Netzwerke
Zuletzt aktualisiert am 2025-08-21 | Diese Seite bearbeiten
Geschätzte Zeit: 40 Minuten
Übersicht
Fragen
- Router?
- Ports?
- Firewall?
- Logging?
Ziele
- Wie funktioniert das Internet?
- Wie finden die Daten ihr Ziel?
- Wie kann ich mich schützen?
- Wer sieht was ich im Internet mache?
Die Verwendung des Internets ist heute allgegenwärtig. Doch wie funktioniert das Internet eigentlich? Wie finden die Daten ihren Weg? Und wie kann ich mich schützen? Auf diese und ähnliche Fragen wollen wir im Folgenden eingehen.
Computernetzwerke und das Internet
Ein Computernetzwerk ist eine Ansammlung von Rechnern, die miteinander verbunden sind und Informationen austauschen können. Hierbei ist die Art der Verbindung entscheidend und diese kann sowohl kabelgebunden (z.B. via elektrischem oder Glasfaserleiter) als auch drahtlos (z.B. via Funk, Satelit, Infrarot, …) erfolgen. Kabelgebundene Verbindungen sind in der Regel schneller und sicherer, während drahtlose Verbindungen flexibler sind und keine physische Verbindung benötigen. Daher sind drahtlose Verbindungen insbesondere für mobile Geräte wie Smartphones und Tablets von Bedeutung wohingegen kabelgebundene Verbindungen in Büroumgebungen oder Rechenzentren vorherrschen bzw. Knotenpunkte im Internet miteinander verbinden.
Das Internet selbst ist ein weltweites Netzwerk von Computernetzwerken, das auf dem Internetprotokoll (IP) basiert. Das Internetprotokoll ist ein Regelwerk, das den Datenaustausch zwischen Rechnern regelt und dabei die Daten in Pakete aufteilt, die über das Netzwerk verschickt werden. Die Pakete enthalten neben den eigentlichen Daten auch Informationen über den Absender und Empfänger, sodass die Pakete ihren Weg durch das Netzwerk finden können. Die Pakete werden dabei von Routern weitergeleitet, die die Pakete anhand der Empfängeradresse an den nächsten Knotenpunkt im Netzwerk weiterleiten. Die Knotenpunkte sind dabei die Verbindungen zwischen den einzelnen Netzwerken und können sowohl kabelgebunden als auch drahtlos sein. Da Satelit, Funk und andere drahtlose Verbindungen eine (relativ) geringere Bandbreite und “Transportgeschwindigkeit” haben, werden diese in der Regel nur für die letzte Meile verwendet, also die Verbindung zwischen dem Endgerät und dem nächsten Knotenpunkt. Zwischen den Knotenpunkten werden in der Regel Glasfaserleitungen verwendet, die eine hohe Bandbreite und Geschwindigkeit haben. Um die Kommunikation zwischen Kontinenten und Ländern zu ermöglichen, werden unterseeische Kabel verwendet, welche im Folgenden visualisiert sind.
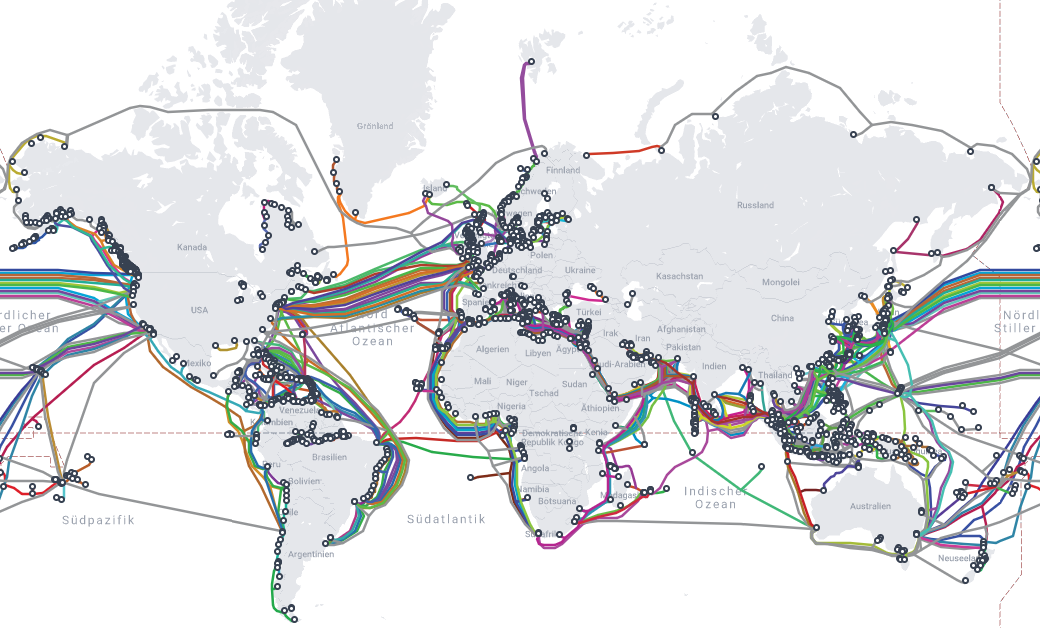
Lebensadern des Internets
Unterseeische Kabel sind die Lebensadern des Internets. Das diese dennoch anfällig sind, zeigt der Schiffsankerschaden 2019 und der Vulkansausbruch 2022 in Tonga, welche die Kommunikation des Inselstaates mit der Außenwelt unterbrachen.
Die folgenden beiden Artikel geben exemplarisch einen kurzen Einblick in die Bedeutung und Funktionsweise von Unterseekabeln:
Damit die Datenpakete ihren Weg durch das Netzwerk finden, benötigen
sie eine Adresse, die den Weg durch das Netzwerk beschreibt. Diese
Adresse ist die IP-Adresse, die aus einer Kombination von Zahlen und
Punkten besteht. Zum Beispiel hat der Server (Computer), der die
Webseite der Universität Tübingen bereitstellt, die IP-Adresse
134.2.5.1. Allerdings gibt es mehr Geräte im Internet als
es IP-Adressen gibt, sodass die IP-Adressen in der Regel dynamisch
vergeben werden (sich also immer wieder ändern) bzw. innerhalb eines
Netzwerkes lokal sind.
Um sich den Kommunikationsprozess und die IP-Lokalität vorzustellen, hier eine kleine Analogie:
- Sie machen Urlaub in einem Hotel im Zimmer Nummer 5.
- Wenn Sie eine Postkarte verschicken möchten, schreiben Sie die Zieladresse auf die Postkarte.
- Diese geben sie beim Portier in Zimmer Nummer 1 ab, der die Postkarte an den Empfänger weiterleitet.
- Hierzu verlässt der Portier das Hotel und gibt die Postkarte an den Briefträger, der diese ins Briefzentrum bringt.
- Im Briefzentrum wird die Postkarte an ein Verteilzentrum weitergeleitet, welches die Postkarte an ein Verteilzentrum in der Nähe des Empfängers weiterleitet.
- Von dort gehts ins entsprechende Briefzentrum und von dort zum Empfänger.
Das bedeutet, dass für die Weiterleitung der Postkarte mehrere Personen und Einrichtungen beteiligt sind, die die Postkarte anhand der Adresse weiterleiten, obwohl die meisten von ihnen den Zielort bzw. dessen Lokalisierung gar nicht kennen (Sie selbst, der Portier, der lokale Briefträger, …).
Wenn sie nun Post empfangen möchten, sehen sie an obiger Analogie, dass es nicht reicht, dass die Antwort an sie an Zimmer Nummer 5 adressiert wird. Ohne die Hoteladresse wird sie die Antwort nicht erreichen. Je nach Distanz bedarf es auch noch der Information über die Stadt oder sogar das Land, in dem das Hotel liegt. Zudem bedarf es des lokalen Portiers, der die Postkarte in Zimmer 1 entgegennimmt und an sie ins Zimmer 5 weiterleitet.
Ähnliches gilt auch für das Internet:
- Ihr Computer, an dem sie eine Nachricht verschicken, hat eine IP-Adresse (Zimmernummer) innerhalb ihres lokalen Netzwerkes (Hotel).
- Um eine Nachricht ins Internet zu senden, benötigen sie einen Router (Portier), der die Nachricht an den nächsten Knotenpunkt weiterleitet.
- Hierzu muss der Router sich mit dem Internet verbinden (Hotel verlassen). Diese Verbindung wird durch einen Internet Service Provider (ISP) bereitgestellt, der ihrem Router eine IP-Adresse zuweist (Hoteladresse).
- Diese ist eine andere als die IP-Adresse des Routers innerhalb ihres lokalen Netzwerkes! Der Portier lebt also in zwei Welten und hat zwei Adressen: eine innerhalb des Hotels, um für Gäste erreichbar zu sein (Zimmer 1), und eine außerhalb des Hotels (Hoteladresse), um die Post des Hotels zentral entgegen nehmen zu können.
Wie funktioniert das Internet?
Die Idee ist in folgender Grafik dargestellt, die in Blogbeitrag Wie funktioniert das Internet? näher beschrieben wird.
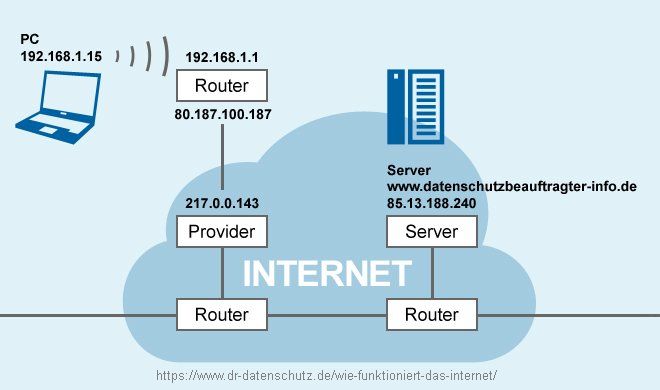
Allerdings bleibt eine Frage offen:
- Wie findet der Portier (Router) heraus, wohin die Postkarte (Datenpaket) geschickt werden soll?
Hierzu ist es nötig, dass die Postkarte auf eine bestimmte Art und Weise ausgefüllt wird, d.h. es gibt einen klaren Bereich in dem die Adresse steht. Derartige Festlegungen, wie Dinge ausgefüllt oder ausgeführt werden sollen, nennt man Protokoll. Im Falle des Internets ist ein wichtiges Protokoll das Transmission Control Protocol (TCP), welches die Kommunikation zwischen Computern regelt. Das TCP-Protokoll legt fest, wie die Datenpakete aufgebaut sind, d.h. welche Information wo steht und wieviel Platz benötigt. Das ist wichtig, weil ein Datenpaket ja eigentlich nur eine Sequenz von Binärinformation (Nullen und Einsen) ist, die von den Computern wieder zu Zahlen und Buchstaben interpretiert werden müssen. Das ist ein bischen wie beim Morsen: die Nachricht wird in eine Abfolge von kurzen und langen Signalen übersetzt, die dann wieder in Buchstaben und Zahlen zurück übersetzt werden müssen. Beim Letzteren ist entscheidend, das bekannt sein muss, wieviele Signale ein Zeichen kodieren!
Eine weitere wichtige Aufgabe des TCP ist die Segmentierung von Daten. Wenn ihre Nachricht nicht auf eine Postkarte passt, wird diese automatisch in mehrere Postkarten aufgeteilt, die dann einzeln verschickt werden. Das TCP-Protokoll sorgt dafür, dass die Postkarten (Datenpakete) in der richtigen Reihenfolge ankommen und wieder zusammengesetzt werden. Das ist wichtig, weil die Postkarten ja nicht unbedingt in der Reihenfolge ankommen, in der sie verschickt wurden.
Was sie an der obigen Analogie von Urlaubspostkarte und Webkommunikation aber auch erkennen können:
- Jeder der Beteiligten könnte die Postkarten lesen, wenn er wollte!
Das gleiche trifft auch auf das Internet zu: die Datenpakete werden von verschiedenen Knotenpunkten weitergeleitet, die die Pakete anhand der IP-Adresse an den nächsten Knotenpunkt weiterleiten. Wenn die Datenpakete unverschlüsselt sind, können die Knotenpunkte die Datenpakete lesen und ggf. manipulieren. Daher ist es i.d.R. wichtig, die Datenpakete zu verschlüsseln, um die Daten vor unbefugtem Zugriff zu schützen.
HTTPS-Verschlüsselung
Die meisten Webseiten verwenden das HTTPS-Protokoll, um die Datenpakete zu verschlüsseln. Das heisst, bevor irgendwelche Informationen/Daten zwischen ihrem Computer und dem Zielcomputer (Webserver) ausgetauscht werden, tauschen beide Computer “Schlüssel” aus, mit denen der nachfolgende Datenaustausch verschlüsselt werden.
Um das “Henne-Ei-Problem” zu lösen, da die Schlüssel ja auch übertragen werden müssen, wird ein sogenanntes Public-Key-Verfahren verwendet. Hierbei gibt ein Rechner einen öffentlichen Schlüssel aus, mit dem jeder Nachrichten an diesen verschlüsseln kann. Allerdings hat nur der Rechner selbst den geheimen privaten Schlüssel, mit dem die Nachricht auch wieder entschlüsselt werden kann. Auf diese Weise kann man ein Geheimnis an jemanden übermitteln, mit dem dann nur dieser etwas anfangen kann.
Im Falle des HTTPS-Protokolls wird der öffentliche Schlüssel des Webservers genutzt, um die Daten zu verschlüsseln, die dann nur der Webserver entschlüsseln kann.
Der Ablauf ist in folgender Grafik illustriert.
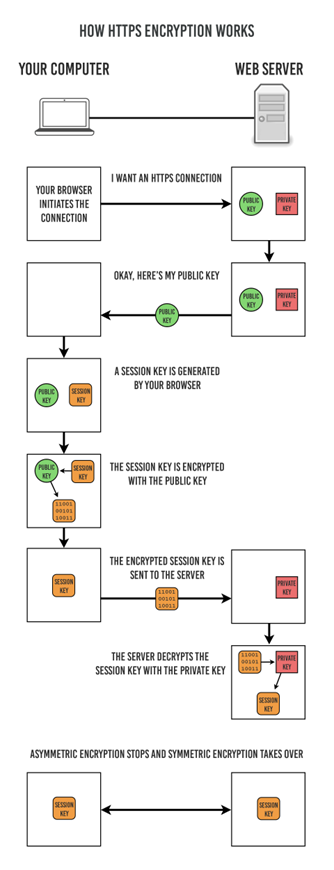
ABER …
Aber wie stellen wir sicher, dass wir überhaupt mit dem richtigen Webserver kommunizieren? Hierzu gibt es sogenannte Zertifikate, die von Zertifizierungsstellen (Certification Authorities, CAs) ausgestellt werden. Diese Zertifikate enthalten den öffentlichen Schlüssel des Webservers und sind von der Zertifizierungsstelle signiert. Das bedeutet, dass die Zertifizierungsstelle bestätigt, dass der öffentliche Schlüssel tatsächlich zum Webserver gehört. Die Zertifikate werden von den Webbrowsern genutzt, um die Identität des Webservers zu überprüfen. Da die Zertifikate zeitlich begrenzt sind, müssen sie regelmäßig erneuert werden.
Wer sieht was?
Trotz Verschlüsselung können alle beteiligten Computer die Metadaten der Datenpakete lesen. Diese Metadaten enthalten Informationen über den Absender, den Empfänger, die Größe des Datenpakets, den Zeitpunkt des Versands, … Dies umfasst u.a. auch die Adresse (URL/IP) der Zielwebseite.
Somit kann z.B. der lokale Router (Portier) sehen, welche Webseiten besucht wurden. Jeder der Zugriff auf diesen (also z.B. ihre lokale FritzBox oder dergleichen) hat (entweder von aussen oder direkt von innerhalb ihres lokalen Netzwerkes), kann diese Metadaten einsehen.
Metadaten Kommunikation
Denken sie kurz über die folgende Frage nach:
Was könnte man aus der Historie ihrer besuchten Webseiten etc. ablesen?
- Was ist ihre Bank?
- Wo kaufen sie ein?
- Welche Nachrichtenseiten lesen sie?
- …
Diese Informationen werden z.T. auch in Logfiles im Router gespeichert.
Auch der Internet Service Provider (ISP) kann sehen, welche Webseiten besucht wurden, welche Apps genutzt wurden, … Dieser ist sogar, aufgrund der Vorratsdatenspeicherung, verpflichtet, diese Daten für eine bestimmte Zeit zu speichern, um diese ggf. zur Aufklärung von Straftaten zur Verfügung zu stellen. Wenn also jemand Zugriff auf diese Daten erhält, kann er ein ziemlich genaues Bild über ihre Aktivitäten im Internet erstellen.
Das gleiche gilt auch für frei verfügbare WLAN-Anbieter (Cafe, Bahnhof, …), die die Datenpakete ihrer Nutzer mitlesen können.
Auch der Webserver, mit dem sie kommunizieren, kann die Metadaten der Datenpakete sehen und auswerten. Und wenn sie sich auf einer Webseite registrieren und eingeloggt sind, dann kann der Webseitenbetreiber auch noch weitere Informationen über sie sammeln.
VPN
Eine VPN-Verbindung (Virtual Private Network) kann helfen, ihre Daten vor neugierigen Blicken zu schützen. Hierbei wird eine verschlüsselte Verbindung zu einem VPN-Server aufgebaut, der dann die Datenpakete weiterleitet.
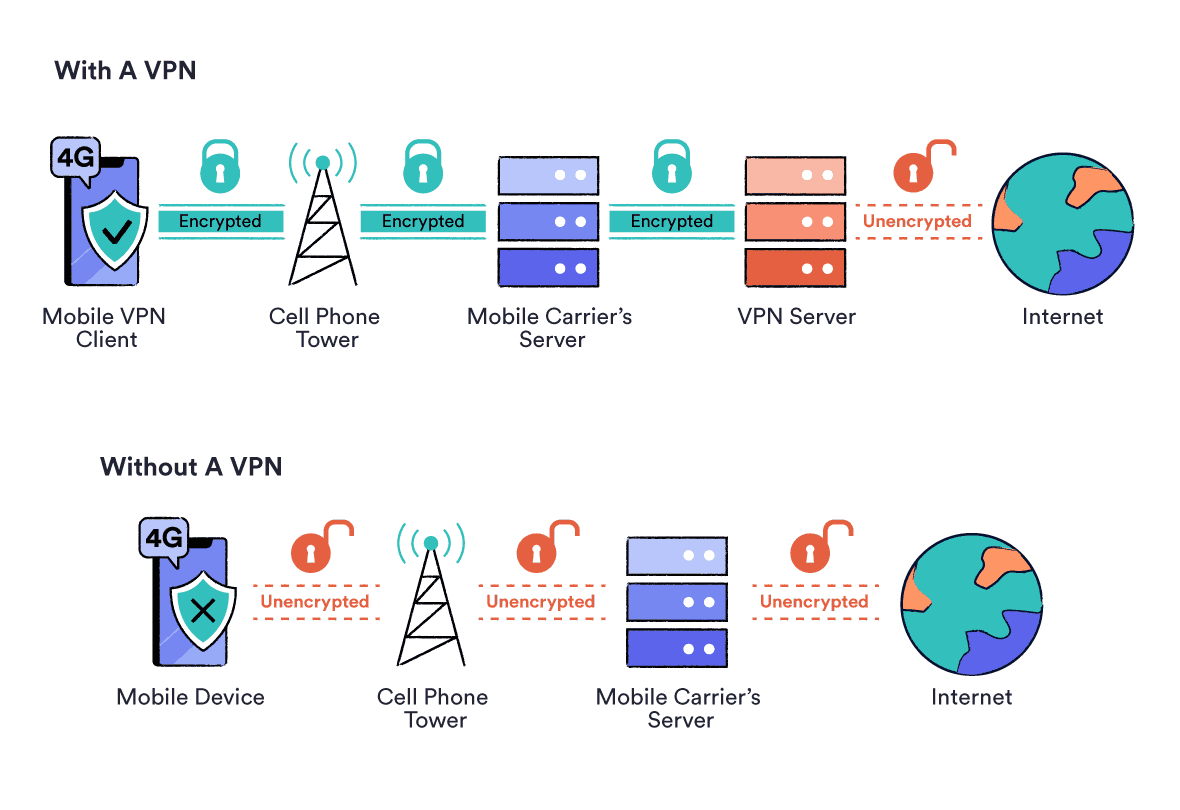
Der Datenverkehr zwischen ihrem Computer und dem VPN-Server ist verschlüsselt, so dass niemand die Datenpakete lesen kann. Erst der VPN-Server entschlüsselt die Datenpakete und stellt die Verbindung zum Zielserver her. Dadurch kann der Zielserver nur die IP-Adresse des VPN-Servers sehen, nicht aber ihre eigene IP-Adresse. Der VPN-Server kann zwar die Metadaten der Datenpakete sehen, aber er kennt nicht den Inhalt der Datenpakete, wenn diese (z.B. via HTTPS) verschlüsselt sind.
Somit können lokale Router, ISPs, WLAN-Anbieter, … nicht mehr sehen, welche Webseiten besucht werden.
ABER …
Aber der VPN-Anbieter kann die Metadaten der Datenpakete sehen und auswertenm, da er diese ja für sie weiterleitet und entgegennimmt. Auch der Internetprovider des VPN-Anbieters kann die Metadaten der Datenpakete sehen und auswerten, auch wenn diesem die Zuordnung zu ihnen nicht bekannt ist.
VPN schützt also vor lokalen Schnüfflern, aber nicht vor dem VPN-Anbieter und dessen Internetprovider. Somit sollten sie sich gut überlegen, welchem VPN-Anbieter sie vertrauen.
Ein weiterer Nachteil von VPN ist, dass die Datenpakete über den VPN-Server geleitet werden, was zu einer Verlangsamung der Verbindung führen kann. Allerdings bieten VPN-Anbieter auch Server in verschiedenen Ländern an, so dass sie z.B. über eine IP-Adresse aus einem anderen Land (die des VPN Servers) mit dem Internet kommunizieren, um z.B. Geoblocking oder lokalisierte Werbung zu umgehen.
DNS
Soweit haben wir uns nur mit der Kommunikation zwischen ihrem
Computer und dem Webserver beschäftigt, welche auf der Adressierung über
IP-Adressen basiert. Allerdings werden IP-Adressen i.d.R. nur bei
automatisierten Prozessen verwendet und direkt eingegeben. Wenn sie eine
Webseite besuchen, dann geben sie zumeist den Namen einer Webseite ein
(z.B. www.uni-tuebingen.de) und nicht die IP-Adresse des
dazu gehörigen Webservers.
Die Übersetzung von Namen in IP-Adressen wird über das Domain Name System (DNS) realisiert. Hierfür gibt es spezielle DNS-Server, die die Namen in IP-Adressen übersetzen. Sprich bevor ihr Computer eine Anfrage an den Webserver sendet, fragt er zuerst einen DNS-Server nach der IP-Adresse des Webservers.
In den meisten Fällen wird der DNS-Server von ihrem Internetprovider genutzt. Hier eine mögliche Liste von deutschen DNS Servern. Falls sie eine VPN-Verbindung nutzen, dann erfolgt die DNS-Anfrage über den VPN-Server (bzw. wird von diesem zu dessen DNS-Server weitergeleitet). In beiden Fällen kann der DNS-Server sehen, welche Webseiten besucht werden, da er ja die Anfragen nach den IP-Adressen der Webserver erhält.
Zudem kann auch eine Zensur durch DNS-Server erfolgen, indem der DNS-Server die Anfrage nach bestimmten Webseiten verweigert und ihnen keine oder eine andere IP-Adresse zurückliefert.. Allerdings können sie auch manuell einen anderen DNS-Server einstellen, um z.B. derartige Einschränkungen zu umgehen. Allerdings sollten sie sich auch hier gut überlegen, welchem DNS-Server (Anbieter) sie vertrauen.
URL
Der “Name” einer Webseite wird in mittels einer URL (Uniform Resource Locator) angegeben. Die URL besteht aus mehreren Teilen, die die Adresse des Webservers und den Pfad zur gewünschten Ressource (Webseite, Bild, …) beschreiben. Hier als Beispiel die URL der Login-Seite für den ILIAS Server der Universität Tübingen:
TXT
Markierung
Protokollende Serverende Zielende Argumenttrenner
||| | | |
https://ovidius.uni-tuebingen.de/ilias3/login.php?lang=en&cmd=force_login
| | | | |
| | | | +--- Argumente (&-getrennte key-value Paare)
| | | | hier: Sprache der Webseite & erzwungener Login
| | | +--- Name der Ressource (i.d.R. Datei auf dem Webserver)
| | | hier: dynamische Webseite
| | +--- Pfad zur Ressource
| | = virtuelle Ordnerstruktur
| +--- Name des Webservers (oder IP-Adresse)
| hierfür muss IP-Adresse über DNS aufgelöst werden
+--- Übertragungsprotokoll
hier: "verschlüsselte Webseite"
Die URL wird in der Regel in der Adresszeile des Browsers angezeigt und kann auch manuell eingegeben werden. So kann man bereits durch einen kurzen Blick auf die URL einiges erkennen, z.B.
- ob die Verbindung verschlüsselt ist (hier durch das
https://). - ob die Webseite überhaupt auf einem Server der gewünschten
Organisation liegt (hier
uni-tuebingen.de). Der Name des Webservers ist i.d.R. rückwärts zu lesen, d.h. von der allgemeinen Domain (hieruni-tuebingen.de) zum spezifischen Server (hierovidius). Das heißt, dass der Webserverovidiuszu den Servern der Domäneuni-tuebingen.degehört. Hierdurch lassen sich auch Subdomains (z.B.www.uni-tuebingen.deist der Webserver) und spezielle Dienste (z.B.ovidius.uni-tuebingen.deals Name für den ILIAS Server) unterscheiden. Es sollte darauf geachtet werden, dass die URL auch wirklich zur gewünschten Organisation gehört, da es z.B. Phishing-Seiten gibt, die im Link zwar den Namen einer bekannten Organisation verwenden, um Nutzer zu täuschen, aber auf einen anderen Server verweisen (Beispiel kommt gleich). - Durch Argumente in der URL können z.B. Parameter an die Webseite übergeben werden, die dann in der Darstellung oder Funktionalität der Webseite berücksichtigt werden. In obigem Beispiel wird die Sprache der Webseite auf Englisch gesetzt und ein erzwungener Login durchgeführt. Online-Shops, wie z.B. Amazon, verwenden die Argumente in der URL, um unabhängig von Cookies etc. die Session des Benutzers zu identifizieren und den Warenkorb zu speichern.
Der Name der Resource (hier login.php) sowie die
Webseitenargumente (hier lang=en&cmd=force_login) sind
bei vielen Webanfragen optional und werden i.d.R. vom Webserver
interpretiert. Das heisst der Webserver entschiedet, welche
(Standard)Ressource zurückgegeben wird und wie die Argumente verarbeitet
werden. So führt z.B. die Teil-URL
https://ovidius.uni-tuebingen.de/ilias3/ zur gleichen
Resource wie das obige Beispiel.
Link-Check vor jedem Klick
Bevor sie auf URLs klicken (in Webseiten, Suchmaschinen, Emails,
Messenger, PDF, ..), sollten sie sich immer kurz die URL ansehen und
überlegen, ob sie wirklich auf die gewünschte Webseite führt. Hierbei
ist vor allem der hintere Teil des Servernames (z.B.
uni-tuebingen.de) wichtig, da dieser den Server
identifiziert. Der vordere Teil kann vom Serveradministrator beliebig
gesetzt werden und wird oft für Phishing-Attacken missbraucht. Ein
mögliches Phishing-Beispiel wäre z.B.
TXT
| beliebig setzbar! | | Servername |
https://ovidius.uni-tuebingen.de.phishing-server.com/ilias3/wobei hier der Servername phishing-server.com ist und
nicht uni-tuebingen.de.
So ein Check geht schnell und verhindert schon einen Großteil möglicher Phishing-Attacken.
Das ist wie am Fussgängerüberweg: Auch wenn sie Vorrang haben, schauen sie kurz nach links und rechts, ob wirklich alle anhalten.
Zusammenfassung
- Jeder Computer ist über seine IP-Adresse (im Internet) identifizierbar.
- Zertifikate bestätigen die Identität von Webservern.
- Zu versendende Daten werden in Pakete aufgeteilt (z.B. via TCP) und über das Internetprotokoll (IP) verschickt.
- Datenpakete zwischen Computern werden “von Knoten zu Knoten” weitergeleitet.
- Datenpakete können von lokalen Routern, ISPs, WLAN-Anbietern, … eingesehen werden.
- HTTPS verschlüsselt den gesendeten Inhalt der Datenpakete (Metadaten wie Ziel-IP etc. nicht).
- VPN schützt vor lokalen Schnüfflern, aber nicht vor dem VPN-Anbieter.
- URLs beschreiben das Zieldokument inklusive des Namens des Webservers etc.
- Webservernamen werden durch DNS-Server in IP-Adressen aufgelöst
Einordnung im Datenlebenszyklus
Das Wissen um Netzwerkkommunikation und Verschlüsselung ist in allen Phasen des Datenlebenszyklus wichtig. Kenntnisse darum erleichtern uns, Probleme und Ursachen zu erkennen und zu lösen, die im Zusammenhang mit der Kommunikation von Daten auftreten können.
Immer dann, wenn wir auf fremde Rechner zugreifen oder mit diesen interagieren, sollte uns bewusst sein, dass wir dabei Spuren hinterlassen und dass diese Spuren auch von anderen eingesehen werden können.