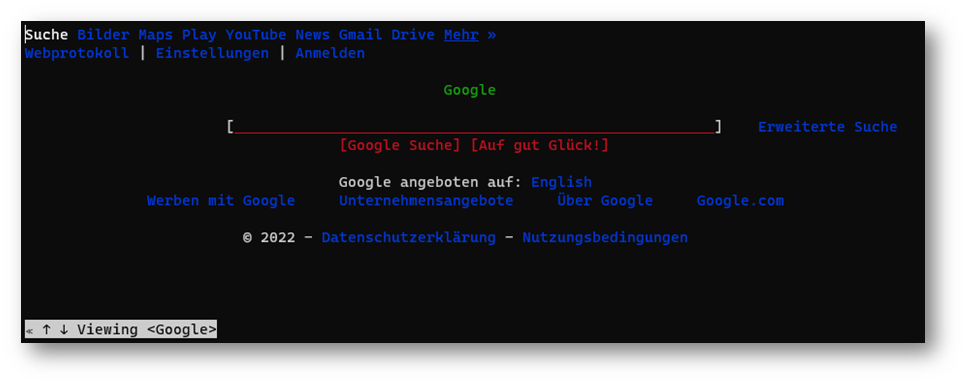
w3m
TextbrowserSeit den 1990er Jahren sind Browser in der Lage, auch Grafiken und andere Medien anzuzeigen. Die ersten Browser, die dies ermöglichten, waren Netscape Navigator und Microsoft Internet Explorer. Die “Browserkriege” der 1990er Jahre führten zu einer Vielzahl von proprietären Technologien, die die Entwicklung von Webseiten erschwerten. Gegen Ende der 1990er Jahre hatte Microsoft eine marktbeherrschende Stellung erreicht, die erst in den 2000er Jahren durch den Aufstieg von Mozilla Firefox und später Google Chrome gebrochen wurde. Die Entwicklung ist in der folgenden Grarik dargestellt.
Mit der Einführung von Google Chrome im Jahr 2008 begann eine neue Ära der Browserentwicklung. Chrome war der erste Browser, der auf der JavaScript-Engine V8 basierte, die deutlich schneller war als die Konkurrenz. Chrome führte auch eine Sandbox-Technologie ein, die es ermöglichte, Webseiten in isolierten Prozessen auszuführen, um die Sicherheit zu erhöhen. Seitdem haben sich die Browser stark weiterentwickelt und sind heute in der Lage, komplexe Webanwendungen auszuführen, die früher nur als Desktop-Anwendungen (eigenständige Programme) möglich waren. Mittlerweile basieren fast alle Browser auf der Open-Source-Engine Chromium (dem Herzstück von Chrome), die von Google entwickelt wurde, und sind daher sehr ähnlich in ihrer Funktionsweise.
Aufgabe
Microsoft Internet Explorer war lange Zeit der dominierende Browser, da er mit Windows gebündelt war.
Welche Gründe könnten für den Aufstieg von Google Chrome verantwortlich sein?
- Chrome war (wirklich) besser:
- schneller und ressourcenschonender
- Unterstützung für moderne Webstandards
- …
- ABER: Chrome ist mittlerweile der Standardbrowser auf Android-Geräten, was auch zu einer hohen Verbreitung beiträgt
Aufgaben und Funktionsweise von Browsern
Browser haben verschiedene Aufgaben, darunter:
- Anzeigen von Webseiten
- Ausführen von JavaScript
- Verwalten von Cookies
- Anzeigen von Medien (Bilder, Videos, Audio)
- Ausführen von Webanwendungen (z.B. Google Docs, Facebook)
- Unterstützung von Webstandards (HTML, CSS, JavaScript)
- Sicherheit (Sandboxing, HTTPS, Passwörter, Content Security Policy)
- Barrierefreiheit (Screenreader, Tastaturnavigation)
- Datenschutz (Verschlüsselung, Do Not Track)
- Erweiterbarkeit (Plugins, Addons)
- …
Browser sind also weit mehr als nur ein “Fenster” ins Internet, sondern eine komplexe Software, die viele verschiedene Technologien und Standards unterstützt und bündelt. Im Folgenden werden einige dieser Aufgaben näher beleuchtet.
Browser vs. Suchmaschine
Wichtig: Browser sind keine Suchmaschinen!
- Suchmaschinen = Webseiten, die es ermöglichen, Inhalte im Internet zu finden.
- Browser = Programme/Werkzeuge, die Webseiten anzeigen und mit ihnen interagieren.
Das heisst, man benötigt einen Browser, um eine Suchmaschine zu benutzen, aber nicht umgekehrt.
Webseiten anzeigen
Bevor wir uns damit beschäftigen, was alles geschehen muss, damit eine Webseite angezeigt wird, schauen wir uns an, wie eine Webseite aufgebaut ist.
Im Folgenden werden die wichtigsten Bestandteile einer Webseite zergliedert dargestellt.
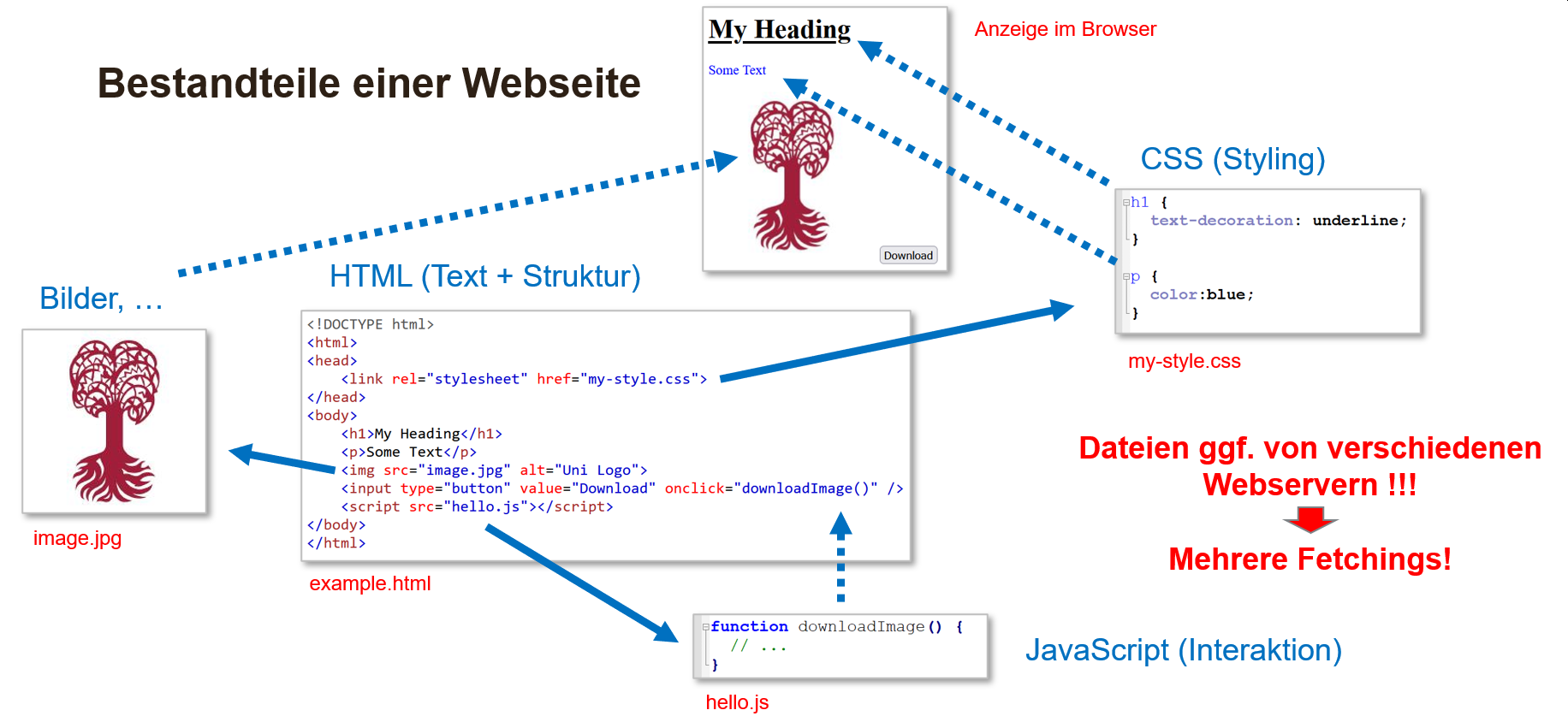
Zentral für eine Webseite ist die HTML-Datei, die den strukturellen Aufbau der Seite definiert. In dieser Datei werden die verschiedenen Elemente der Seite (Überschriften, Absätze, Links, Bilder, etc.) definiert und miteinander verknüpft bzw. deren Anordnung festgelegt.
Hierbei werden in der HTML-Datei auch Verweise auf andere Ressourcen gemacht, die für die Darstellung der Seite notwendig sind. So werden z.B. Bilddateien referenziert und deren Position auf der Seite festgelegt. Auch Schriftarten und CSS-Dateien (Cascading Style Sheets) werden in der HTML-Datei referenziert, um das Aussehen der Seite zu definieren.
Interaktivität und dynamische Inhalte werden durch JavaScript ermöglicht, das ebenfalls in der HTML-Datei eingebettet oder referenziert wird. JavaScript ermöglicht es, auf Benutzereingaben zu reagieren, Daten zu verarbeiten und zu speichern, und die Seite dynamisch zu verändern.
Alle diese Ressourcen müssen vom Browser zuerst geladen und verarbeitet werden, um die Seite anzuzeigen zu können. Das Laden und Verarbeiten dieser Ressourcen wird als Fetching bezeichnet und kann je nach Grösse und Anzahl der Ressourcen einige Zeit in Anspruch nehmen, was sich auf die Ladezeit der Seite auswirkt und stark von der Internetverbindung abhängt. Das anschliessende Rendering der Seite, also das Anzeigen der Seite im Browserfenster, kann ebenfalls einige Zeit in Anspruch nehmen, insbesondere wenn die Seite viele Elemente und komplexe Layouts enthält. Hierbei müssen die verschiedenen Elemente der Seite anhand des HTML-Codes und der CSS-Definitionen positioniert und formatiert werden, Bilder und Schriftarten geladen und dargestellt werden, und ggf. JavaScript-Code ausgeführt werden, um finale Anpassungen vorzunehmen. Dieser Prozess wird als Rendering Pipeline bezeichnet und ist ein komplexer Vorgang, der viele Schritte umfasst und von der Leistungsfähigkeit des Browsers und des Endgeräts abhängt.
JavaScript
Heutzutage sind Webseiten oft interaktiv und dynamisch, d.h. sie reagieren auf Benutzereingaben, laden Daten nach, und passen sich an die Umgebung (z.B. den Browser oder das Endgerät) an. Hierfür wird JavaScript verwendet, eine Programmiersprache, die im Browser ausgeführt wird.
Ein zentraler Fokus der Verwendung von JavaScript in Browsern ist die Sicherheit, da JavaScript potenziell gefährliche Aktionen ausführen kann, wie z.B. das Lesen von Dateien auf dem Computer des Benutzers oder das Senden von Daten an einen Server. Aus diesem Grund sind Browser so konzipiert, dass sie JavaScript in einer Sandbox ausführen, d.h. in einer isolierten Umgebung, die den Zugriff auf bestimmte Funktionen und Ressourcen des Endgeräts einschränkt. So kann JavaScript z.B. nicht auf das Dateisystem des Benutzers zugreifen oder auf andere Browser-Tabs oder -Fenster zugreifen. Dies dient dazu, die Sicherheit des Benutzers und seiner Daten zu gewährleisten und die Integrität des Browsers zu schützen.
Was geht (nicht) mit JavaScript im Browser?
| Möglich | Verhindert |
|---|---|
| Änderung der angezeigten Seite (HTML, CSS, Inhalte, …) | Kein Zugriff auf andere Browser-Tabs oder -Fenster |
| Interaktion mit dem Benutzer (Klicks, Tastatureingaben, …) | Kein (unauthorisierter) Zugriff auf Hardware (Kamera, Microfon, …) |
| Laden von Daten vom Webseitenserver (AJAX, Fetch, …) | Keine direkte Kommunikation mit anderen Webseiten |
| Speichern von Daten im Browser (Cookies, LocalStorage, …) | Kein Zugriff auf das Dateisystem des Benutzers |
| Komplexe Visualisierungen und Animationen | Keine Ausführen von Programmen auf dem Endgerät |
Aufgabe
Die Folgende Grafik von javacript.info fasst die verschiedenen Möglichkeiten und Einschränkungen von JavaScript im Browser zusammen.

Gleichen sie die Punkte aus der obigen Tabelle mit den Elementen der Grafik ab.
-
Möglichkeiten:
- Serverkommunikation (grüner Smiley)
- (stark beschränkter) Endgerätezugriff (roter Smiley nach unten)
-
Verhindert:
- Zugriff auf Hardware (roter Smiley nach unten)
- Zugriff auf andere Webseiten/Server (roter Smiley nach oben rechts)
- Zugriff auf andere Browser-Tabs/Fenster (roter Smiley nach rechts)
- Zugriff auf Dateisystem (roter Smiley nach unten)
- Ausführen von Programmen (roter Smiley nach unten)
Weiterführende Informationen
Weiterführende Informationen zu JavaScript und seinen Möglichkeiten und Einschränkungen finden Sie auf der Webseite javascript.info.
Cookies
Cookies sind kleine Textdateien, die vom Browser auf dem Endgerät des Benutzers gespeichert werden und Informationen über die Interaktion des Benutzers mit der Webseite enthalten. Cookies werden verwendet, um den Benutzer zu identifizieren, seine Einstellungen und Präferenzen zu speichern, und das Verhalten des Benutzers auf der Webseite zu verfolgen. Sie sind daher ein wichtiges Instrument für die Personalisierung von Webseiten und die Verbesserung der Benutzererfahrung. Mögliche Anwendungen von Cookies sind z.B.:
- Authentifizierung: Cookies werden verwendet, um den Benutzer zu identifizieren und seine Anmeldung auf der Webseite zu speichern.
- Sitzungsverwaltung: Cookies werden verwendet, um Informationen über die aktuelle Sitzung des Benutzers zu speichern, z.B. den Warenkorb in einem Online-Shop.
- Präferenzen: Cookies werden verwendet, um die Einstellungen und Präferenzen des Benutzers zu speichern, z.B. die Sprache oder das Design der Webseite.
Diese sogenannten Erstanbieter-Cookies (First-Party-Cookies) werden beim Wiederbesuch der Webseite vom Browser an den Server gesendet, um dem Server Informationen über den Benutzer und seine bisherige Interaktion mit der Webseite zur Verfügung zu stellen. Hierbei werden dem Server nur die Informationen übermittelt, die im Webseiten-zugehörigen Cookie gespeichert sind. Ein Zugriff auf Cookies anderer Webseiten ist nicht möglich.
ABER…
Cookies können auch von Drittanbietern (z.B. Werbenetzwerken) verwendet werden, um das Verhalten des Benutzers über verschiedene Webseiten hinweg zu verfolgen und personalisierte Werbung anzuzeigen.
- Tracking: Cookies werden verwendet, um das Verhalten des Benutzers auf der Webseite zu verfolgen und personalisierte Inhalte oder Werbung anzuzeigen.
Hierfür werden Drittanbieter-Cookies (Third-Party-Cookies) verwendet, die beim Laden von Teilen der Webseite (z.B. Werbung) von einem anderen Server als dem Webseiten-Server gesetzt werden. Hierdurch können Drittanbieter Informationen über das Verhalten des Benutzers auf verschiedenen Webseiten sammeln und personalisierte Werbung webseitenübergreifend anzeigen. Die Idee ist in folgender Grafik dargestellt.
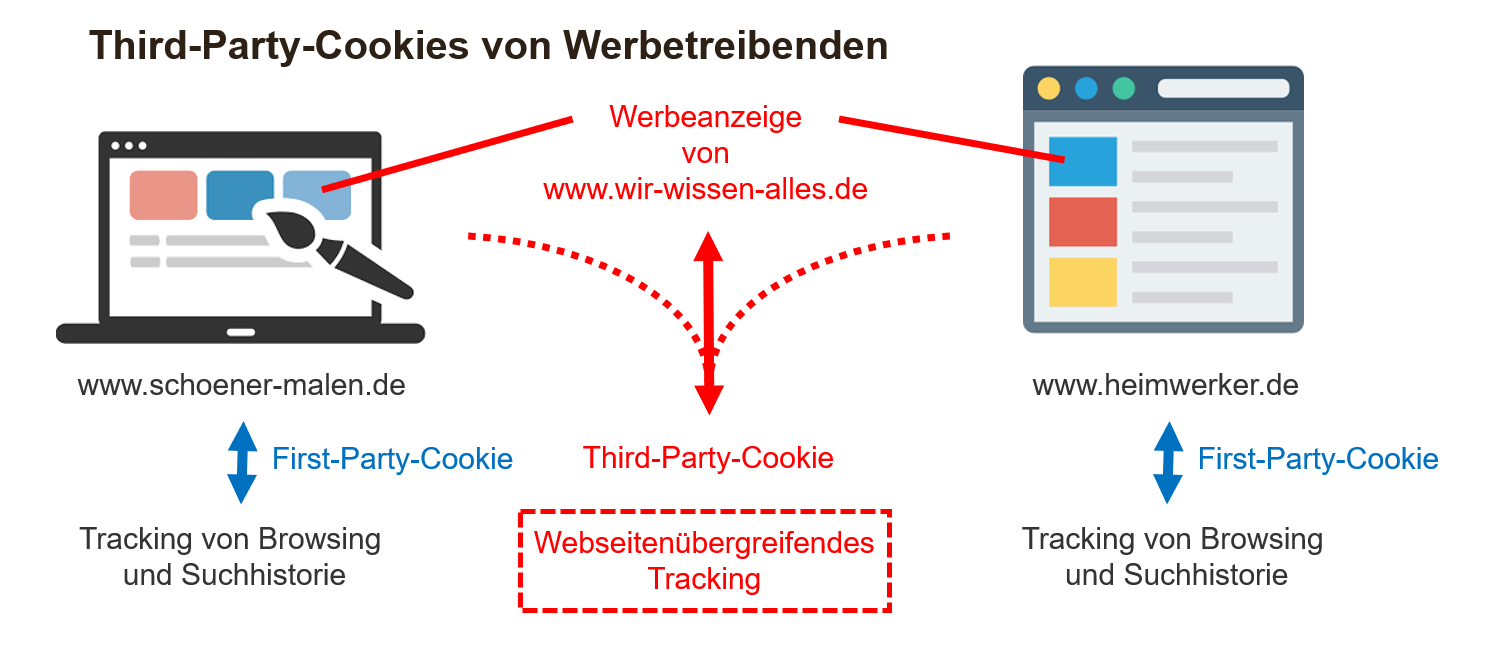
Datenschutz und Sicherheit
Daher sind Cookies auch ein umstrittenes Thema im Hinblick auf Datenschutz und Sicherheit. Einerseits ermöglichen sie die Personalisierung von Webseiten und die Verbesserung der Benutzererfahrung, andererseits können sie auch zur Überwachung und Profilbildung der Benutzer verwendet werden, was Datenschutzbedenken aufwirft. Deshalb gibt es in der EU die Cookie-Richtlinie, die die Verwendung von Cookies regelt und den Benutzern die Kontrolle über die Verwendung von Cookies gibt. Aufgrund dieser Richtlinie müssen Webseiten den Benutzern die Möglichkeit geben, der Verwendung von Cookies zuzustimmen oder sie abzulehnen.
Löschen von Cookies
Benutzer können Cookies in ihrem Browser löschen, um ihre Spuren im Internet zu entfernen und ihre Privatsphäre zu schützen. Die meisten Browser bieten die Möglichkeit, Cookies selektiv oder alle auf einmal zu löschen. Dies kann in den Einstellungen des Browsers oder über spezielle Erweiterungen oder Add-Ons erfolgen.
Aufgabe
Im Folgenden sollen sie sich ein Bild machen, wieviele Cookies und welche Informationen darin gespeichert sind.
- Öffnen sie die Google Startseite in ihrem Browser https://www.google.de/
- Öffnen sie die Cookie-Informationen ihres Browsers
- Google Chrome: Tastenkombination
F12und dannSpeicher>>Cookies - Mozilla Firefox: Tastenkombination
UMSCHALT+F9 - Microsoft Edge: Tastenkombination
F12und dannSpeicher>>Cookies
- Google Chrome: Tastenkombination
- Öffnen sie die Cookie-Details von
www.google.dean
Bis wann sind die Cookies gültig?
Die Gültigkeit der Cookies ist unterschiedlich und hängt von den Einstellungen des Servers und des Browsers ab. Zum Zeitpunkt der Erstellung dieses Dokuments (Dez 2024) haben die Cookies auf der Google-Startseite eine Gültigkeit von einem halben Jahr.
Dies zeigt, dass Cookies eine lange Lebensdauer haben können, da mit ihrer Hilfe i.d.R. über einen längeren Zeitraum Informationen über den Webseitennutzer gespeichert werden.
Best Practices für Browsernutzung
- Aktualisieren Sie Ihren Browser regelmäßig: Halten Sie Ihren Browser auf dem neuesten Stand, um die neuesten Sicherheitsupdates und Funktionen zu erhalten.
- Verwenden Sie sichere Passwörter: Verwenden Sie sichere Passwörter, um Ihr Konto und Ihre Daten zu schützen.
- Verwenden Sie HTTPS: Verwenden Sie HTTPS, um die Sicherheit Ihrer Verbindung zu gewährleisten und die Übertragung sensibler Daten zu schützen.
- Verwenden Sie sichere Verbindungen: Vermeiden Sie unsichere WLAN-Verbindungen und verwenden Sie VPNs, um Ihre Verbindung zu schützen.
- Verwenden Sie sichere Erweiterungen: Verwenden Sie nur vertrauenswürdige Erweiterungen und Add-Ons, um die Sicherheit Ihres Browsers zu gewährleisten.
- Verwenden Sie sichere Einstellungen: Überprüfen Sie die Sicherheitseinstellungen Ihres Browsers und passen Sie sie an Ihre Bedürfnisse an.
- Verwenden Sie sichere Cookies: Verwenden Sie nur sichere Cookies und löschen Sie regelmäßig alte Cookies, um Ihre Privatsphäre zu schützen.
- Schließen Sie nicht benötigte Tabs: Schließen Sie nicht benötigte Tabs und Fenster, um die Leistung Ihres Browsers zu verbessern und Speicherplatz freizugeben.
- Löschung von Verlaufsdaten: Löschen Sie regelmäßig Ihren Browserverlauf, um Ihre Privatsphäre zu schützen und Speicherplatz freizugeben.
- Ausloggen aus Konten: Melden Sie sich immer aus Ihren Konten ab, wenn Sie den Browser verlassen, um Ihre Daten zu schützen und personalisiertes Profiling zu reduzieren.
WICHTIG
AUCH AUF DEM HANDY !!!
Suchmaschinen
Aufgrund der Vielzahl von Webseiten und der Menge an Informationen, die im Internet verfügbar sind, sind Suchmaschinen ein unverzichtbares Werkzeug für die Navigation im Internet. Hierbei werden dem Benutzer anhand von gegebenen Schlagworten oder Suchbegriffen relevante Webseiten vorgeschlagen und z.T. Informationen aus diesen direkt angezeigt. Um dies zu ermöglichen, müssen Suchmaschinen das Internet durchsuchen und indexieren, d.h. die Inhalte von Webseiten analysieren und in einer Datenbank speichern.
Der Prozess der Suche und Indexierung wird von speziellen Programmen, sogenannten Crawlern oder Spidern, durchgeführt, die das Internet nach neuen Inhalten durchsuchen und diese in die Datenbank der Suchmaschine aufnehmen. Hierbei werden bereits bekannte Webseiten regelmäßig auf Änderungen überprüft und neue Webseiten (z.B. aufgrund von Links von bekannten Webseiten) hinzugefügt, um sicherzustellen, dass die Datenbank aktuell und vollständig ist. Dies geschieht in der Regel automatisch und kontinuierlich, um sicherzustellen, dass die Suchergebnisse immer auf dem neuesten Stand sind.
Für eine gegebene Suchanfrage werden dann die relevantesten Ergebnisse aus dieser Datenbank zurückgegeben. Hierfür werden sogenannte Ranking-Algorithmen verwendet, die die Relevanz der Ergebnisse anhand verschiedener Kriterien bewerten und sortieren. Dies geschieht in der Regel in Bruchteilen von Sekunden und ermöglicht es den Benutzern, schnell und effizient Informationen zu finden.

Weiterführende Informationen
Weitere Details zu Suchmaschinen und im speziellen wissenswertes zur Google Suchmaschine findet sich auf der Seite Wie funktioniert eine Suchmaschine von XOVI.
Meta-Suchmaschinen
Meta-Suchmaschinen sind Suchmaschinen, die die Ergebnisse mehrerer Suchmaschinen kombinieren und dem Benutzer eine umfassendere und vielfältigere Auswahl an Ergebnissen bieten. Dies kann dazu beitragen, dass der Benutzer eine breitere Palette von Informationen erhält und nicht nur auf die Ergebnisse einer einzelnen Suchmaschine beschränkt ist.
Marktanteile von Suchmaschinen
Historisch gesehen gab es vor 2000 eine Vielzahl von Suchmaschinen, die um Marktanteile konkurrierten.
Mit dem Aufstieg von Google in den 2000er Jahren hat sich der Markt jedoch stark konsolidiert, und Google hat heute einen Marktanteil von über 90% in vielen Ländern. Dies hat dazu geführt, dass Google zu einer der dominantesten und einflussreichsten Suchmaschinen der Welt geworden ist und einen erheblichen Einfluss auf die Art und Weise hat, wie Menschen Informationen im Internet finden und welche sie konsumieren.
Mögliche Probleme
Grundlegend müssen Suchmaschinen mit Bedacht und Vorsicht genutzt werden, um die Qualität und Relevanz der Ergebnisse zu gewährleisten und die eigenen Daten und Privatsphäre zu schützen. Hinter (fast) jeder Suchmaschine steht ein Unternehmen und somit ein Geschäftsmodell, das darauf abzielt, die Suche bzw. Suchergebnisse zu monetarisieren und die Benutzerdaten zu nutzen, um personalisierte Werbung zu schalten oder andere Dienste anzubieten.
Getreu dem Motto “No free lunch”, sollte man immer darüber nachdenken, wie sich scheinbar kostenlose Services (wie Suchmaschinen) eigentlich finanzieren. Denn die kontinuierliche Verbesserung und Bereitstellung einer Suchmaschine ist mit erheblichen Kosten verbunden (STROM, Hardware, Personal, …), die irgendwie gedeckt werden müssen. Somit zahlt man bei Benutzung ggf. nicht direkt mit Geld, sondern mit seinen Daten und seiner Aufmerksamkeit bzw. wird gezielt zu Produkten/Dienstleistungen von Dritten geleitet, die mit dem Suchmaschinenbetreiber kooperieren.
Daher sind die Hauptrisiken und Probleme bei der Nutzung von Suchmaschinen:
- Filterblase: Suchergebnisse werden z.T. eingeschränkt und “personalisiert”, dass Benutzer nur Informationen sehen, die ihren Interessen und Ansichten entsprechen, was zu einer “Filterblase” und einseitiger Informationsgewinnung führen kann.
- Datenschutz: Suchmaschinen können Informationen über das Suchverhalten der Benutzer sammeln und speichern, was Datenschutzbedenken aufwirft.
- Zensur: Suchmaschinen können Ergebnisse filtern oder zensieren, was zu einer eingeschränkten Informationsfreiheit führen kann.
- Manipulation: Suchmaschinen können Ergebnisse manipulieren oder beeinflussen, um bestimmte Interessen zu fördern oder zu unterdrücken.
Geht’s auch ohne Google?
Mit dieser Frage beschäftigen sich die Autoren der Plattform “Digital Courage” in ihrem Artikel
GPTs und LLMs als Suchmaschinen
In den letzten Jahren haben sich auch neue Ansätze für die Suche und das Auffinden von Informationen im Internet entwickelt, die auf künstlicher Intelligenz und maschinellem Lernen basieren. Ein Beispiel hierfür sind Generative Pre-trained Transformer (GPT)-Modelle und Large Language Models (LLM), die darauf abzielen, natürliche Sprache zu verstehen und zu generieren und komplexe Suchanfragen zu verarbeiten. Beispiele hierfür sind OpenAI’s ChatGPT oder Google’s BERT.
Um dies zu ermöglichen, werden riesige Mengen an Textdaten verwendet, um die Modelle zu trainieren und ihnen beizubringen, natürliche Sprache zu verstehen und zu generieren. Dies umfasst Texte aus dem Internet, Büchern, Artikeln, Foren, sozialen Medien und anderen Quellen, um ein umfassendes Verständnis der menschlichen Sprache und des Wissens zu entwickeln.
Im Gegensatz zur klassischen Suchmaschine, welche relevante Dokumente von Dritten zu einer Suchanfrage liefert, zielen GPTs und LLMs darauf ab, direkte Antworten auf komplexe Fragen zu liefern und natürliche Dialoge mit den Benutzern zu führen. Dies kann dazu beitragen, dass Benutzer schnell und effizient Informationen finden und komplexe Fragen beantwortet bekommen, ohne auf mehrere Suchergebnisse klicken zu müssen.
Einige der Vorteile von GPTs und LLMs als Suchmaschinen sind:
- Natürliche Sprachverarbeitung: Die Fähigkeit, natürliche Sprache zu verstehen und zu generieren, ermöglicht es Benutzern, komplexe Fragen zu stellen und direkte Antworten zu erhalten.
- Effizienz: Durch die direkte Beantwortung von Fragen können Benutzer schnell und effizient Informationen finden, ohne auf mehrere Suchergebnisse klicken zu müssen.
- Personalisierung: Durch das Verständnis der Benutzeranfragen können GPTs und LLMs personalisierte Antworten und Empfehlungen liefern, die auf den individuellen Bedürfnissen und Interessen der Benutzer basieren.
ABER …
Gerade die Personalisierung und die direkte Beantwortung von Fragen durch GPTs und LLMs kann auch zu Problemen führen:
- Einseitige Informationsgewinnung: Durch die direkte Beantwortung von Fragen können Benutzer nur eine begrenzte Auswahl an Informationen erhalten, was zu einer einseitigen Informationsgewinnung führen kann. Der Effekt einer Filterblase (wie bei Suchmaschinen) kann hierdurch noch verstärkt werden.
- Fehlinformationen: Da die Modelle auf riesigen Textdaten trainiert werden, können sie auch Fehlinformationen und Vorurteile enthalten und weiterverbreiten.
- Manipulation: Die Modelle können auch (durch Selektivität bei der Zusammenstellung der Trainingsdaten) manipuliert oder beeinflusst werden, um bestimmte Interessen zu fördern oder zu unterdrücken.
- Datenschutz: Die Verwendung von GPTs und LLMs erfordert z.T. (je nach Aufgabe) den Upload von Informationen und Daten, was Datenschutzbedenken aufwerfen kann.
- Abhängigkeit von großen Unternehmen: Die Modelle werden von großen Unternehmen wie OpenAI oder Google entwickelt und betrieben, was zu einer Abhängigkeit von diesen Unternehmen führen kann.
- Begrenzte Aktualität: Die Qualität und vor allem Aktualität der Antworten hängt stark von den Trainingsdaten ab, was zu Problemen führen kann, wenn die Daten veraltet sind oder nicht aktualisiert werden.
Zusammenfassung
- Browser sind komplexe Programme, die viele Funktionen und Dienste integrieren, um Benutzern das Surfen im Internet zu ermöglichen.
- Webseiten bestehen aus HTML, CSS und JavaScript, welche die Struktur, das Design und die Interaktivität der Seiten definieren.
- Cookies speichern webseitenspezifisch Informationen auf dem Gerät des Benutzers, um Einstellungen und Präferenzen zu speichern.
- Mit Hilfe von Cookies, JavaScript und anderen Technologien können Webseiten Benutzerdaten sammeln und verarbeiten.
- Suchmaschinen sind spezialisierte Dienste, die Benutzern helfen, Informationen im Internet zu finden, indem sie relevante Dokumente zu einer Suchanfrage liefern.
- Einseitige Informationen (durch Personalisierung), Datenschutz, Zensur und Manipulation sind Hauptrisiken und Probleme bei der Nutzung des Internets.
Einordnung im Datenlebenszyklus
Browser und das Suchen und Finden von Informationen im Internet sind eng mit allen Phasen des Datenlebenszyklus verknüpft.
Einen besonderen Einfluss haben sie jedoch in den Phasen Planning und Generating, denn bei der Planung und Generierung/Sammlung von Daten und Informationen spielen Browser und Suchmaschinen eine wichtige Rolle. Eine unvollständige oder einseitige Datenbasis kann zu Verzerrungen und Fehlern in den späteren Phasen führen.
Content from Verschlüsselung
Zuletzt aktualisiert am 2025-08-21 | Diese Seite bearbeiten
Geschätzte Zeit: 20 Minuten
Übersicht
Fragen
- Wofür wichtig?
- Wie gehts?
- Wann einsetzen?
Ziele
- Einsatzgebiete von Verschlüsselung
- Grundprinzipien der Datenverschlüsselung
- Verschlüsselung von Daten in der Praxis
Verschlüsselung ist ein zentrales Thema beim Arbeiten mit und Versenden/Speichern von Daten, insbesondere wenn es um den Schutz sensibler Informationen geht. Im Folgenden werden wir uns mit den Grundlagen der Datenverschlüsselung befassen und deren Anwendung in verschiedenen Phasen des Datenlebenszyklus untersuchen.
Allgegenwärtig
Schon in unserem alltäglichen Leben begegnen uns Verschlüsselungstechniken, oftmals ohne dass wir es bewusst wahrnehmen. Hier ein paar Beispiele:
-
https://in URLs: Das “s” steht für “secure” und zeigt an, dass die Datenübertragung zwischen dem Browser und der Website verschlüsselt stattfindet. - Ende-zu-Ende-Verschlüsselung in Messaging-Apps wie WhatsApp oder Signal: Hierbei werden Nachrichten so verschlüsselt, dass nur der Absender und der Empfänger sie lesen können.
- Verschlüsselung von E-Mails: Viele E-Mail-Dienste bieten die Möglichkeit, E-Mails zu verschlüsseln, um den Inhalt vor unbefugtem Zugriff zu schützen. Ansonsten werden diese im Klartext übertragen, analog zu einer Postkarte.
- Verschlüsselung von Dateien: Betriebssysteme wie Windows und macOS bieten integrierte Funktionen zur Verschlüsselung von Dateien und Ordnern, um sensible Daten zu schützen.
- Passwortmanager: Diese speichern Passwörter verschlüsselt, sodass sie sicher aufbewahrt werden können.
- …
Grundlagen
Datenverschlüsselung ist ein Prozess, bei dem Informationen in eine Form umgewandelt werden, die für unbefugte Personen unlesbar ist. Die Verschlüsselung erfolgt in der Regel durch mathematische Algorithmen, die einen sogenannten “Schlüssel” (i.d.R. eine Zahl; ggf. basierend auf einem Passwort) verwenden, um die Daten zu verschlüsseln und zu entschlüsseln. Die Verschlüsselung kann auf verschiedene Arten erfolgen, abhängig von den Anforderungen an Sicherheit und Leistung.
Die wichtigsten Konzepte sind:
- Symmetrische Verschlüsselung: Hierbei wird derselbe Schlüssel zum Verschlüsseln und Entschlüsseln der Daten verwendet. Diese Art der Verschlüsselung ist in der Regel schneller und effizienter, erfordert jedoch, dass der Schlüssel sicher zwischen den Parteien ausgetauscht wird. Dies ist jedoch problematisch, wenn die Parteien sich zuvor nicht kennen, wie das z.B. beim Webseitenzugriff der Fall ist.
- Asymmetrische Verschlüsselung: Hierbei gibt es zwei Schlüssel: einen öffentlichen Schlüssel, der zum Verschlüsseln der Daten verwendet wird, und einen privaten (geheimen) Schlüssel, der zum Entschlüsseln dient. Diese Methode ermöglicht es, Daten sicher zu übertragen, denn der öffentliche Schlüssel kann frei verteilt werden, während der private Schlüssel geheim bleibt. Dies wird z.B. beim Aufbei einer verschlüsselten Webseitenkommunikation verwendet.
- Hash-Funktionen: Diese erzeugen aus den Daten einen eindeutigen Hash-Wert, der nicht umkehrbar ist. Hash-Funktionen werden häufig zur Überprüfung der Integrität von Daten verwendet (z.B. SHA-256). Da der Hash-Wert i.d.R. viel kleiner ist als die ursprüngliche Information, können damit einige Validierungstricks ohne viel Datenvolumen vorgenommen werden.
Hier noch ein paar mehr Details.
Symmetrische Verschlüsselung
Wenn sie z.B. eine Datei verschlüsseln oder eine verschlüsselte ZIP oder PDF Datei erhalten haben, müssen sie das korrekte Passwort eingeben, um die Daten wieder lesen zu können. Hierbei kommt symmetrische Verschlüsselung zum Tragen, d.h. beim Verschlüsselungsprozess wurde ein Passwort X festgelegt, und beim Entschlüsseln muss das gleiche Passwort X wieder angeben werden.
Derartige Verschlüsselungstechniken wurden auch schon lange vor dem “Computerzeitalter” in mechanischer Form oder in einfachen Buchstabenverschiebesystemen verwendet. Aktuelle komplexere mathematische Ansätze erhöhen die Schwierigkeit, mit der der Kodierungsansatz identifiziert und neutralisiert werden kann. Das Grundkonzept bleibt jedoch das gleiche.
Und das Grundproblem auch, denn wenn ich symmetrische Verschlüsselung bei der Übertragung von Information verwenden will, müssen beide Kommunikationspartner den Schlüssel kennen! Hierzu müssen sie sich i.d.R. treffen, um diesen persönlich auszutauschen oder ein anderer (sicherer, d.h. verschlüsselter) Kommunikationsweg muss hierfür verwendet werden.
Dies ist aber bei vielen Übertragungen nicht möglich. So auch bei der allgegenwärtigen Kommunikation von ihrem Browser (Computer) mit einem Webserver, wenn sie sich z.B. diese Webseite hier anschauen. Wenn die Datenübertragung verschlüsselt stattfinden soll, ist dies zunächst mit symmetrischen Verschlüsselungskonzepten nicht möglich. Hier kommt die asymmetrische Verschlüsselung ins Spiel.
Asymmetrische Verschlüsselung
Die asymmetrische Verschlüsselung beruht auf mathematischen Verfahren, die es ermöglichen, dass für das Verschlüsseln und das Entschlüsseln verschiedene “Passwörter”, also Schlüssel, verwendet werden.
Vereinfacht gesagt funktioniert das ganze auf einem “Empfängerprinzip”, d.h. der Empfänger ermöglicht es, das ihm kodierte Nachrichten zugesendet werden, die nur er öffnen/lesen kann.
Hierfür gibt der Empfänger seinen “Kodierungsschlüssel” öffentlich und für jeden zugreifbar bekannt. Wenn jemand diesem nun eine geheime Nachricht schicken will, dann kann diese Nachricht mit dem “Kodierungsschlüssel” unleserlich gemacht und versand werden. Niemand im Versandweg (und auch nicht der Sender!) kann die Nachricht lesen. Der Empfänger hat nun einen zweiten, geheimen Schlüssel, seinen “Dekodierungsschlüssel”, mit Hilfe dessen er die unleserliche erhaltene Nachricht wieder in seine Ursprungsform zurückversetzen kann. Solange der Empfänger seinen “Dekodierungsschlüssel” geheim hält, ist die Kommunikation sicher. Daher wird diese Art Verschlüsselung auch public-key-Verschlüsselung genannt.
Bei der Webseitenkommunikation kommt nun genau soetwas zum Tragen. Wenn ihr Browser seine (unverschlüsselte) erste Anfrage an den Webserver (= Empfänger) schickt, sendet dieser erst einmal seinen öffentlichen “Kodierungsschlüssel” zurück. Mit diesem kann ihr Browser nun dem Webserver eine geheime Nachricht schicken, die nur dieser lesen kann. Und dies kann z.B. ein Schlüssel für eine (technisch einfachere) symmetrische Kommunikation sein, da wir ja nun über einen sicheren Kommunikationskanal verfügen. Im Anschluß erfolgt die weitere verschlüsselte Kommunikation symmetrisch, da ja nun sowohl ihr Browser wie auch der Webserver den Schlüssel der symmetrischen Kommunikation kennen.
Der Ablauf ist nochmals in folgender Grafik illustriert.
Was kann schief gehen?
Gehen wir davon aus, dass sie mittels HTTPS eine Webseite besuchen und der oben beschriebene Ablauf funktioniert hat. Allerdings stellen sie kurz darauf fest, dass der angezeigte Inhalt gar nichts mit dem erwarteten Inhalt zu tun hat. Was könnte hier passiert sein?
Sie haben zwar eine verschlüsselte Verbindung zu einem Webserver aufgebaut, aber dieser Webserver ist nicht der, den sie erwartet haben. Dies kann z.B. passieren, wenn sie auf einen Phishing-Link geklickt haben, der sie zu einer gefälschten Webseite geleitet hat, die vorgibt, die echte Webseite zu sein. In diesem Fall ist die Verbindung zwar verschlüsselt, aber der Inhalt stammt nicht von der erwarteten Quelle.
Dies ist ein Beispiel dafür, dass Verschlüsselung allein nicht ausreicht, um die Sicherheit zu gewährleisten. Es ist auch wichtig, die Identität des Kommunikationspartners zu überprüfen, z.B. durch die Verwendung von Zertifikaten, die von vertrauenswürdigen Zertifizierungsstellen ausgestellt wurden. Diese Zertifikate bestätigen die Identität des Webservers und stellen sicher, dass sie tatsächlich mit dem richtigen Server kommunizieren. Wenn das Zertifikat nicht gültig ist oder nicht von einer vertrauenswürdigen Zertifizierungsstelle ausgestellt wurde, wird ihr Browser sie warnen und die Verbindung abbrechen. Dies ist ein wichtiger Sicherheitsmechanismus, um sicherzustellen, dass sie nicht Opfer von Phishing-Angriffen oder anderen Betrugsversuchen werden.
Asymmetrische public-key Verschlüsselung ist also ein zentrales Konzept, um eine sichere Kommunikation im Internet zu ermöglichen. Sie kommt neben der Webseitenkommunikation auch bei anderen Anwendungen zum Einsatz, wie z.B. bei
- E-Mail-Verschlüsselung (PGP)
- Digitale Signaturen (z.B. für Software-Downloads)
- Sicheren Dateiübertragungen (z.B. SFTP)
- SSH-Zugriff auf Server
- VPN-Verbindungen
- … und vielen anderen Anwendungen, bei denen eine sichere Kommunikation erforderlich ist.
Hashing
Hashing ist ein Verfahren, bei dem eine beliebige Datenmenge (z.B. eine Datei oder ein Text) in einen festen, eindeutigen Hash-Wert fester Länge umgewandelt wird. Dieser Hash-Wert dient als Fingerabdruck der Daten und kann verwendet werden, um die Integrität der Daten zu überprüfen. Dies ist deshalb möglich, da schon minimale Abweichungen einen anderen Hash-Wert erzeugen, so dass eine Manipulation der Daten oder Fehler sofort erkannt werden können.
Hierbei ist der zentrale Trick, dass die Hash-Funktion nicht umkehrbar ist, d.h. es ist nicht möglich, aus dem Hash-Wert die ursprünglichen Daten wiederherzustellen. Als einfachste Analogie kann man die Modulo-Operation verwenden, die den Rest bei einer Ganzzahldivision berechnet. Bei Modulo 10 würde z.B. 12 zu 2, 22 zu 2 und 32 zu 2 werden. Alle Hash-Werte sind einstellige Ziffern, aber ob diese aus einer 13- oder zwei-stelligen Zahl stammen, ist nicht mehr erkennbar. Ausserdem zeigt das Beispiel, dass es mehrere Zahlen geben kann, die den gleichen Hash-Wert ergeben (Kollisionssicherheit).
So können z.B. Passwörter in Datenbanken nicht im Klartext gespeichert werden, sondern nur deren Hash-Wert. Damit kann bei der Anmeldung eines Nutzers das eingegebene Passwort ebenfalls gehasht und mit dem gespeicherten Hash-Wert verglichen werden, ohne dass das Passwort selbst gespeichert werden muss. Hierbei ist es theoretisch möglich, dass zwei verschiedene Passwörter den gleichen Hash-Wert erzeugen (Kollision), aber dies ist bei modernen Hash-Funktionen extrem unwahrscheinlich.
Somit sind Hash-Funktionen ein wichtiges Werkzeug zur Sicherstellung der Datenintegrität und werden in vielen Anwendungen eingesetzt, wie z.B. bei der Überprüfung von Software-Downloads, der Speicherung von Passwörtern oder der digitalen Signatur von Dokumenten.
Bei der oben beschriebenen HTTPS-Kommunikation kommen u.a. auch Hash-Funktion zum Tragen, um die Integrität der übertragenen Daten zu überprüfen, d.h. um sicherzustellen, dass der Empfänger tatsächlich die Daten erhalten hat und korrekt entschlüsseln konnte.
Für häufig verwendete Hash-Funktionen, wie z.B. SHA-256 oder SHA-512, bieten die meisten Programmiersprachen und Betriebssysteme (Anleitungen) bereits fertige Implementierungen an, die einfach verwendet werden können, um z.B. schnell die Integrität eines wichtigen Dateidownloads zu überprüfen. Außerdem gibt es viele Online-Tools, die Hash-Werte für beliebige Daten oder kleinere Dateien berechnen können.
Dateiverschlüsselung
Neben den beschriebenen Einsatzgebiet der Kommunikationsverschlüsselung, werden häufig auch einzelne Dateien verschlüsselt. Dies kann z.B. notwendig sein, um sensible Daten zu schützen, die auf einem Computer oder einem Datenträger gespeichert sind oder um Daten zu übertragen, die nicht für jedermann zugänglich sein sollen. Hierbei kommen in der Regel symmetrische Verschlüsselungsverfahren zum Einsatz, bei denen ein Passwort oder ein Schlüssel verwendet wird, um die Daten zu verschlüsseln und zu entschlüsseln.
Die Verschlüsselung von Dateien kann auf verschiedene Arten erfolgen, z.B. durch die Verwendung von speziellen Software-Tools oder durch die Nutzung von Betriebssystemfunktionen. Einige gängige Tools und Methoden zur Dateiverschlüsselung sind:
- GnuPG: Ein Open-Source-Tool zur Verschlüsselung von Dateien und E-Mails, das auf dem OpenPGP-Standard basiert.
- VeraCrypt: Ein Open-Source-Tool zur Verschlüsselung von Festplatten, USB-Sticks und anderen Datenträgern, das auf dem TrueCrypt-Projekt basiert.
- 7-Zip: Ein Open-Source-Dateikomprimierungstool, das auch die Möglichkeit bietet, Dateien mit AES-256-Verschlüsselung zu verschlüsseln.
Auch bieten manche Dateiformate wie PDF oder
ZIP die Möglichkeit, Dateien direkt beim Erstellen zu
verschlüsseln. Hierbei wird in der Regel ein Passwort abgefragt, das zum
Entschlüsseln der Datei benötigt wird.
Cloudspeichernutzung
Gerade beim Speichern von sensiblen Daten in der Cloud, bietet es sich an, die Daten vor dem Hochladen zu verschlüsseln, um sicherzustellen, dass nur autorisierte Personen Zugriff auf die Daten haben. Denn je nach Cloud-Anbieter und dessen Sicherheitsvorkehrungen und AGBs, können unbefugte Dritte möglicherweise auf die Daten zugreifen, wenn sie nicht verschlüsselt sind.
Hierbei können die oben genannten Tools verwendet werden, um die Daten vor dem Hochladen zu verschlüsseln. Es ist jedoch wichtig, sicherzustellen, dass das Passwort oder der Schlüssel für die Verschlüsselung sicher aufbewahrt wird, da sonst der Zugriff auf die Daten verloren gehen kann.
Datenträger
Neben der Verschlüsselung einzelner Dateien kann auch der gesamte Datenträger verschlüsselt werden, um alle darauf gespeicherten Daten zu schützen. Dies ist besonders wichtig, wenn sensible Daten auf einem Laptop oder einem USB-Stick gespeichert sind, der verloren gehen oder gestohlen werden könnte. Die Verschlüsselung des gesamten Datenträgers kann verhindern, dass unbefugte Personen auf die Daten zugreifen können, selbst wenn sie physisch Zugriff auf den Datenträger haben. Hierbei kommen in der Regel symmetrische Verschlüsselungsverfahren zum Einsatz, bei denen ein Passwort oder ein Schlüssel verwendet wird, um die Daten zu verschlüsseln und zu entschlüsseln.
Worst Case
Unverschlüsselte Daten
Wenn sie sensible Daten auf einem Computer oder einem Datenträger speichern, der nicht verschlüsselt ist, besteht das Risiko, dass unbefugte Personen auf diese Daten zugreifen können. Dies kann zu Datenverlust, Identitätsdiebstahl oder anderen schwerwiegenden Konsequenzen führen.
Unzureichende Verschlüsselung
Wenn sie eine unzureichende Verschlüsselung verwenden, z.B. ein schwaches Passwort oder einen veralteten Verschlüsselungsalgorithmus, können unbefugte Personen möglicherweise auf die Daten zugreifen. Es ist wichtig, starke Passwörter zu verwenden und aktuelle Verschlüsselungsalgorithmen zu verwenden, um die Sicherheit der Daten zu gewährleisten. Ein schwaches Passwort kann leicht erraten oder durch Brute-Force-Angriffe geknackt werden, was die Sicherheit der verschlüsselten Daten gefährdet.
Verschlüsselung als Angriff
Es gibt auch Angriffe, bei denen die Verschlüsselung selbst als Waffe eingesetzt wird. Ein Beispiel hierfür ist die sogenannte “Ransomware”, bei der Angreifer die Daten eines Opfers verschlüsseln und dann ein Lösegeld verlangen, um den Schlüssel zur Entschlüsselung bereitzustellen. In solchen Fällen ist es wichtig, regelmäßige Sicherungskopien der Daten zu erstellen, um im Falle eines Angriffs die Daten wiederherstellen zu können. Derartige Angriffe können verheerende Auswirkungen sowohl auf Unternehmen als auch auf Einzelpersonen haben, da sie den Zugriff auf wichtige Daten und Systeme blockieren und erhebliche finanzielle Verluste verursachen können.
Verschlüsselung vergessen
Wenn sie eine Datei oder einen Datenträger verschlüsseln, aber das Passwort oder den Schlüssel vergessen, können sie möglicherweise nicht mehr auf die Daten zugreifen. Dies kann zu einem dauerhaften Datenverlust führen, insbesondere wenn keine Sicherungskopien der Daten vorhanden sind. Es ist daher wichtig, Passwörter und Schlüssel sicher zu speichern und regelmäßig Sicherungskopien der verschlüsselten Daten zu erstellen.
Gerade bei der Verschlüsselung von Datenträgern ist es wichtig, dass sie sich das Passwort gut merken oder es an einem sicheren Ort aufbewahren. Hierbei kann ein Passwortmanager helfen, der Passwörter sicher speichert und verwaltet.
Quantencomputer
Die Sicherheit der meisten aktuellen Verschlüsselungsverfahren basiert auf der Annahme, dass bestimmte mathematische Probleme für klassische Computer schwer zu lösen sind. Allerdings könnte die Entwicklung von Quantencomputern diese Annahme in Frage stellen. Quantencomputer können bestimmte mathematische Probleme viel schneller lösen als klassische Computer, was bedeutet, dass sie in der Lage sein könnten, viele der derzeit verwendeten Verschlüsselungsalgorithmen zu knacken. Dies könnte zu einem Paradigmenwechsel in der Kryptographie führen, da neue, quantensichere Verschlüsselungsalgorithmen entwickelt werden müssen, um die Sicherheit der Daten zu gewährleisten. Es ist jedoch wichtig zu beachten, dass Quantencomputer noch in der Entwicklungsphase sind und es noch einige Jahre dauern könnte, bis sie in der Lage sind, aktuelle Verschlüsselungsverfahren zu gefährden. In der Zwischenzeit ist es wichtig, weiterhin starke Verschlüsselungsalgorithmen zu verwenden und regelmäßig Sicherheitsupdates durchzuführen, um die Sicherheit der Daten zu gewährleisten.
Die Wissenschaftliche Arbeitsgruppe Nationaler Cyber-Sicherheitrat schätzt in ihrem Impulspapier “Quantencomputer und ihr Einfluß auf die Cybersicherheit” (März 2024) symmetrische Verschlüsselungsverfahren wie AES-256 als “quantensicher” ein, da sie auch von Quantencomputern nicht in akzeptabler Zeit geknackt werden können. Allerdings liefert sie auch dringende Empfehlungen, dass asymmetrische Verschlüsselungsverfahren wie RSA und ECC in den nächsten Jahren auf quantensichere Verfahren umgestellt werden sollten.
Passwortmanager
Ein Passwortmanager ist ein Tool, das hilft, Passwörter sicher zu speichern und zu verwalten. Er kann auch dabei helfen, starke Passwörter zu generieren und automatisch in (Web)Anwendungen einzufügen. Dies ist besonders nützlich, um die Sicherheit der Passwörter zu erhöhen und das Risiko von Passwortdiebstahl zu verringern, da so deutlich komplexere Passwörter verwendet werdeb können, die schwer zu erraten sind.
In Webbrowsern gibt es mittlerweile viele integrierte Passwortmanager, die Passwörter für Websites speichern und automatisch ausfüllen können. Es gibt aber auch eigenständige Passwortmanager, die zusätzliche Funktionen bieten, wie z.B.
- die Möglichkeit, Passwörter für verschiedene Anwendungen und Dienste zu speichern,
- die Synchronisierung von Passwörtern über verschiedene Geräte hinweg,
- die Generierung von starken Passwörtern,
- die Möglichkeit, Passwörter zu teilen oder gemeinsam zu nutzen,
- die Überprüfung der Sicherheit von Passwörtern und
- die Möglichkeit, Passwörter zu kategorisieren und zu organisieren.
Einige beliebte Passwortmanager sind:
- Bitwarden: Ein Open-Source-Passwortmanager, der eine kostenlose Version mit vielen Funktionen anbietet. Er bietet eine benutzerfreundliche Oberfläche und die Möglichkeit, Passwörter zu generieren, zu speichern und automatisch auszufüllen.
- KeePass: Ein Open-Source-Passwortmanager, der lokal auf dem Computer installiert wird und eine sichere Speicherung von Passwörtern ermöglicht. Er bietet viele Funktionen, wie z.B. die Möglichkeit, Passwörter zu generieren, zu speichern und zu organisieren. KeePass ist besonders beliebt bei Nutzern, die Wert auf Datenschutz und Sicherheit legen, da die Passwörter lokal gespeichert werden und nicht in der Cloud.
- 1Password: Ein kostenpflichtiger Passwortmanager, der eine benutzerfreundliche Oberfläche und viele Funktionen bietet, wie z.B. die Möglichkeit, Passwörter zu teilen und gemeinsam zu nutzen.
- LastPass: Ein beliebter Passwortmanager, der sowohl eine kostenlose als auch eine kostenpflichtige Version anbietet. Er bietet viele Funktionen, wie z.B. die Möglichkeit, Passwörter zu generieren, zu speichern und automatisch auszufüllen.
- Passbolt: Ein Open-Source-Passwortmanager, der speziell für Teams und Unternehmen entwickelt wurde. Er bietet Funktionen wie die gemeinsame Nutzung von Passwörtern, die Verwaltung von Benutzerrechten und die Integration in verschiedene Anwendungen.
Allerdings muss der Passwortmanager selbst sicher sein, da er die sensibelsten Informationen über sie enthält. Daher ist es wichtig, einen vertrauenswürdigen Passwortmanager zu wählen und sicherzustellen, dass er starke Verschlüsselungstechniken verwendet, um die gespeicherten Passwörter zu schützen und dass er regelmäßig aktualisiert wird, um Sicherheitslücken zu schließen.
Es ist auch wichtig, ein starkes Master-Passwort für den Passwortmanager zu wählen, da dieses Passwort der Schlüssel zu allen anderen Passwörtern ist. Ein schwaches Master-Passwort kann dazu führen, dass unbefugte Personen Zugriff auf den Passwortmanager und damit auf alle gespeicherten Passwörter erhalten. Daher sollte das Master-Passwort lang, komplex und einzigartig sein, um die Sicherheit des Passwortmanagers zu gewährleisten und das Risiko von Passwortdiebstahl zu minimieren. Ggf. bietet es sich an, das Master-Passwort ebenfalls in einem Passwortmanager einer Person ihres Vertrauens zu speichern, um es nicht zu vergessen (und vice versa).
Zusammenfassung
- Verschlüsselung ist ein zentrales Konzept zum Schutz sensibler Daten.
- Symmetrische und asymmetrische Verschlüsselung sind die beiden Hauptarten der Datenverschlüsselung.
- Public-Key-Verschlüsselung ermöglicht eine sichere Kommunikation, ohne dass ein geheimer Schlüssel vorher ausgetauscht werden muss.
- Hash-Funktionen sind wichtig für die Integrität von Daten.
- Die Verschlüsselung von Dateien und Datenträgern ist wichtig, um sensible Daten zu schützen.
- Quantencomputer könnten die Sicherheit aktueller Verschlüsselungsverfahren in Frage stellen, aber symmetrische Verfahren wie AES-256 gelten als quantensicher.
- Passwortmanager helfen, Passwörter sicher zu speichern und zu verwalten und vor allem starke Passwörter zu verwenden.
Einordnung im Datenlebenszyklus
Das Wissen um Verschlüsselung ist immer dann zentral, wenn Daten verschickt oder auf unsicheren Datenträgern gespeichert werden. Auch strenge Datenschutzbestimmungen können Verschlüsselung notwendig machen.
- Erhebung: Sensible Daten müssen verschlüsselt werden
- Analyse: Falls Daten geteilt werden, müssen Schlüssel sicher ausgetauscht werden
- Nachnutzung: Bereitstellung von sensiblen, verschlüsselten Daten nach Absprache
Content from Datenverarbeitung
Zuletzt aktualisiert am 2025-09-04 | Diese Seite bearbeiten
Geschätzte Zeit: 25 Minuten
Übersicht
Fragen
- Reproduzierbar?
- Dokumentiert?
- Skalierbar?
Ziele
- Gründe für den Einsatz von Workflow-Systemen und Skriptsprachen
- Verständnis von Pipelines und deren Aufbau
- Was, wenn der eigene Rechner nicht mehr reicht?
Datenverarbeitung ist der Kernpunkt jedes Forschungsprozesses. In dieser Sitzung werden wir uns mit grundlegenden Aspekten der Datenverarbeitung im Kontext des Forschungsdatenmanagements (FDM) beschäftigen. Hierbei liegt der Fokus auf der Bedeutung von Workflow-Systemen, Skriptsprachen und Pipelines für die effiziente und reproduzierbare Arbeitsabläufe.
Bevor wir starten, hier ein kleines fiktives Beispiel, um die Relevanz der Themen zu verdeutlichen:
Sie verspüren heute einen unbändigen Tatendrang und möchten Daten zu Blütenformen analysieren.
Nach kurzer Recherche finden sie den Iris-Datensatz, der Informationen zu verschiedenen Iris-Arten und deren Blütenmerkmalen enthält. Dieser Datensatz ist in einer CSV-Datei im Zenodo Datenrepositorium verfügbar, und sie laden ihn sofort herunter.

Da sie lieber im TSV-Format arbeiten, konvertieren sie die Datei mit einem Texteditor mit Hilfe der “Finden und Ersetzen”-Funktion in das gewünschte Format. Ausserdem löschen sie die Kopfzeile mit den Spaltennamen, da sie diese nicht benötigen.
Nun möchten sie die Daten analysieren. Die erste Frage, die sich aufdrängt, ist, wieviele verschiedene Iris-Arten im Datensatz enthalten sind. Hierfür erinnern sie sich an die “Spaltenselektion”-Funktion ihres Texteditors (Alt-Taste (Windows/Linux) bzw. Befehlstaste (Mac) gedrückt halten und dann die Maus ziehen) und extrahieren die Spalte mit den Artennamen. Diese kopieren sie in eine neue Datei und verwenden die “Duplikate entfernen”-Funktion ihres Texteditors, um die einzigartigen Arten zu identifizieren. Wunderbar, es sind genau drei Arten, wie erwartet.
Danach bearbeiten sie die Daten weiter mit einer Kombination aus Texteditor und Tabellenkalkulationsprogramm, um herauszufinden,
- Wieviele Datensätze gibt es pro Art?
- Wie sind die durchschnittlichen Blütenmaße pro Art?
- Wie verteilen sich die Datenpunkte der Sepalblätter in einem Streudiagramm coloriert nach Art?
Am Ende ihres Arbeitstages sind sie zufrieden mit den Ergebnissen, aber auch etwas erschöpft. Sie haben sich auf einem Blatt Papier die Ergebniszahlen notiert und die Grafik ausgedruckt.
Und nun?
Ein paar Tage später sprechen sie mit Freunden über ihre Analyse und holen ihre Notizen und den Ausdruck.
Was könnte nun das Problem sein?
- Nicht nachvollziehbar: Leider sind sie sich nicht mehr sicher, welche Zahl auf ihren Notizen welche Art repräsentiert.
- Nicht reproduzierbar: Der Hamster hat den halben Ausdruck gefressen, aber sie wissen nicht mehr genau, wie sie die Grafik erstellt haben.
- Fehleranfällig: Beim Kopieren der Daten in den Texteditor haben sie versehentlich eine Zeile gelöscht, was die Ergebnisse verfälscht. Bzw. beim Notieren der Ergebniszahlen hatten sie einen Zahlendreher.
- Zeitaufwand: Die manuelle Bearbeitung der Daten hat viel Zeit in Anspruch genommen, die sie lieber in die Interpretation der Ergebnisse investiert hätten.
- Fehlende Skalierbarkeit: Sie möchten die Analyse auf einen größeren Datensatz anwenden, aber die manuelle Methode ist nicht praktikabel für größere Datenmengen.
Ziele guter Datenverarbeitung
Gute Datenverarbeitung sollte folgende Ziele verfolgen:
- Reproduzierbarkeit: Andere (oder sie selbst zu einem späteren Zeitpunkt) sollten die Analyse mit den gleichen Daten und Methoden wiederholen können und zu den gleichen Ergebnissen kommen.
- Nachvollziehbarkeit: Jede Entscheidung und jeder Schritt in der Datenverarbeitung sollte dokumentiert sein, um die Analyse transparent zu machen.
- Automatisierung: Wiederkehrende Aufgaben sollten automatisiert werden, um menschliche Fehler zu minimieren und Zeit zu sparen.
- Skalierbarkeit: Die Methoden sollten auf größere Datensätze anwendbar sein, ohne dass der Aufwand exponentiell steigt.
- Portabilität: Die Analyse sollte auf verschiedenen Systemen und Umgebungen durchführbar sein, ohne dass umfangreiche Anpassungen erforderlich sind.
Reproduzierbarkeit und Nachvollziehbarkeit sind hierbei zwei zentrale Prinzipien in der wissenschaftlichen Forschung, die sicherstellen, dass Forschungsergebnisse verlässlich und überprüfbar sind.
Damit diese erreicht werden können, bedarf es entweder einer extrem umfangreichen Dokumentation oder - und das ist der bessere Weg - die Datenverarbeitung sollte mit Hilfe von Skriptsprachen und/oder Workflow-Systemen erfolgen.
Skriptsprachen
Skriptsprachen sind Programmiersprachen, die speziell für die Automatisierung von Aufgaben und die Verarbeitung von Daten entwickelt wurden. Sie ermöglichen es Forschenden, komplexe Datenverarbeitungsaufgaben durch das Schreiben von Code zu automatisieren ohne dabei spezifische Kenntnisse über computerinterne Abläufe und Strukturen haben zu müssen. Das heißt, Skriptsprachen abstrahieren viele technische Details und bieten eine benutzerfreundliche Syntax, die es auch Nicht-Programmierern ermöglicht, effektive Datenverarbeitungsprozesse zu erstellen. Zudem sind Skriptsprachen oft plattformunabhängig, was bedeutet, dass Skripte auf verschiedenen Betriebssystemen ausgeführt werden können, ohne dass sie angepasst werden müssen.
Verbreitete Skriptsprachen im Forschungsdatenmanagement sind:
- Python: Bekannt für seine Lesbarkeit und Vielseitigkeit, mit umfangreichen Bibliotheken für Datenanalyse (z.B. Pandas, NumPy).
- R: Speziell für statistische Analysen und Datenvisualisierung entwickelt, mit einer großen Community und vielen Paketen (z.B. ggplot2, dplyr).
- Bash: Eine Unix-Shell und Skriptsprache, die häufig für Systemadministration und Automatisierung von Aufgaben in Linux-Umgebungen verwendet wird.
Auch die mit der Webentwicklung verbundene Sprache JavaScript kann für Datenverarbeitungsaufgaben genutzt werden.
Wenngleich Skriptsprachen viele technische Details abstrahieren, ist es dennoch wichtig, ein grundlegendes Verständnis der zugrunde liegenden Konzepte zu haben, um effektiv und effizient arbeiten zu können.
Bei der Verwendung von Skriptsprachen muss unterschieden werden zwischen
- Interaktive Verarbeitung, bei der einzelne Befehle oder Code-Snippets in einer interaktiven, chatartigen Eingabe ausgeführt werden, um Daten zu analysieren und zu visualisieren.
- Automatisierte Verarbeitung, bei der komplette Skripte geschrieben werden, die eine Reihe von Befehlen enthalten, die nacheinander ausgeführt werden, um eine vollständige Datenverarbeitungsaufgabe zu erledigen.
Die interaktive Verarbeitung eignet sich gut für explorative Datenanalyse und schnelle Tests, hat aber die gleichen Nachteile wie die manuelle Verarbeitung. Die automatisierte Verarbeitung ist daher zu bevorzugen und eigenet sich für wiederholbare und skalierbare Aufgaben.
Einer der größten Vorteile von Skriptsprachen (im Rahmen der automatisieren Verarbeitung) ist es, dass sie direkt Dokumentation und Automatisierung verbinden und i.d.R. auch Skalierbarkeit und Portabilität unterstützen. Das heißt, ein einmal geschriebenes Skript kann immer wieder ausgeführt werden, ohne dass manuelle Schritte erforderlich sind. Zudem erlaubt das Skript einzelne Schritte und Entscheidungen zu dokumentieren, was die Nachvollziehbarkeit erhöht.
Im Folgenden haben wir das Datenverarbeitungsbeispiel von oben in einfache Python- und R-Skripte übersetzt, welche die gleichen Schritte automatisiert durchführt:
Nicht alle Schritte der Datenverarbeitung lassen sich immer einfach in Skripte übersetzen. Häufig sind mehrere Schritte notwendig, um eine vollständige Analyse durchzuführen, welche ggf. dann in verschiedenen Skriptdateien organisiert werden müssen. Allerdings ist nun die übergeordnete Reihenfolge der Einzelskripte entscheidend, um die gesamte Analyse durchzuführen. Das heißt, es entsteht eine Abhängigkeit zwischen den einzelnen Skripten und die Organisations- und Dokumentationsprobleme verschieben sich nun auf die Ebene der Verwaltung und Ausführung von Skript-Abfolgen.
An dieser Stelle kommen Workflow-Systeme und Pipelines ins Spiel, die genau diese Probleme adressieren.
Workflow-Systeme und Pipelines
Workflow-Systeme sind spezialisierte Softwarelösungen, die entwickelt wurden, um komplexe Datenverarbeitungsprozesse zu automatisieren, zu verwalten und zu dokumentieren. Sie ermöglichen es Forschenden, verschiedene Schritte der Datenverarbeitung zu definieren, zu verknüpfen und auszuführen, ohne dass sie sich um die technischen Details der Ausführung kümmern müssen. Workflows bestehen aus einer Reihe von Schritten oder Tasks, die nacheinander oder parallel ausgeführt werden können. Jeder Schritt kann ein Skript, ein Programm oder ein Tool sein, das eine spezifische Aufgabe erfüllt.
Pipelines sind eine spezielle Art von Workflows, die sich
auf die Verarbeitung von Daten in einer sequenziellen Abfolge von
Schritten konzentrieren. Pipelines sind besonders nützlich, wenn Daten
durch mehrere Verarbeitungsschritte transformiert werden müssen, bevor
sie analysiert oder visualisiert werden können. Das Konzept der
Pipeline-basierten Datenverarbeitung kommt auch in vielen Skriptsprachen
vor. Hierbei erlaubt ein spezieller Pipe-Operator die Ausgabe eines
Befehls direkt als Eingabe in den nächsten Befehl weiterzureichen (z.B.
| in Bash/Shell oder |> in R, s.o.).
Beide Konzepte, Workflows und Pipelines, bieten mehrere Vorteile:
- Automatisierung: Einmal definierte Workflows können automatisch ausgeführt werden, was den manuellen Aufwand reduziert und die Effizienz erhöht.
- Dokumentation: Workflows dokumentieren die Abfolge der Verarbeitungsschritte, was die Nachvollziehbarkeit und Reproduzierbarkeit der Analyse verbessert.
- Wiederverwendbarkeit: Einmal erstellte Workflows können leicht angepasst und für ähnliche Analysen wiederverwendet werden.
- Fehlerbehandlung: Viele Workflow-Systeme bieten Mechanismen zur Fehlererkennung und -behandlung, was die Robustheit der Datenverarbeitung erhöht.
- Skalierbarkeit: Workflows können auf verschiedenen Systemen ausgeführt werden, von lokalen Rechnern bis hin zu Hochleistungsrechnern und Cloud-Umgebungen.
Hier sind einige verbreitete Workflow-Systeme und Tools zur Erstellung von Pipelines:
- Snakemake: Ein Workflow-Management-System, das auf Python basiert und sich besonders für bioinformatische Analysen eignet.
- Nextflow: Ein weiteres beliebtes Workflow-Tool, das die Ausführung von verschiedenen Umgebungen unterstützt, einschließlich Cloud-Computing.
- Galaxy: Eine webbasierte Plattform, die es ermöglicht, Datenanalysen über eine grafische Benutzeroberfläche durchzuführen und Workflows zu erstellen, ohne dass Programmierkenntnisse erforderlich sind.
Es gibt aber auch einfache Workflow-Systeme für spezielle Anwendungsfälle, wie z.B. OpenRefine für die Datenbereinigung und -transformation.
Im Folgenden werden wir uns beispielhaft zwei dieser Tools genauer anschauen: Galaxy und OpenRefine.
Galaxy
Die Galaxy-Plattform ist ein webbasiertes Workflow-System, das speziell für die Analyse von wissenschaftlichen Daten entwickelt wurde, primär im Bereich der Life-Sciences. Galaxy bietet eine benutzerfreundliche grafische Oberfläche, die es Forschenden ermöglicht, komplexe Datenanalysen durchzuführen, ohne dass sie Programmierkenntnisse benötigen. Die Plattform unterstützt eine Vielzahl von Datenformaten und Analysewerkzeugen, die in sogenannten “Tools” organisiert sind.

Galaxy ermöglicht es Nutzern, Workflows zu erstellen, indem sie verschiedene Tools miteinander verknüpfen. Diese Workflows können gespeichert, geteilt und wiederverwendet werden, was die Zusammenarbeit und Reproduzierbarkeit von Analysen fördert. Ein weiterer Vorteil von Galaxy ist die Möglichkeit, Analysen in einer Cloud-Umgebung durchzuführen, was die Skalierbarkeit und den Zugriff auf leistungsfähige Rechenressourcen erleichtert.
Es gibt ein einführendes Tutorial für einen Workflow in Galaxy, der die Schritte aus unserem Iris-Datensatz-Beispiel automatisiert. Die darin enthaltenen Arbeitsschritte und ihre Verknüpfung zu einem Workflow können in Galaxy direkt nachvollzogen und visualisiert werden:
Der Workflow selbst, ist dabei exportierbar und kann in anderen Galaxy-Instanzen importiert und ausgeführt werden.
Da Galaxy webbasiert ist, ist keine Installation auf dem eigenen Rechner notwendig. Daten können direkt im Browser hochgeladen und analysiert werden. Allerdings benötigt das System einen Server, auf dem es läuft und einiges an Rechenleistung und Administration. Daher werden Galaxy-Instanzen häufig von Institutionen für ihre Nutzer bereitgestellt. Es gibt aber auch öffentliche Galaxy-Server, die von jedem genutzt werden können, z.B. usegalaxy.org.
OpenRefine
OpenRefine (früher Google Refine) ist eine Open-Source Desktop-Anwendung zur Datenbereinigung und -transformation, die lokal auf dem eigenen Rechner installiert wird. Sie bietet eine grafische Benutzeroberfläche, in der man große Datensätze importieren, bereinigen und untersuchen kann.
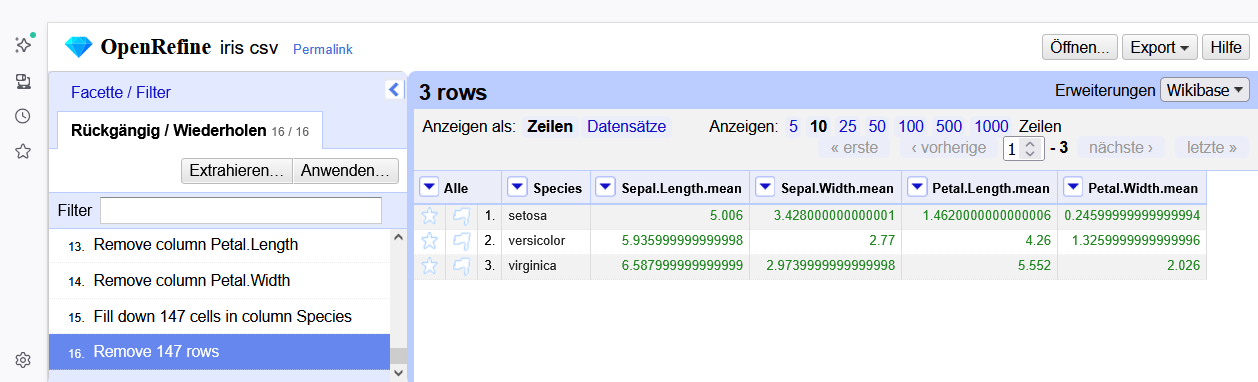
OpenRefine ist besonders nützlich für die Arbeit mit unstrukturierten oder semi-strukturierten Daten, wie z.B. CSV-Dateien, Excel-Tabellen oder JSON-Daten. Daten können hiermit einfach gefiltert, sortiert, gruppiert und transformiert werden. Es unterstützt auch die Anwendung von regulären Ausdrücken und verwendet eine eigene Skriptsprache namens GREL (General Refine Expression Language) für komplexe Datenmanipulationen, welche Ähnlichkeiten zu JavaScript aufweist.
Alle Daten und durchgeführten Schritte werden in OpenRefine in einem sogenannten “Projekt” gemeinsam verwaltet, das exportiert und später wieder importiert werden kann. Dies ermöglicht es, die Datenbereinigung nachvollziehbar zu dokumentieren und auf ähnliche Datensätze anzuwenden.
Für das Iris-Datensatz-Beispiel könnte OpenRefine wie folgt verwendet werden:
- Import der CSV-Datei in ein neues Projekt
- Transformation der Datenspalten in Zahlenformate
- Sortieren der Daten nach Spezies
- Ausblenden von Duplikaten in der Spezies Spalte
- Umschalten auf die “Datensatz”-Ansicht: ermöglicht eine Gruppierung der Daten nach Spezies (“records”)
- Anlegen von neuen Spalten für die Mittelwerte der Blütenmaße pro
Spezies
- mit GREL z.B.
row.record.cells["Petal.Width"]["value"].sum() / row.record.cells["Petal.Width"].length()
- mit GREL z.B.
- Originale Datenspalten löschen
- Spezies-Spalte wieder auffüllen
- Duplikate entfernen
Ein Nachteil von OpenRefine gegenüber Skriptsprachen und anderen Workflow-Systemen ist, dass es keine Möglichkeit bietet, das wiederkehrende Arbeitsschritte auf mehrere Spalten angewendet werden. So müssen für die Mittelwerte für die verschiedenen Blütenmaße jeweils einzelne neue Spalten angelegt und berechnet werden. Auch benötigt man i.d.R. für komplexere Datenmanipulationen wie hier Kenntnisse in GREL (oder Python), sodass OpenRefine nicht komplett ohne Programmierkenntnisse genutzt werden kann. Allerdings ist OpenRefine eine gute Wahl für die schnelle und vor allem interaktive Datenbereinigung und -transformation, insbesondere wenn die Daten nicht allzu komplex sind.
Portierbarkeit
Die Portierbarkeit von Datenverarbeitungsprozessen bezieht sich auf die Fähigkeit, diese Prozesse auf verschiedenen (Betriebs)Systemen und Umgebungen (Computern) auszuführen, ohne dass umfangreiche Anpassungen erforderlich sind. Dies ist besonders wichtig in der wissenschaftlichen Forschung, wo Datenanalysen oft auf unterschiedlichen Rechnern, in verschiedenen Institutionen oder in Cloud-Umgebungen durchgeführt werden müssen. Oder wenn verschiedene Teammitglieder mit unterschiedlichen Systemen arbeiten.
Skriptsprachen ermöglichen häufige eine hohe Portierbarkeit, da sie plattformunabhängig sind und auf verschiedenen Betriebssystemen (Windows, macOS, Linux) ausgeführt werden können. Hierbei muss auf dem jeweiligen System lediglich die entsprechende Laufzeitumgebung (der Interpreter) installiert sein. Das heißt, ein einmal geschriebenes Skript kann in der Regel ohne Änderungen auf verschiedenen Systemen ausgeführt werden, solange die benötigten Abhängigkeiten (Bibliotheken, Pakete) ebenfalls verfügbar sind.
Allerdings können Unterschiede in den Systemumgebungen, wie z.B. unterschiedliche Versionen von Bibliotheken oder (Betriebs)System-spezifische Pfade, die Portierbarkeit beeinträchtigen.
Workflow-Systeme wie Galaxy sind ebenfalls darauf ausgelegt, portabel zu sein, da die erzeugten Workflows umfangreiche Metadaten über die verwendeten Tools und Arbeitsschritte enthalten, die die Ausführung auf verschiedenen Instanzen ermöglichen. Hierbei liegt ein deutlicher Fokus darauf, das Workflows möglichst unabhängig von der zugrunde liegenden Infrastruktur sind und somit archiviert oder veröffentlicht werden können.
Ein weiterer Ansatz zur Verbesserung der Portierbarkeit ist die Verwendung von Containerisierungstechnologien wie Docker oder Singularity. Container ermöglichen es, eine komplette Softwareumgebung, einschließlich aller Abhängigkeiten und Konfigurationen, in einem isolierten Paket zu bündeln. Dies stellt sicher, dass die Datenverarbeitungsprozesse in der gleichen Umgebung ausgeführt werden, unabhängig vom Host-System. Container sind besonders nützlich, wenn komplexe Software-Stacks benötigt werden, die schwer zu installieren oder zu konfigurieren sind.
Skalierbarkeit
Skalierbarkeit bezieht sich auf die Fähigkeit eines Systems, einer Anwendung oder eines Prozesses, mit zunehmender Datenmenge oder Arbeitslast umzugehen, ohne dass die Leistung oder Effizienz erheblich beeinträchtigt wird. Im Bezug auf Datenverarbeitung bedeutet dies, dass die Methoden und Werkzeuge, die zur Analyse von Daten verwendet werden, in der Lage sein sollten, größere Datensätze entsprechend zu verarbeiten.
Skriptsprachen bieten in der Regel eine gute Skalierbarkeit, da sie auf leistungsfähigen Computern oder Servern ausgeführt werden können, die über ausreichende Ressourcen verfügen, um große Datenmengen zu verarbeiten. Das heißt, ein Skript, das auf einem lokalen Rechner mit einem kleinen Datensatz funktioniert, kann oft auch auf einem Hochleistungsrechner oder in einer Cloud-Umgebung ausgeführt werden, um größere Datensätze zu analysieren. Allerdings können Skripte, die für kleine Datensätze optimiert sind, bei größeren Datenmengen ineffizient werden, wenn sie nicht entsprechend angepasst oder optimiert werden.
Workflow-Systeme wie Galaxy sind ebenfalls darauf ausgelegt, skalierbar zu sein. Hierbei liegt der Fokus auf der Verwaltung der Ausführung von Workflows auf Hochleistungsrechnern und Cloud-Umgebungen. Die zugrundelegenden Queue- und Ressourcenmanagement-Systeme ermöglichen es, Workflows effizient zu verteilen und auszuführen, auch wenn die Datenmengen erheblich zunehmen. Dabei werden die einzelnen Schritte eines Workflows oft parallelisiert, um die Verarbeitungsgeschwindigkeit zu erhöhen und die Auslastung der verfügbaren Ressourcen zu optimieren. Diese Verwaltung geschieht dabei automatisch, ohne dass der Nutzer sich um die technischen Details kümmern muss.
Zusammenfassung
- Datenverarbeitung sollte Reproduzierbarkeit und Nachvollziehbarkeit gewährleisten
- Automatisierung, Skalierbarkeit und Portabilität sind weitere wichtige Ziele
- Skriptsprachen (z.B. Python, R, Bash) ermöglichen automatisierte und dokumentierte Datenverarbeitung
- Workflow-Systeme (z.B. Galaxy, Snakemake) helfen bei der Verwaltung und Ausführung komplexer Datenverarbeitungsprozesse
- Workflows können gespeichert/archiviert, geteilt und wiederverwendet werden
- Portierbarkeit und Skalierbarkeit sind entscheidend für die Nutzung in verschiedenen Umgebungen und bei großen Datenmengen
Einordnung im Datenlebenszyklus
Das Wissen um die digitale Repräsentation von Informationen ist immer dann zentral, wenn Daten importiert oder exportiert werden, um sicherzustellen, dass die Daten korrekt übertragen und gespeichert werden.
- Verarbeitung: Automatisierung und Dokumentation der Verarbeitungsschritte
- Publikation und Archivierung: Export von Workflows und Skripten
- Nachnutzung: Verwendung von Skripten und Workflows für ähnliche Analysen
Content from Reguläre Ausdrücke
Zuletzt aktualisiert am 2025-04-17 | Diese Seite bearbeiten
Geschätzte Zeit: 50 Minuten
Übersicht
Fragen
- Was?
- Aufbau?
- Wo?
Ziele
- Verständnis was Reguläre Ausdrücke sind
- Wissen um die Elemente von Regulären Ausdrücken
- Anwendung von Regulären Ausdrücken
Reguläre Ausdrücke sind einer der Grundpfeiler für die komplexe Textdatenprozessierung. Mit diesen kann man mit wenig Aufwand
-
nach Vorkommen von Textmustern
suchen, um diese zu
- extrahieren,
- zählen, oder
- ersetzen (mit neuen Texten oder Teilen des alten Textes).
Dabei ist unter “Textmuster” nicht ein exaktes Wort oder dergleichen zu verstehen, sondern eine Suchkodierung, welche Variabilität zulässt.
Als Einsteig ein kleines Beispiel: Wir haben die folgenden Worte
| soll gefunden werden | soll nicht gefunden werden |
|---|---|
| Frida | Fritz |
| Erna | Hugo |
| Lisa | Lino |
Die einfachste (und am wenigsten flexible) Lösung wäre es, die gesuchten Worte alle als Alternativen hintereinander in einem regulärem Ausdruck aufzulisten:
- “
Frida|Erna|Lisa” = wobei “|” für ein “ODER” steht
Wenn man reguläre Ausdrücke baut, muss man genau schauen, was die gesuchten Wörter (oder Textpassagen) gemeinsam haben. In unserem Fall enden alle gesuchten Namen mit “a”, was wir verwenden können. Was davor für Buchstaben kommen (und wieviele), ist erst einmal unerheblich, um die Worte von den nicht gesuchten zu unterscheiden. Daher könnten wir folgendes verwenden:
- “
.*a” = wobei “.” für ein beliebiges Zeichen (Buchstabe, Ziffer, Leer-, Satzzeichen, …) steht und “*” für eine beliebige Anzahl (auch 0) des vorherigen Teils (also hier “.”)
Das funktioniert, liefert aber ggf. zu viel Variabilität, was ein häufiger Fallstrick bei regulären Ausdrücken ist. Sprich sie sind zu unkonkret. In unserem Fall passt der Ausdruck auch auf: “..a”, “lala”, “Hans-Anna”, … Sie sehen das Problem? Um dieses zu umgehen, könnte man folgende Sachen machen:
- “
.+a” = wir fordern mit “+”, dass vor dem “a” mindestens ein (beliebiger) Buchstabe ist - “
[a-zA-Z]+a” = wir geben in “[]” ganz genau an, welche Buchstaben wir erlauben (hier z.B. keine Umlaute)- mit Bindestrich “
-” können wir auch Reihen angeben, z.B. “[a-d]” = a, b, c oder d
- mit Bindestrich “
- “
\w+a” = dazu könnten wir auch eine vordefinierte character class (hier\wfür Wortbuchstabe) nehmen - “
[A-Z][a-z]*a” = mit “[A-Z]” sichern wir, dass der erste Buchstabe grossgeschrieben ist und anschliessend können (da “*”) nur Kleinbuchstaben in der Wortmitte sein - … und so weiter
Das Beispiel zeigt, dass reguläre Ausdrücke ganz allgemein
(“.*a”) oder sehr präzise (“Frida|Erna|Lisa”)
sein können. Die Kunst ist es nun, den für die anstehende Aufgabe
passenden regulären Ausdruck zu erdenken. Dazu hilft einem das
beiliegende Cheatsheet, welches man sicher auch in Zukunft immer wieder
heraus holen muss.
Suche von Textmustern
Reguläre Ausdrücke werden von links nach rechts abgearbeitet und buchstabenweise abgeglichen (gematcht).
Zudem muss man wissen, dass i.d.R. das längste passende Textstück als Treffer gesucht wird. Man spricht hierbei von greedy matching.
Aufgabe
Öffnen sie den Online RegEx-Tester https://regex101.com/.
Kopieren sie die Namen aus obiger Tabelle in das Textfeld und prüfen sie, ob die bisher vorgestellten regulären Ausdrücke wirklich funktionieren.
Wichtig: Kopieren sie die regulären Ausdrücke ohne Anführungszeichen in das Suchfeld.
Ordnen sie die regulären Ausdrücke nach ihrer Spezifität (von allgemein nach spezifisch).
Ausdrücke in steigender Spezifität:
- “
.*a” (sehr allgemein, matched auch nur ein einzelnes “a”) - “
\w+a” (\wmatched auch Zahlen und Unterstriche) - “
[a-zA-Z]+a” (nur Buchstaben, keine Umlaute oder ß) - “
[A-Z][a-z]*a” (erst Grossbuchstabe, dann Kleinbuchstaben) - “
Frida|Erna|Lisa” (nur die drei Namen)
Aufbau
Reguläre Ausdrücke bestehen aus einer Aneinanderreihung von Elementen, die in einer bestimmten Reihenfolge stehen müssen. Das heißt, in den meisten Fällen beschreibt man ein Wort oder eine Wortgruppe, wobei einzelne Positionen unterschiedliche Buchstaben aufweisen können. An diesen Stellen kommen die sogenannten character classes ins Spiel, die Platzhalter für Buchstaben, Zahlen, Leerzeichen, … sind.
Damit nicht nur Wörter gleicher Länge mit einem Suchmuster gefunden werden, gibt es Quantifikatoren, die angeben, wie oft das vorherige Zeichen vorkommen soll (oder kann).
Zuletzt gibt es noch Anker, die eingrenzen, WO ein Suchmuster im Text vorkommen soll (z.B. am Anfang oder Ende eines Wortes oder der Zeile etc.).
Final können mit Gruppierungen auch Teile des gefundenen Textes extrahiert werden, um sie weiter zu verarbeiten oder um z.B. Wiederholungen im Textmuster zu beschreiben.
In normalen regulären Ausdrücken sind alle Buchstaben, die Teil des Suchmusters sind, auch Teil des Treffers/Matches. Mit Lookarounds können aber auch “Randbedingungen” definiert werden, die nicht Teil des Matches sind, aber dennoch erfüllt sein müssen. Zum Beispiel das vor einem Wort ein Leerzeichen oder Satzzeichen sein muss, aber dieses nicht Teil des Matches ist.
RegEx Magic
Die Kunst besteht nun darin, die richtigen Elemente in der richtigen Reihenfolge zu kombinieren, um das gewünschte Suchmuster zu beschreiben.
Hierbei sollte das Muster so allgemein wir nötig und so spezifisch wie möglich sein, um nur die gewünschten Treffer zu erhalten. Dies ist vor allem wichtig, wenn das Muster nur an einem kleinen Beispieldatensatz entwickelt, später aber auch auf andere Datensätze angewandt werden soll.
Elemente
Grundlegend unterscheidet man bei regulären Ausdrücken folgende Elemente:
-
character classes, d.h. Platzhalter die auf mehrere
Buchstaben matchen, z.B.
-
.= jedwedes Zeichen -
[xyz]= explizite Zeichenliste, hier “x”, “y” und “z”- auch Reihen möglich, z.B.
[3-7]= 3,4,5,6,7
- auch Reihen möglich, z.B.
-
\s= whitespaces = Platzhalter für alle unsichtbaren Zeichen, z.B. Leerzeichen, Tabulator, … -
\d= digits = Zahlen = [0-9] -
\w= (english) word = [A-Za-z0-9_] (keine Umlaute etc.!) -
Negation:
- Grossschreibung
\S,\D, .. = alles “ausser” den Zeichen der entsprechenden “kleinen Klasse”\s,\d, … -
[^xyz]= das^negiert die explizite Liste (alles ausser x,y,z)
- Grossschreibung
-
-
Quantifikatoren, d.h. wie häufig soll das
vorangehende Zeichen gematcht werden, z.B.
-
?= ein oder kein mal -
+= mindestens einmal -
*= kann mehrfach vorkommen oder gar nicht -
{..}= explizite Anzahl
-
-
Anker, d.h. wo soll der match verortet sein, z.B.
-
^= Zeilenanfang -
$= Zeilenende -
\b= Wortgrenze, z.B.er\bmatcht nur “er” am Wortende
-
-
Gruppen, d.h. Zusammenfassung von match-Teilen,
z.B.
-
(..)= Klammern werden nicht gematcht, sondern sind Markierungen - z.B. für lokale Alternativdefinition ala
(Hi|Ku)nz= Hinz oder Kunz -
\1Rückreferenzierung auf 1., 2., … vorangehende Gruppe- z.B.
(.).\1matcht aha, oho, ana, d.h. erster und letzter Buchstabe gleich
- z.B.
-
Neben den oben genannten RegEx-spezifischen
\..-Elementen gibt es auch immer noch einige Sonderzeichen
für die auch Escapes notwendig sind, z.B.
-
\tfür einen Tabulator -
\nfür Zeilenumbruch
Ausserdem müssen Zeichen, die in RegEx eine spezielle Bedeutung haben, auch escaped werden z.B.
-
\[für das normale[-Zeichen -
\\für das normale\-Zeichen -
\.für das normale.-Zeichen -
\+für das normale+-Zeichen - …
Tutorials
Wem das jetzt zu schnell oder kompakt war, oder wer noch etwas bei regulären Ausdrücken ins Schwimmen gerät, dem seien folgende Tutorials ans Herz gelegt:
- step-by-step Tutorial zu regulären Ausdrücken von regexone.com
RegEx Kreuzworträtsel
Zudem gibt es auch spielerische Ansätze, um das Lesen und Verstehen von regulären Ausdrücken zu üben.
Besuchen sie dazu die Seite:
Bis zu welchem Level kommen sie? 😎
CheatSheet
 }
}{kind=link}
{kind=link}
{kind=link}
Zusammenfassung
- Reguläre Ausdrucke kodieren Textsuchmuster mit
Variabilität in
- den vorkommenden Zeichen (positionsspezifisch)
- der Häufigkeit der Zeichen (oder Teilmuster)
- der Position des Musters im Text
- den flankierenden Texten
- Abwägung zwischen allgemein und spezifisch ist wichtig, je nach Einsatzzweck
- Cheatsheet der Elemente
Einordnung im Datenlebenszyklus
Reguläre Ausdrücke können immer dann von Nutzen sein, wenn Daten nach bestimmten Mustern oder Informationen durchsucht oder verändert werden sollen. Konkret wären folgende Phasen im Datenlebenszyklus denkbar:
- Planung: Suche nach geeigneten Daten und Dokumentationen
- Erhebung: Überblick und Validierung der Daten
- Analyse: Verarbeitung von Textdaten
Content from Datenimport
Zuletzt aktualisiert am 2025-09-05 | Diese Seite bearbeiten
Geschätzte Zeit: 10 Minuten
Übersicht
Fragen
- Häufige Probleme?
- Pfade?
Ziele
- Was geht oft schief beim Datenimport?
- Wie kann eine gute Dateiorganisation helfen?
Der Import von Daten ist oft der erste Schritt in einem Datenprojekt. Hierbei stammen die Daten häufig aus verschiedenen Quellen und liegen in unterschiedlichen Formaten vor.
Mögliche Quellen sind hierbei:
- Rohdaten aus Messgeräten
- Exportierte Daten aus Datenbanken
- Daten von Webservices (APIs)
- Daten von Webseiten (Webscraping)
- Daten von Kolleg:innen oder aus anderen (alten) Projekten
- Daten aus anderen Analyseschritten
Was kann schiefgehen?
Beim Import von Daten treten häufig Probleme auf, die den weiteren Arbeitsprozess erschweren können. Dies ist insbesondere beim Import fremder oder alter Daten der Fall, wenn die ursprünglichen Rahmenbedingungen oder Programme nicht mehr bekannt sind.
Im Folgenden gehen wir davon aus, dass sie es mit textbasierten Dateiformaten zu tun haben (z.B. CSV, TSV, JSON, XML, etc.), da diese am häufigsten zum Teilen und Archivieren von Daten verwendet werden.
Häufige Probleme beim Import solcher Dateien haben ihren Grund in der textuellen Repräsentation von Daten, die teilweise im Kapitel “Digitale Daten” besprochen wurden:
- Textkodierung: Sonderzeichen (z.B. Umlaute) werden nicht korrekt dargestellt, da eine falsche Textkodierung verwendet wird (z.B. UTF-8 statt ISO-8859-1)
-
Zeilenumbrüche: Daten werden nicht korrekt in
Zeilen aufgeteilt (z.B.
\r\nstatt\n) -
Dezimaltrennzeichen: Zahlen werden nicht korrekt
interpretiert (z.B.
1,23statt1.23) -
Feldtrennzeichen: Daten werden nicht korrekt in
Spalten aufgeteilt (z.B.
;statt,) -
Datumsformat: Datumskodierung nicht korrekt
erkannt/interpretiert (z.B.
DD.MM.YYYYstattYYYY-MM-DD), gerade bei unterschiedlichen Ländern -
Fehlende Werte: Fehlende Daten werden nicht korrekt
erkannt (z.B.
NAstatt"") -
Datentypen: Daten werden nicht korrekt als
numerisch, kategorisch oder logisch erkannt (z.B.
1stattTRUE) - Spaltennamen: Spaltennamen sind nicht aussagekräftig oder enthalten Sonderzeichen (z.B. Leerzeichen, Umlaute)
Dadurch sollte man immer vor dem Datenimport einen Blick in die Rohdaten werfen (z.B. mit einem Texteditor), um solche Probleme frühzeitig zu erkennen und zu beheben.
Auch empfiehlt es sich, gerade bei fremden Daten, das Ergebnis des Datenimports sehr genau zu überprüfen, damit keine Fehler in die weitere Analyse eingeschleust werden.
Hilfreiche Fragen
-
Aus welchem Land stammt die Datei?
- Hinweis auf Textkodierung, Dezimaltrennzeichen, Datumsformat, da diese häufig vom Betriebssystem und der eingestellten Sprache abhängen
-
Wann wurde die Datei erstellt?
- Hinweis auf Textkodierung, da ältere Dateien häufig in anderen Kodierungen vorliegen
-
Gibt es eine Dokumentation der Datei?
- Hinweis auf Datentypen, Spaltennamen, Fehlende Werte, da diese häufig in einer begleitenden Dokumentation beschrieben sind
-
Wie wurden fehlende Werte kodiert?
- Wichtig, da diese häufig unterschiedlich kodiert werden (z.B.
NA,NULL,-9999,-,unbekannt, etc.), gerade bei manuell erhobenen Daten
- Wichtig, da diese häufig unterschiedlich kodiert werden (z.B.
Auch wenn ein Dokumentation vorliegt oder der Datenimport scheinbar direkt funktioniert, empfiehlt es sich, die Datei immer mit einem Texteditor oder dergleichen zu untersuchen, um alle Fragen zu klären.
Dateiorganisation und Pfade
Ein weiteres häufiges Problem beim Datenimport betrifft die
Wiederverwendbarkeit von Skripten. Häufig werden Skripte so geschrieben,
dass der Datenimport die genaue Position der Datei auf dem eigenen
Rechner (z.B.
C:/Users/Name/Documents/Projekt/data/datei.csv)
referenziert. Derartige Pfadangaben werden als absolute
Pfade bezeichnet. Während dies eine intuitive und einfache
Lösung ist, kann die Wiederverwendbarkeit des Skripts stark
eingeschränkt sein.
Mögliche Szenarien die dazu führen können, dass ein Skript mit absoluten Pfaden nicht mehr funktioniert, sind z.B.:
- Das Skript wird weitergegeben und soll auf einem anderen Rechner ausgeführt werden.
- Die zu importierende Zieldatei und/oder das Skript werden in einen anderen Ordner verschoben.
- Das Skript soll auf ähnliche Zieldateien in anderen Ordnern angewandt werden.
In alle diesen Fällen muss der absolute Pfad im Skript angepasst werden, was zu Fehlern führen kann und den Aufwand erhöht.
Daher empfiehlt es sich, stattdessen relative Pfade
zu verwenden (z.B. data/datei.csv). Diese beziehen sich
i.d.R. auf den Arbeitsordner (working directory) der
aktuellen Sitzung der Skriptumgebung (z.B. RStudio, Jupyter, etc.).
Konkret bedeutet dies, das beim Ausführen eines Skriptes die
Skriptumgebung einen Ordner als Arbeitsordner festlegt. Dies ist häufig
der Ordner, aus dem heraus das Skript ausgeführt wird. Der Arbeitsordner
kann aber auch explizit gesetzt werden.
Alle relativen Pfadangaben innerhalb des Skriptes beziehen sich dann auf diesen Arbeitsordner.
Beispiel
Nehmen wir an, wir hätten folgende Ordnerstruktur die Messdaten aus einer Experimentreihe in Datumsordnern (mit gleichem Dateinamen) ablegt und die Analyseskripte in einem eigenen Skripteordner gesammelt werden:
projekt/
├── daten
│ └── 20250901/
│ └── messdaten.csv
│ └── 20250902/
│ └── messdaten.csv
└── skripte/
└── analyse.pyNehmen wir weiter an, dass das Skript analyse.py die
Messdaten mit einem relativen Pfad ohne Ordnerangabe, z.B. mit
pandas.read_csv("messdaten.csv"), importieren würde.
Wenn wir nun in der Skriptumgebung den Arbeitsordner auf
projekt/daten/20250901/ setzen und das Skript ausführen,
würde die Datei projekt/daten/20250901/messdaten.csv
importiert werden. Würden wir hingegen den Arbeitsordner auf
projekt/daten/20250902/ setzen, würde die dortige Datei
messdaten.csv importiert werden. Dadurch könnten wir das
gleiche Skript für die Analyse der Daten aus beiden Tagen verwenden,
ohne den Pfad im Skript anpassen zu müssen.
Zudem könnte das Skript auch problemlos auf einem anderen Rechner ausgeführt werden, solange die Ordnerstruktur beibehalten wird.
Ausserdem ermöglicht diese Ordnerstruktur eine Automatisierung der Analysen, z.B. mit einem Makefile oder einem Bash-Skript, um die Analysen für alle Datumsordner durchzuführen. Dies ist beispielhaft in folgendem Bash-Skript dargestellt:
BASH
# Wechsle ins Projektverzeichnis (ggf. via absoluten Pfad)
cd projekt
# Schleife über alle Datumsordner (relative Pfade bzgl. Projektordner)
for dir in daten/*/; do
# Ausgabe des aktuellen Datenordners
echo "Analysiere Daten in $dir"
# In Datenordner wechseln (via relativen Pfad)
# und Skript ausführen (Arbeitsverzeichnis = Aufrufordner = Datenordner)
# (relativer Pfad im Skript funktioniert, da Arbeitsverzeichnis auf
# aktuellen Datenordner gesetzt)
(cd "$dir" && python ../../skripte/analyse.py)
doneHierbei ist zu bemerken, dass auch das Bash-Skript zur
Automatisierung wiederum mit relativen Pfaden arbeitet, u.a. um das
Skript analyse.py auszuführen. Das .. verweist
hierbei auf den übergeordneten Ordner, sodass der Pfad
../../skripte/analyse.py vom aktuellen Datenordner aus auf
das Skript im skripte Ordner zeigt (“Zwei Ordner hoch und
dann ins skripte Verzeichnis”, siehe Verzeichnisstruktur
oben).
Dadurch ist das gesamte Projekt sehr flexibel und wiederverwendbar gestaltet. Es kann auf beliebig viele Daten (z.B. weitere Datumsordner) angewandt werden, ohne dass Pfade im Skript oder im Automatisierungsskript angepasst werden müssen. Ausserdem kann das gesamte Projekt problemlos auf einen anderen Rechner verschoben werden, solange die projektinterne Ordnerstruktur beibehalten wird.
Die obigen Bash-Kommandos könnten hierfür als eigenes Skript (z.B.
run_analysen.sh) im skripte Ordner gespeichert
und ausgeführt werden.
\ vs. /
In Windows werden Pfade häufig mit dem Backslash \
angegeben (z.B.
C:\Users\Name\Documents\Projekt\data\datei.csv), während in
Unix-basierten Systemen (Linux, macOS) der Forwardslash /
verwendet wird (z.B.
/home/name/dokumente/projekt/data/datei.csv). Dies kann zu
Problemen führen, wenn Skripte auf verschiedenen Betriebssystemen
ausgeführt werden sollen.
Daher empfiehlt es sich, in Skripten immer den Forwardslash
/ zu verwenden, da dieser in den meisten
Programmiersprachen und Skriptumgebungen (z.B. Python, R, Bash) auch
unter Windows unterstützt wird.
Best Practices
- Organisieren sie ihre Projektdaten in einer logischen Ordnerstruktur, um die Übersicht zu behalten und den Grundstein für relative Pfade zu legen.
- Legen sie Rohdaten, Zwischenergebnisse und Endergebnisse in separaten Ordnern ab, um Verwechslungen zu vermeiden.
- Verwenden sie in Skripten und Dokumentationen relative Pfade anstelle von absoluten Pfaden, um die Wiederverwendbarkeit zu erhöhen.
- Automatisieren sie wiederkehrende Aufgaben (z.B. Datenimport,
Datenverarbeitung) mit Skripten, um Fehler zu vermeiden und Zeit zu
sparen.
-
Vermeiden sie Kopien von Skripten und Daten
- Nutzen sie stattdessen Verlinkungen (z.B. symbolische Links) oder Automatisierungsskripte, um Redundanzen zu vermeiden.
- Verwenden sie Versionskontrolle (z.B. Git), um Änderungen an Skripten und Daten nachvollziehbar zu machen.
Zusammenfassung
- Text-basierte Datenrepräsentation kann zu Problemen beim Import
führen
- Häufige Probleme: Zeichenkodierung, Zeilenumbrüche, Trennzeichen
- Vor dem Import immer Rohdaten inspizieren (Texteditor!)
- Relative Pfade in Skripten erhöhen Wiederverwendbarkeit
- Logische Ordnerstruktur erleichtert Datenorganisation und Automatisierung
Einordnung im Datenlebenszyklus
Das Wissen um die digitale Repräsentation von Informationen ist immer dann zentral, wenn Daten importiert oder exportiert werden, um sicherzustellen, dass die Daten korrekt übertragen und gespeichert werden.
- Verarbeitung: Import von Rohdaten
- Analyse: Import von Zwischenergebnissen
- Nachnutzung: Import von (alten) Daten